Modelos Sequence-to-sequence (ou Seq2seq) e o mecanismo de Atenção (Attention Mechanism) não são conceitos novos, mas são a base dos modelos mais avançados de linguagem que conhecemos hoje, e permitem o treino de Foundation Models como os famosos LLMs (Large Language Models) da família GPT.
O Jay Alammar, especialista em Processamento de Linguagem Natural (ou NLP, Natural Language Processing), escreveu alguns artigos super didáticos no seu blog (https://jalammar.github.io/). Com a sua autorização, estamos trazendo alguns deles para o BRAINS, em Português.
O primeiro artigo que iremos traduzir se chama: Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention). Todo o conteúdo a partir deste ponto é uma tradução livre e autorizada do conteúdo do Jay, incluindo as imagens e animações.
Obs: Todo o texto abaixo foi traduzido do conteúdo original, exceto as notas de tradução explicitadas.
Introdução
Os modelos Sequence-to-Sequence são modelos de Deep Learning que conquistaram muito sucesso em tarefas como tradução de máquina, sumarização de textos e geração de legendas para imagens. O Google Translate começou a usar um modelo deste tipo no final de 2016. Estes modelos são explicados em dois artigos pioneiros (Sutskever et al., 2014 e Cho et al., 2014).
Eu descobri, entretanto, que entender esses modelos bem o suficiente para implementá-los requer desvendar uma série de conceitos que se constroem uns sobre os outros. Eu achei que boa parte dessas ideias seriam mais acessíveis se expressadas visualmente. Este é o objetivo deste post. Você vai precisar de algum entendimento prévio sobre Deep Learning para compreender este post. Espero que ele possa ser um companheiro útil para a leitura dos artigos mencionados acima (e dos artigos sobre Atenção listados posteriormente aqui).
Um modelo Sequence-to-Sequence é um modelo que recebe como entrada uma sequência de itens (palavras, letras, características de uma imagem, etc) e entrega na saída uma outra sequência de itens. Um modelo treinado trabalharia desta forma:
Em tarefas de tradução neural de máquina (Neural Machine Translation), a sequência de entrada é uma série de palavras, processadas uma após a outra. A saída é, da mesma forma, uma série de palavras.
Olhando debaixo do capô
Por baixo do capô, o modelo é composto por um Encoder (Codificador) e um Decoder (Decodificador).
Encoder processa cada item na sequência de entrada, compila a informação que ele captura em um vetor, chamado de Contexto (ou Context). Depois de processar toda a sequência de entrada, o Encoder envia o Contexto para o Decoder, que começa a produzir a saída item por item.
O mesmo processo se aplica no caso de tradução de máquina.
Contexto é um vetor (um array de números, basicamente) no caso de tradução de máquina. O Encoder e o Decoder tendem a ser, ambos, Redes Neurais Recorrentes (ou RNNs, Recurrent Neural Networks).
Assista ao vídeo A friendly introduction to Recurrent Neural Networks para uma introdução sobre as RNNs.
Luis Serrano, Udacity

Nós podemos escolher o tamanho do vetor de Contexto quando configuramos nosso modelo. O tamanho do vetor é basicamente o número de unidades ocultas (Hidden Units) no Encoder da Rede Neural Recorrente (RNN). Estas visualizações mostram um vetor de tamanho 4, mas em aplicações do mundo real o vetor de Contexto seria de tamanhos como 256, 512, ou 1024, por exemplo.
Por padrão, a RNN recebe duas entradas a cada passo de tempo: uma entrada (no caso do encoder, uma palavra da frase de entrada) e um Estado Oculto (Hidden State). A palavra, entretanto, precisa ser representada por um vetor. Para transformar uma palavra em um vetor, recorremos à classe de métodos chamados algoritmos de Word Embedding. Esses métodos transformam palavras em espaços vetoriais que capturam grande parte do significado/informação semântica das palavras (rei – homem + mulher = rainha).
