Uma cultura que mostra sua força conforme os produtos de Ciência de Dados provam seu valor no mercado. MLOps é uma sigla para Machine Learning Operations, ou Operações de Aprendizado de Máquina. E remete ao conjunto de práticas que automatizam o fluxo de trabalho de produtos de Machine Learning, otimizando sua manutenção e implementação. Em outras palavras, é utilizado para automatizar e padronizar processos em todo o ciclo de vida do produto de Machine Learning (ML).
Por que a cultura de MLOps?
Imagine uma empresa de vendas de placas fotovoltaicas. Você é o principal Cientista de Dados dessa empresa. E é sua responsabilidade desenvolver um modelo preditivo para estimar a quantidade de placas fotovoltaicas necessárias para determinada região. E você vai usar como base para isso, a irradiância solar. Você passou meses com o time comercial e técnico, a fim de entender as características e chegou no estado da arte para o modelo.
Mas e agora, o que fazer com o modelo? Como colocá-lo em produção?
MLOps surge para responder essa dúvida. E garantir que seu modelo será “produtizado” de forma rápida, eficaz e dentro dos padrões estabelecidos pela empresa.
Em um artigo muito influente, originalmente intitulado Hidden Technical Debt in Machine Learning Systems (Aprendizado de máquina: o cartão de crédito com juros altos da dívida técnica), Sculley e outros engenheiros do Google discutem sobre dívida técnica e aplicações de ML.
“Dívidas técnicas” são ações que proporcionam benefícios de curto prazo. Mas que possuem o custo de menor produtividade, necessidade de retrabalho ou custos operacionais no longo prazo. Podendo se acumular e sufocar um projeto. No artigo, os autores demonstram razões pelas quais os projetos de ML geram custos de manutenção adicionais, além dos projetos de software tradicionais que facilmente chegam à dívida técnica.
Dessa forma, uma definição de MLOps pode ser resumida. No esforço para evitar “dívidas técnicas” em aplicações de aprendizado de máquina, utilizando uma extensão da metodologia DevOps.
MLOps vs DevOps
Você já deve ter ouvido falar do bom e velho DevOps. Processo para desenvolver sistemas de software em larga escala. Visa encurtar os ciclos de desenvolvimento, aumentar a velocidade de implementação e construir versões confiáveis. Você pode estar se perguntando como o MLOps é diferente.
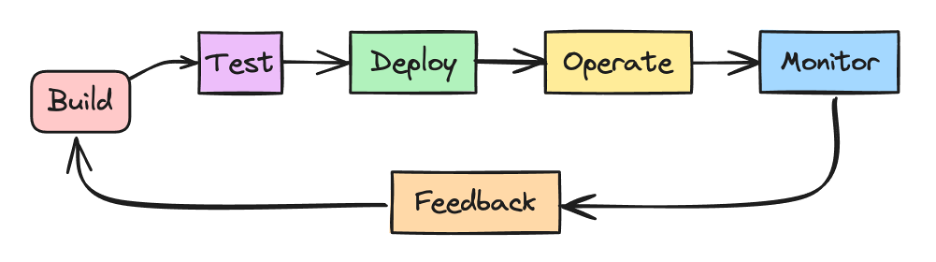
Podemos pensar que um sistema de ML é um sistema de software. Ou seja, podemos aplicar práticas semelhantes para criar e operar sistemas de ML em larga escala e de maneira confiável.
No entanto, o pipeline de desenvolvimento de ML possui um ciclo de vida diferente. Composto pelas seguintes etapas:
- Design;
- Experimentação e Desenvolvimento de Modelo; e
- Operações.
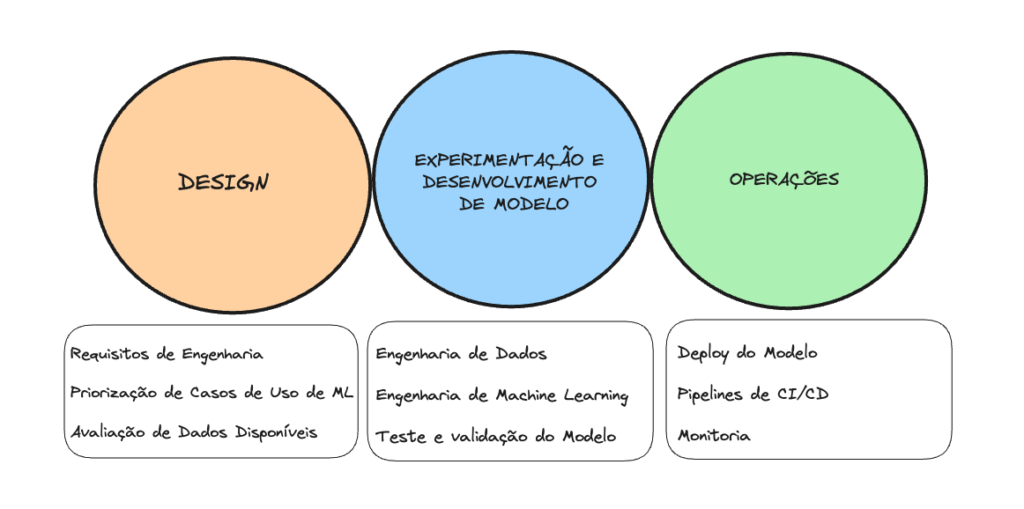
Na etapa de Design, nós levantamos todos os requisitos de engenharia, priorizamos os casos de uso de Machine Learning e avaliamos as amostras de dados disponíveis. Em Experimentação e Desenvolvimento de Modelo começamos a construir a Engenharia de Dados para alimentar o nosso modelo, a Engenharia de Machine Learning para treino e realizamos testes e validação dos modelos sendo treinados. Por fim, em Operações, fazemos o deploy do modelo em produção, por meio dos Pipelines de CI/CD e monitoramos o comportamento do nosso modelo.
