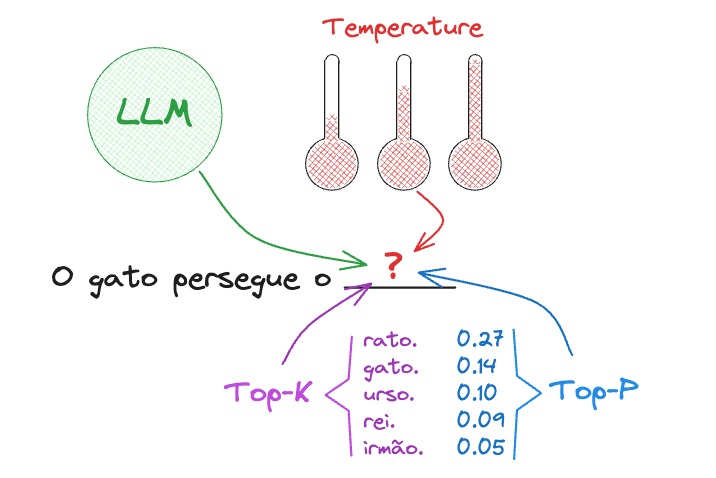
Você sabia que é possível configurar a qualidade, diversidade e criatividade dos textos gerados pelo Large Language Model (LLM) com o ajuste de alguns parâmetros? Entendê-los é essencial para alcançarmos saídas mais eficazes e alinhadas com nosso caso de uso.
Em mais um post super importante sobre nossos queridos Largue Language Models, hoje eu vou te ensinar a configurar o comportamento dele. Podemos configurar ele um pouco mais determinístico ou um pouco mais “criativo”.
Conseguimos mudar a forma como o LLM escolhe o próximo Token a ser exibido na saída. Se você não esta familiarizado com Tokens, camada final Linear e de Softmax da arquitetura baseada em Transformers… Recomendo a leitura do post Token e Embedding: conceitos da IA e LLMs e também do Os Transformers Ilustrados.
Sabemos que os LLM’s estão a todo momento tentando prever a palavra mais provável de aparecer no texto – ou tecnicamente falando do próximo Token. Com os parâmetros Temperatura, Top-K e Top-P podemos alterar a forma como o LLM escolhe o próximo Token a ser exibido. Além disso, podemos indicar quando parar esta geração (Sequência de Parada), limite máximo de Tokens gerados (Min – Max Tokens) e reduzir a repetição deles na saída (Penalidade de Repetição).
Recapitulando, camada final Linear e de Softmax
Na arquitetura baseada em transformers, após a pilha de Decoders é gerado um vetor de números decimais que é projetado em um vetor muito maior chamado de Logits. Neste vetor, cada célula da representa uma palavra (Token). Basicamente, este processo nos resulta na pontuação ou probabilidade de cada Token ser o próximo a ser gerado.
A camada Softmax, então, tem como objetivo normalizar os escores de probabilidade fazendo com que cada número esteja no intervalo de 0 a 1. Além disso, a soma de todas as probabilidades seja igual a 1.
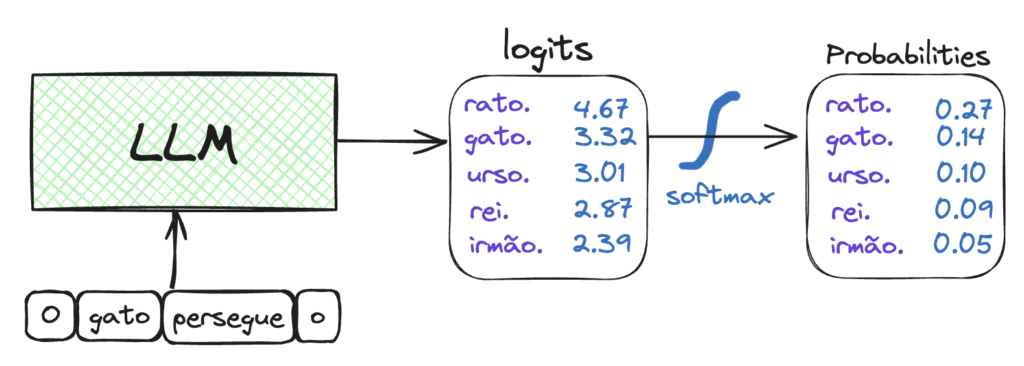
Se os parágrafos acima parecem estar em grego, irei simplificar. Temos um grande vetor onde cada célula esta relacionada a uma palavra. Nesta célula há a probabilidade daquela palavra ser a próxima a ser exibida na saída.