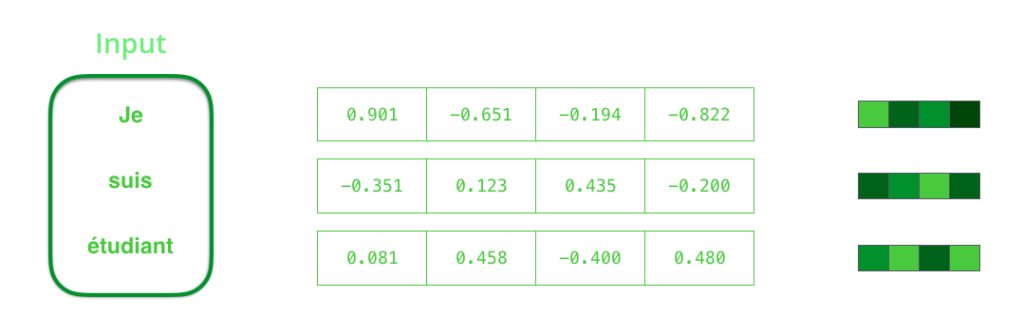
Agora que nós introduzimos nossos principais vetores/tensores, vamos recapitular os mecanismos de uma RNN e estabelecer uma linguagem visual para descrever estes modelos.
Redes Neurais Recorrentes (RNNs)
O próximo passo da RNN utiliza o segundo vetor de entrada e o Hidden State #1 (Estado Oculto #1) para criar a saída desse passo de tempo. Mais à frente nesse post, nós vamos usar uma animação como esta para descrever os vetores dentro de um modelo de tradução neural de máquina.
Na visualização a seguir, cada pulso para o Encoder ou Decoder é a RNN processando suas entradas e gerando uma saída para cada passo de tempo. Dado que o Encoder e o Decoder são ambos RNNs, cada passo das RNNs faz o mesmo processamento, e atualiza o seu Hidden State baseado nas suas entradas e nas entradas anteriores que já foram observadas.
Vamos analisar os Hidden States do Encoder. Observe como o último Hidden State é, na verdade, o Contexto que passamos para o Decoder.
O Decoder também mantém um Hidden State que passa de um passo de tempo para o próximo. Nós apenas não visualizamos isso nesta animação porque estamos preocupados com as partes maiores e principais do modelo por enquanto.
Vamos agora olhar para uma outra forma de visualizar os modelos Sequence-to-Sequence. Essa animação vai fazer ser mais fácil de entender as imagens estáticas que descrevem estes modelos. Isso é chamado de visualização “desenrolada” (“unrolled”), em que, em vez de mostrar apenas um Decoder, mostramos uma cópia dele para cada passo de tempo. Desta forma, podemos observar as entradas e saídas de cada passo de tempo.
Agora vamos prestar Atenção
O vetor de Contexto acabou se tornando um gargalo para esse tipo de modelos. Ele fez com que fosse desafiador para os modelos lidarem com frases longas. Uma solução foi proposta em Bahdanau et al., 2014 e Luong et al., 2015. Estes artigos apresentaram e refinaram uma técnica chamada de Atenção (Attention), que melhorou muito a qualidade de sistemas de tradução de máquina. Atenção permite que os modelos foquem nas partes relevantes da frase de entrada conforme necessário.
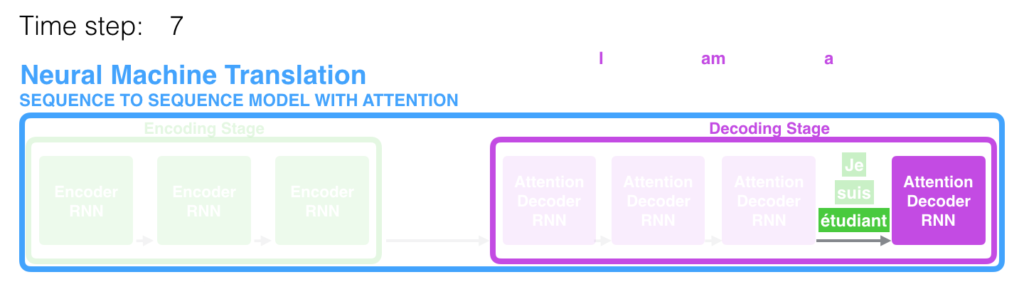
Vamos continuar olhando para os modelos de Atenção neste alto nível de abstração. Um modelo de Atenção diferencia de um modelo Sequence-to-Sequence clássico de duas formas principais.