Entendendo o MLOps
A primeira fase, o Design, é destinada a compreensão do negócio, dos dados e design do software baseado em ML. É nessa etapa em que o Cientista de Dados procura alinhar com o time de negócios quais as necessidades e problemas enfrentados. Isto é, mergulhar no negócio e extrair qual seria a melhor forma de ajudá-lo a partir dos dados. Existem duas categorias de problemas que abrangem a maioria dos problemas: aumento de produtividade e aumento da interatividade da aplicação. Outro ponto importante desta etapa é avaliar os dados necessários para treinar o modelo. E especificar os requisitos funcionais e não funcionais do nosso modelo.
A fase de Experimentação e Desenvolvimento é o momento de aplicar testes e provas de conceitos para o modelo de ML. Aqui, é onde aplicamos Feature Engineering, testamos diversos algoritmos, realizamos o tune dos parâmetros. Tudo isso a fim de resultar em um modelo com qualidade estável para ser levado em produção. Nessa etapa, pode ser implementado frameworks de padronização de código, como o Kedro. Em breve devemos escrever mais sobre este Framework por aqui.
Por fim, a fase de Operações é a fase em que a mágica realmente acontece. O foco principal é entregar o modelo em produção. “Produtizar” o modelo é relativo e depende do contexto empresarial que estamos lidando. Pode ser acoplar ao SAP, CRM, a um Dashboard ou aplicativo final consumido pelo cliente. Para isso, utilizamos práticas DevOps, como: testes, controle de versão, CI/CD (Integração Contínua e Entrega Contínua) e monitoramento.
Níveis de Maturidade de MLOps
Cada empresa possui seu contexto e momento no uso de dados e aplicação de ML. Por isso, existem diversos níveis de maturidade que aplicam os princípios e conceitos de MLOps. O nível de automação das fases anteriores define a maturidade do processo de ML, que reflete a velocidade de implementação de novos modelos. A seguir, vamos explorar três níveis de MLOps a partir de um exemplo fictício.
Nível 0: Processo Manual
Vamos retomar ao exemplo do cientista de dados de uma empresa de vendas de placas fotovoltaicas. Imagine que o processo para criação e implementação de modelos de ML é feita de forma manual.
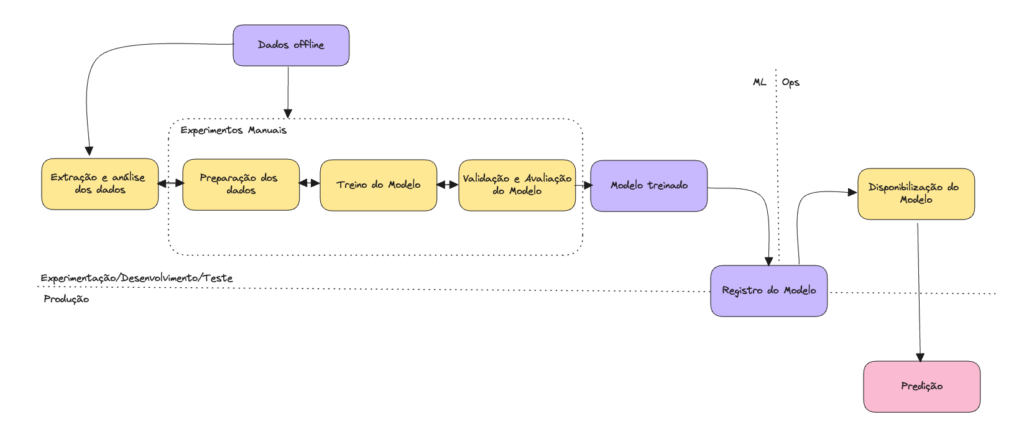
A Figura acima exemplifica como seria esse processo manual.