Parâmetros de Inferência
Exploraremos agora diferentes formas de alterar como o LLM gera próximo token e entender as características de cada saída de acordo com essas configurações.
Método Greedy
A maneira mais trivial de se pensar seria escolher o Token com maior probabilidade e exibi-lo. Esta forma de escolha é chamada de Método de Decodificação Greedy, porém não é o único.
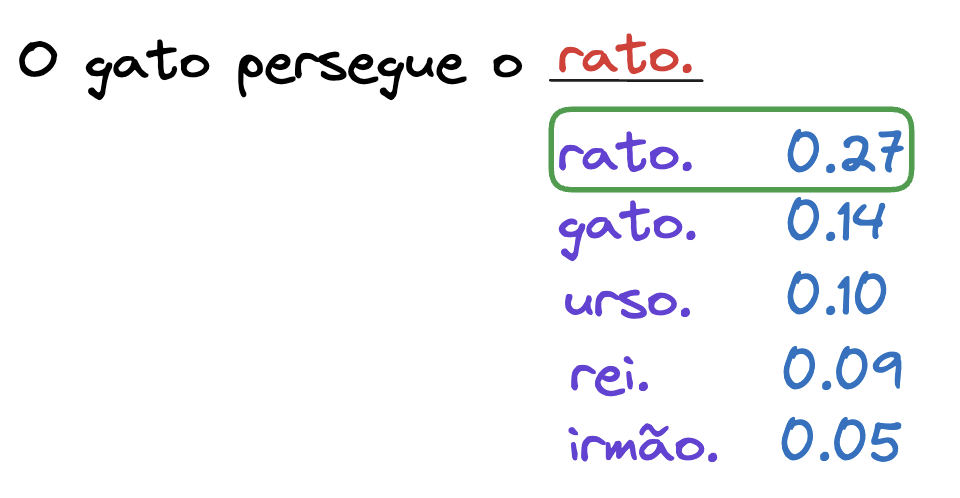
Este método é computacionalmente mais eficiente. Entretando, gera saídas repetitivas e determinísticas, podendo não considerar todo o contexto e não produzir uma resposta “criativa”.
Se o seu caso de uso exige uma saída mais exata, este método é uma boa opção. Porém, para casos de uso com necessidade de maior aleatoriedade na resposta – ou maior “criatividade – temos mais opções para você a seguir.
Método Sampling
Quando trabalhamos com método sampling incluímos a “aleatoriedade” na resposta e há diversas formas de controlá-la. Você pode escolher o K, mudar o valor do P e escolher a temperatura ideal para o LLM. Ficou meio confuso?! Aqui embaixo eu te explico.
Top-K
Ao invés de escolher o token com maior probabilidade, podemos fazer com que o LLM escolha aleatoriamente entre um número de Tokens. Ele escolhe entre os K primeiros tokens com maior probabilidade. Onde K é o número de Tokens.
Top-K é um dos parâmetros do método Sampling, onde escolhemos um número inteiro que chamamos de K. O LLM irá considerar os K tokens que possuem maior probabilidade.
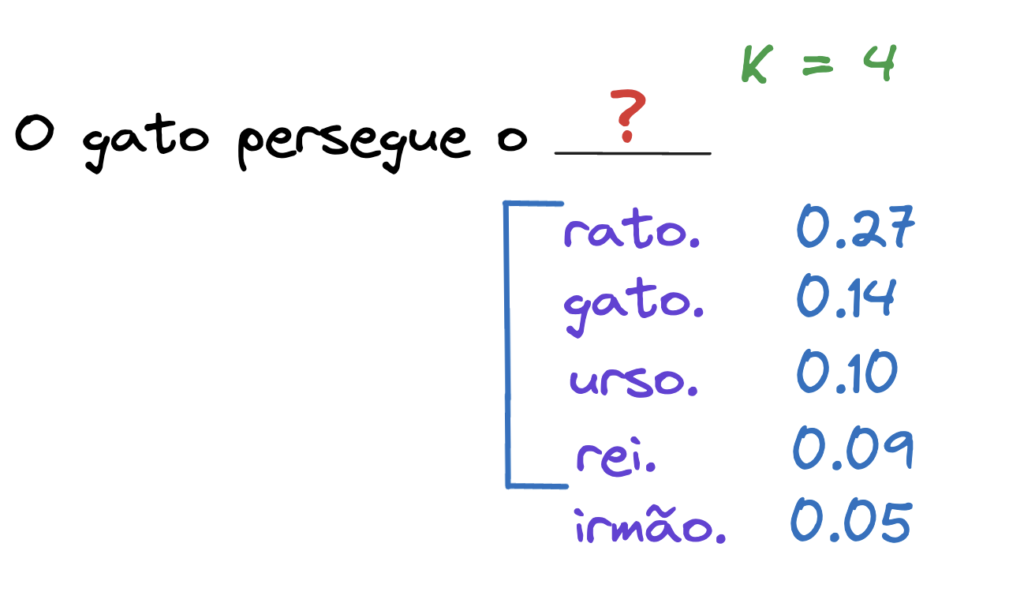
Com isso teremos respostas diversificadas, mas qual seria o K ideal?! Não há um número mágico, é importante entender que nível de “criatividade” é interessante para o caso de uso e realizar testes alterando este número.