Primeiro, o Encoder passa muito mais dados para o Decoder. Ao invés de passar o último Hidden State do estágio de codificação (de encoding), o Encoder passa todos os Hidden States para o Decoder.
Segundo, um Decoder com Atenção realiza uma etapa adicional antes de produzir a saída. Para focar nas partes da entrada que são relevantes no momento da decodificação, o Decoder faz o seguinte:
- Observa o conjunto de Hidden States do Encoder que recebeu – cada Hidden State do Encoder está mais associado a uma certa palavra da frase de entrada.
- Atribui a cada Hidden State uma pontuação, ou score (vamos ignorar como o cálculo das pontuações é feito por enquanto).
- Multiplica cada Hidden State pela sua pontuação após passar por uma função Softmax, amplificando assim os Hidden States com pontuações altas e atenuando os Hidden States com pontuações baixas.
Este exercício de pontuação é feito a cada passo de tempo no lado do Decoder.
Vamos agora juntar tudo na visualização a seguir e observar como o processo de Atenção funciona.
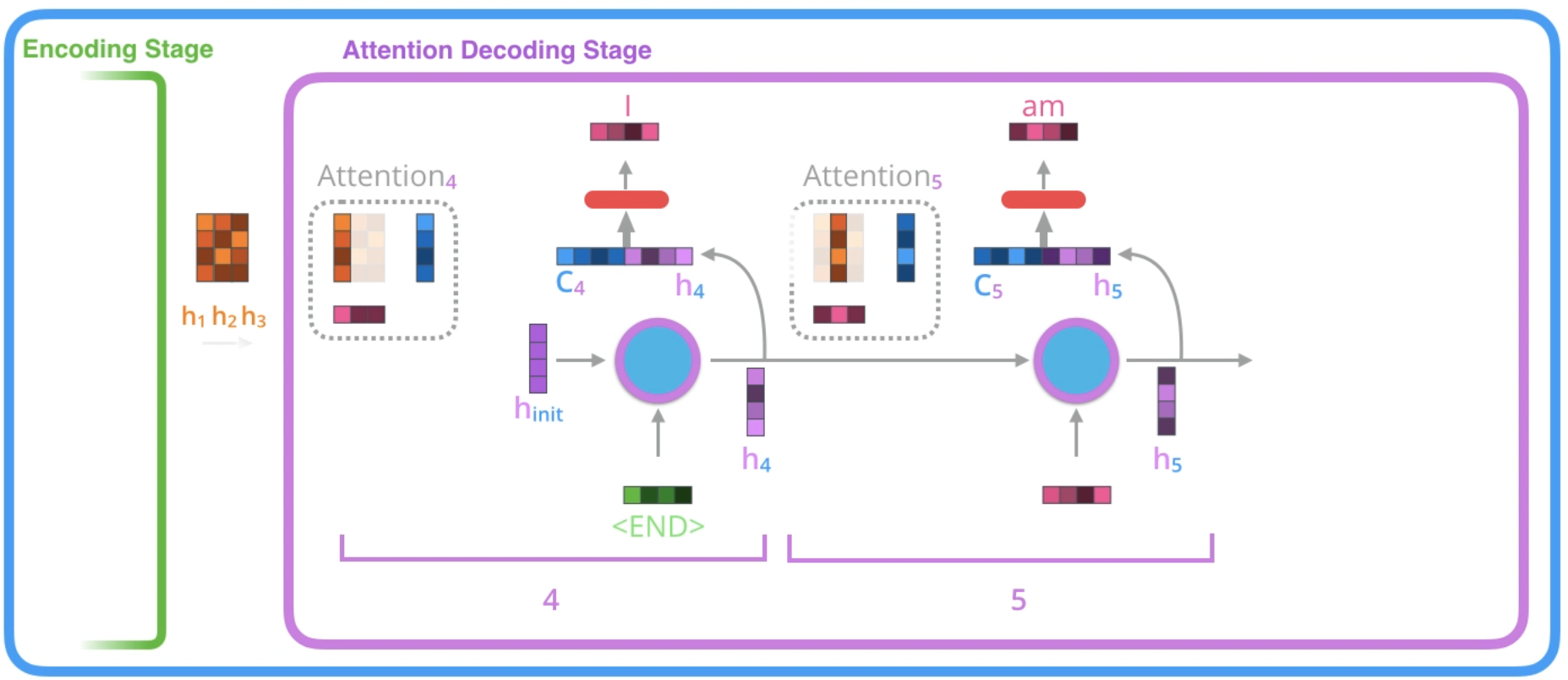
- A RNN do Decoder com Atenção recebe o embedding do token <END> e o Hidden State inicial do Decoder.