Podemos observar que todos os passos são manuais. Desde a análise de dados, preparação de dados, treinamento de modelo e validação. Geralmente, esse processo é impulsionado por código experimental e executado em notebooks pelo Cientista de Dados responsável.
É possível notar a desconexão entre ML e operações. Isto é, o papel do cientista não é integrado ao papel do engenheiro de aplicação. Dessa forma, produtizar pode se resumir a disponibilizar o modelo treinado em um local de armazenamento ou em um repositório de códigos. Essa desconexão pode gerar distorção entre o treinamento e a disponibilização, assim como a dificuldade de iterações das versões do modelo e da monitoria do desempenho ativo, uma vez que o processo não registra e não rastreia ações do modelo necessárias para detectar drift e desvios comportamentais dos dados.
E por último, esse nível de maturidade não há considerações de CI/CD (Integração Contínua e Entrega Contínua) para o modelo. Pois este cenário não trata do versionamento de código, dados ou modelo e o processo de implantação é manual.
Nível 1: Automação de Pipeline de ML
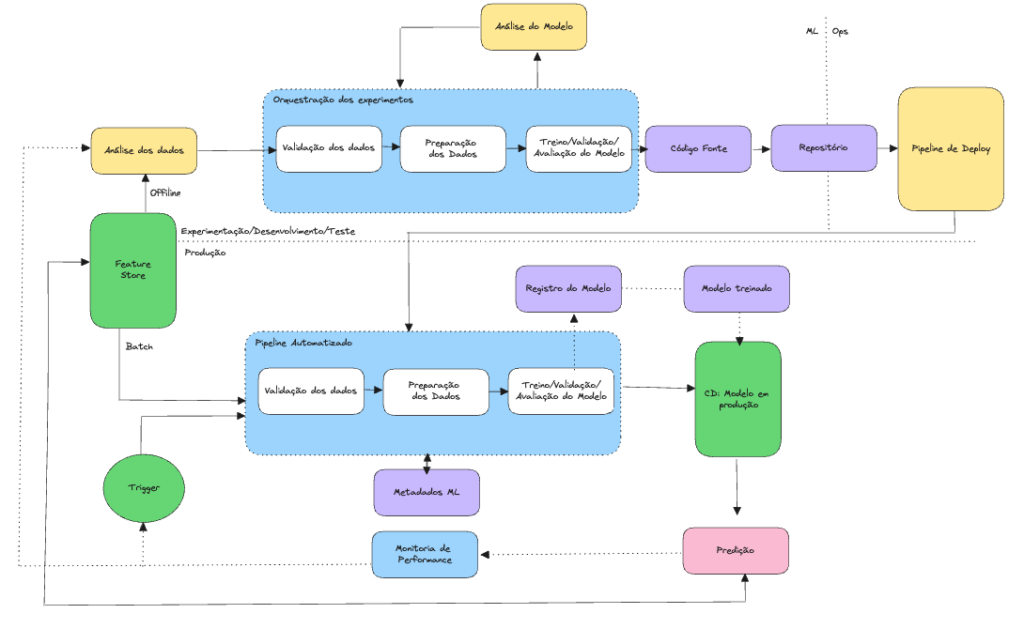
Esse estágio é marcado por empresas que já entenderam que os dados são valiosos. E que os modelos podem ajudar em diversos casos de uso e desejam investir na engenharia de ML, automatizando e melhorando o processo.
Nesse nível de maturidade, como mostra a figura acima, é possível ver que os passos de experimentação de ML são orquestrados. Ou seja, a transição entre os passos é automatizada, gerando agilidade e rapidez. Outra marca importante é a automatização. Isto é, percebemos que vários passos importantes são realizados de maneira automática, como o treinamento do modelo em produção com dados recentes. Além disso, podemos observar pipelines e componentes reutilizáveis, de forma que o código seja facilmente reproduzível entre os ambientes de desenvolvimento e produção, obtendo o versionamento necessário para os dados, códigos e modelos.
A presença de características importantes de CI/CD começam a surgir com a o re-treino do modelo automático e sua implantação automatizada por meio de um pipeline.
Portanto, se no nível 0 você implementa um modelo treinado como um serviço de previsão via uma API REST, no nível 1 você implementa o pipeline inteiro, o qual é executado de maneira automática e recorrente. Além disso, você pode gerenciar metadados, como informações sobre cada execução do pipeline e dados de reprodutibilidade.
Outro benefício importante desse nível de maturidade é a validação do modelo. Como agora temos um pipeline de re-treino automatizado, podemos avaliá-lo antes de promovê–lo para produção. Fazemos isso por meio da produção de métricas para medir a qualidade preditiva do modelo, comparando com métricas de treinos passados e, principalmente, a validação de teste A/B feita antes dos resultados do modelo entrar no tráfego online.