No nosso exemplo, escolhemos K = 4. O LLM escolherá aleatoriamente entre as palavras rato, gato, urso e rei. Os 4 tokens mais prováveis. Isso faz com que nossa frase em alguns casos nem sempre seja completada com a palavra “rato”.
Top-P
O parâmetro Top-P é um pouco diferente. Nós escolhemos um número P no intervalo entre 0 e 1.0. Onde esse valor de P é nosso Threshold, ou seja, nosso limite. Mas limite do que?
Sabemos que cada token tem sua probabilidade de ser o próximo a ser exibido. O valor de P nada mais é que o limite que definimos da soma das probabilidades dos tokens a serem considerados pelo LLM.
É importante ressaltar que quando P é igual a 1.0 este parâmetro não tem efeito. Isso acontece pois, por definição, a soma das probabilidades de todos os tokens já é 1.0. Então, o LLM irá considerar todos os tokens.
Em linhas gerais, no nosso exemplo, podemos escolher o P = 0.5. O LLM irá considerar apenas os tokens rato, gato e urso, pois a soma das probabilidades destes 3 tokens é igual a 0.51.
A soma pode exceder o nosso limite caso tenha a necessidade de somar a probabilidade do próximo token pois a soma total sem ele ainda não alcançou o limite, como neste caso, onde a soma totalizou 0.51 e o limite é 0.5.

Top-K e Top-P juntos
Agora que entendemos o comportamento destes dois parâmetros separadamente. Mas caso escolhermos valores de K e P, quais tokens o LLM irá considerar?!
Esta é uma dúvida frequente, pois em muitos artigos explicam como os parâmetros interferem de maneira separada. O Top-K será aplicado primeiro, restringindo a quantidade de tokens de acordo com o K. Depois, é computado a lógica do Top-P, analisando a soma dos tokens resultantes do processamento do Top-K. Vamos realizar um exemplo prático com a nossa frase.
Escolhendo K = 3 e P = 0.4 temos o seguinte comportamento. Com o Top-K escolhido temos os tokens rato, gato e urso para serem considerados, porém agora irá computar o Top-P onde nos sobra os tokens rato e gato para o LLM considerar devido a soma destes ser igual a 0.41.

Bem, tranquilo o caso a acima. Mas, e quando os tokens resultantes do processamento do Top-K, na soma das probabilidades, não alcança o limite que configuramos no Top-P?
É importante ressaltar que ao processar o Top-K, a probabilidade dos tokens que não serão considerados vai para 0. Com isso, quando ocorre o processamento do Top-P, apenas os tokens resultantes do Top-K são considerados. Mesmo a soma não alcançando o limite. Segue o exemplo com nossa frase.
Agora imagine que configuramos o K = 3 e o P = 0.6. Processando o Top-K temos os tokens rato, gato e urso. Agora a probabilidade dos outros tokens vai para 0. Ao processar o Top-P, vemos que a soma das probabilidades foi de 0.51 e não alcançou o limite.
Como as outras probabilidades foram pra 0 no processamento do Top-K os tokens considerados pelo LLM serão os mesmo que resultaram o processamento do Top-K: rato, gato e urso.

Temperatura na Softmax
Para produzirmos saídas mais criativas e diversificadas podemos ajustar o parâmetro Temperatura. Com ele, podemos variar um dos valores que compõe a função da camada Softmax. Abaixo temos a função de transformação do Logits em probabilidades.