- A RNN processa a sua entrada, produzindo uma saída e um novo vetor de Hidden State (h4). A saída é descartada.
- Etapa da Atenção: nós usamos os Hidden States do Encoder e o vetor h4 para calcular o próximo vetor de Contexto (C4) para este passo de tempo.
- Nós concatenamos h4 e C4 em um único vetor.
- Nós passamos este vetor em uma Feedforward Neural Network (“Rede Neural de Alimentação Direta”), treinada em conjunto com o modelo.
- A saída da indica a palavra de saída deste passo de tempo.
- Repetir para os próximos passos.
Esta é outra forma de observar qual parte da frase de entrada estamos prestando atenção em cada passo de decodificação.
Observe que o modelo não está apenas alinhando automaticamente a primeira palavra da saída com a primeira palavra da entrada. Ele realmente aprendeu durante a fase de treinamento como alinhar palavras nos dois idiomas (Francês e Inglês no nosso exemplo). Um exemplo do quão preciso esse mecanismo pode ser vem dos artigos sobre Atenção listados acima.

Se você se sentir pronto para aprender a implementação destes conceitos em código, veja o tutorial do TensorFlow Neural Machine Translation (seq2seq) tutorial.
Conclusão
Espero que este post tenha sido útil. Essas animações são uma iteração prévia da aula sobre Atenção que é parte do programa do Udacity Natural Language Processing Nanodegree Program. Nós vamos em mais detalhes nesta aula, incluindo discussões das aplicações e tocando em métodos mais recentes de Atenção, como a arquitetura de Transformers do artigo Attention Is All You Need.
Veja o trailer do programa de Nanodegree em NLP:
O Jay também criou algumas aulas parte do Machine Learning Nanodegree Program da Udacity. As aulas cobrem o Aprendizado Não-Supervisionado (Unsupervised Learning). Trazem também um Jupyter Notebook sobre recomendações de filmes usando a filtragem colaborativa.
Jay diz que adoraria receber qualquer feedback que você possa ter. Por favor, entre em contato com ele pelo @JayAlammmar.
Fonte
Como dito no início do post, o conteúdo original está disponível no blog do Jay Alammar (https://jalammar.github.io/), em um post com o título Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention).
Esperamos que você tenha gostado do conteúdo. Pretendemos trazer mais posts do Jay e sobre NLP e LLMs. O mecanismo de Atenção e a arquitetura de Transformers revolucionaram como processamos texto. Estes temas têm sido meu foco de estudos atualmente e pretendo escrever mais sobre isso. Vamos aos poucos mergulhar mais fundo no mundo dos Foundation Models e da IA Generativa.
Caso tenha ficado com alguma dúvida, entre em contato com a gente. Se conhecer outros conteúdos bons como este, nos indique para tradução. Ou colabore traduzindo você mesmo. Será um prazer receber conteúdo de vocês aqui no BRAINS.
Gostaria de saber também se vocês têm preferência por assuntos mais avançados daqui pra frente. Ou se devemos focar em explicar melhor os conceitos mais básicos antes de prosseguir. Deixe sua opinião nos comentários.
Para conhecer mais sobre nossa comunidade e entender como colaborar, leia nosso post de introdução do BRAINS – Brazilian AI Networks. Contamos com você para crescer nossa comunidade. Até porque…

3 comentários
Excelente material parabéns ao autor e ao time do BRAINS
Krl muito foda