Nível 2: Automação de Pipeline de CI/CD
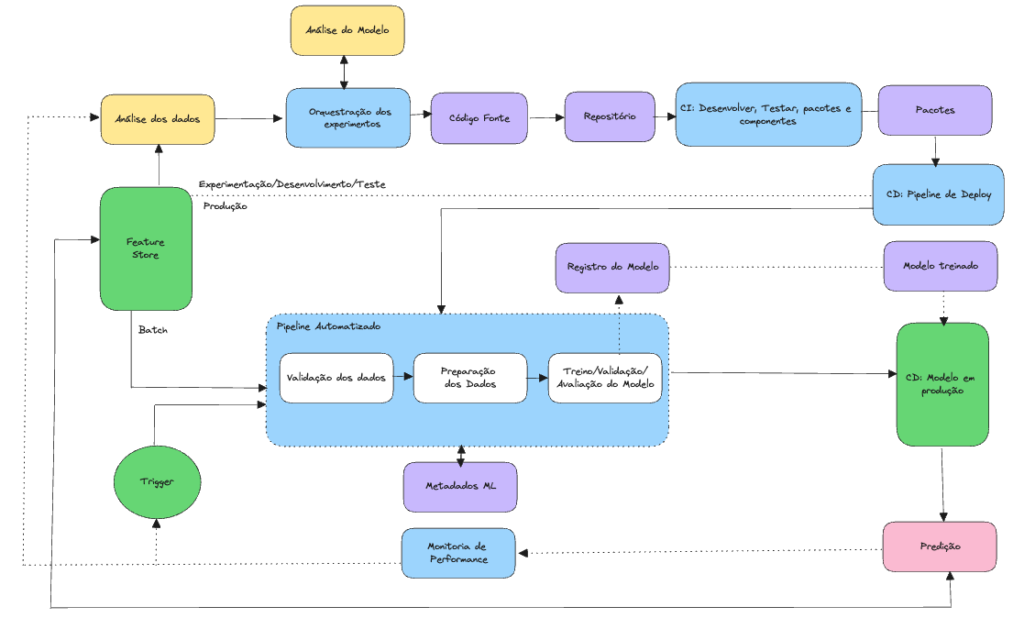
No estado da arte no que diz respeito ao nível de maturidade existente de MLOps hoje, atingimos uma atualização rápida e confiável dos pipelines em produção, implementando um sistema de CI/CD altamente automatizado. Que, por sua vez, permite que os cientistas explorem rapidamente novas ideais sobre features, arquiteturas de modelos e ajuste de hiperparâmetros. O diagrama a seguir mostra a implementação aplicando CI/CD.
De maneira geral, o pipeline consiste nos seguintes estágios:
- Desenvolvimento e experimentação: fase em que os cientistas podem usar e abusar da criatividade e conhecimento técnico para extrair o maior valor possível dos dados. A saída desse estágio consiste no modelo pronto para produção, em que seu código fonte do pipeline de ML é colocado em um repositório de origem.
- Integração contínua (CI): execução de variados testes, como por exemplo a execução de testes unitários. No fim desse estagio, temos os componentes de pipeline: pacotes, executáveis e artefatos.
- Entrega contínua (CD): Uma vez que os artefatos foram produzidos, nessa etapa o implementamos no ambiente de destino, com toda a automatização necessária implementada.
- Acionamento automatizado: programação da execução automática do pipeline em ambiente de produção ou em resposta a um evento acionador, gerando como saída desse estágio, um serviço de previsão de modelo implantado.
- Monitoria: coleta de estatísticas sobre desempenho do modelo com base nos dados utilizados para treinamento e dados gerados pelo modelo.
Conclusão
Implementar um modelo de Machine Learning em produção é muito mais que implantar o modelo com uma API para previsão. Para evitar débitos técnicos é necessário automatizar o treinamento e implantação de novos modelos. A configuração de um sistema de CI/CD é essencial para realizar testes, rapidez e robustez aos pipelines, assim como permite lidar com alterações de código e dados.
É importante ter em mente que não é necessário mover todos os processos de um nível de maturidade para outro, mas é importante ter em mente e procurar implementar gradualmente boas praticas para diminuir débitos técnicos, melhorar a automação e desenvolvimento de modelos de ML para que possamos extrair ao máximo seus benefícios.
Nós iremos nos aprofundar ainda mais em breve sobre MLOps. E entender como podemos construir, na prática, esses pipelines automatizados. Se você tiver interesse no tema, clique aqui para participar da nossa comunidade para discutirmos sobre o assunto! Se tiver dúvidas, sugestões, ou quiser debater o post, a Comunidade BRAINS também é o melhor lugar.
Estamos super ativos na comunidade e eu te espero por lá!