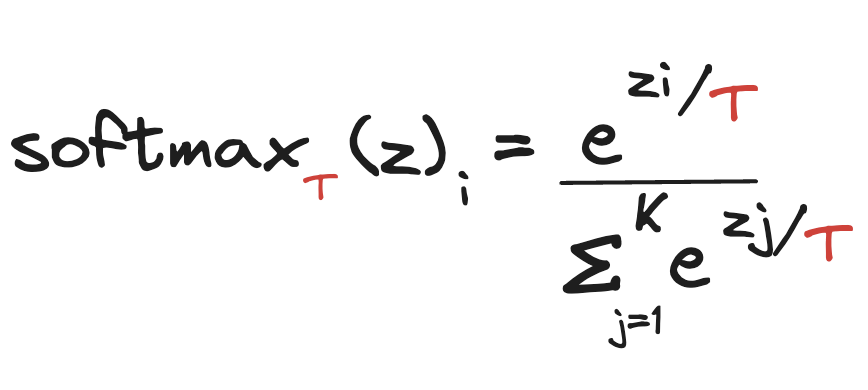
- z: É o Logits, que é o vetor de entrada da função, cada posição do vetor contém as probabilidades reais de cada token.
- softmaxT(z)i: É a nova probabilidade associada à aquele token baseada na Temperatura
- e: Constante de Euler, que é a base do logaritmo natural. Essa constante é aproximadamente igual a 2.71828.
- K: número total de tokens
- T: O parâmetro Temperatura
A palavra Softmax vem das palavras “Soft”e “Max”. A parte Soft faz com que a função gere distribuição das probabilidades mais suave. Enquanto a parte Max faz com que a função gere uma distribuição mais nítida.
Por T ser um denominador da potência de e concluímos que quanto maior o T a probabilidade é menor e quando menor o T a probabilidade aumenta. Irei usar o caso da nossa frase para esclarecer o conceito, fique tranquilo.
Abaixo temos um gráfico da variação da Temperatura na função da Softmax. Conseguimos observar que a medida que a temperatura aumenta, a normalização das probabilidades fica mais branda. Com isso, as palavras menos prováveis tem mais chance de ser escolhida, trazendo a ideia de “criatividade”.
Observamos que para uma temperatura baixa, a distribuição das probabilidades dos Tokens é bem espaçada. Assim, o que tem maior probabilidade se destaca dentre as outros, nos fornecendo saídas mais usuais. Já com a temperatura alta, esta distribuição de probabilidades é mais uniforme. Desta forma, há mais chances do modelo escolher Tokens que tem a menor probabilidade e, consequentemente, gerar respostas mais criativas.
Repetition Penalty
Penalidade de repetição é um parâmetro usado na geração de tokens para minimizar saídas repetidas, redundantes que possuem mesmos tokens e padrões. Mas o que seria uma saída repetitiva? E por que isso é indesejável?

Observe que, na nossa frase exemplo, a saída gerada repete a palavra rato sem necessidade. Digamos que a frase não está incorreta, porém não é uma resposta natural. Para nós, essa repetição soa estranha.
Ao aplicar a Penalidade de Repetição, o modelo atribui uma penalidade, ou seja, reduz a probabilidade de geração de tokens que apareceram recentemente no texto gerado. Esta penalização ajuda a promover resultados mais diversificados e variados, incentivando o modelo a gerar conteúdos novos e diferentes em vez de se repetir.
Este parâmetro é um número float que escolhemos no intervalo de 1.0 (sem penalidade) a 2.0 (máxima penalidade). A implementação específica da penalidade de repetição pode variar dependendo do modelo ou estrutura utilizada.
A mais comum é a penalidade baseada em token. Onde uma penalidade é aplicada aos tokens com base em sua frequência de ocorrência no contexto recente ou na saída gerada. Os tokens que aparecem com mais frequência são mais penalizados, reduzindo a probabilidade de serem gerados novamente.
Critérios de Parada
Meça suas palavras, LLM!
Entendemos nas sessões anteriores como alterar as formas de escolha do próximo token. Mas quando o LLM entende que deve parar de gerar a saída?
O LLM para de gerar tokens quando entende que a saída já está completa. Os modelos têm este entendimento quando uma sequência de parada é gerada, ou o número máximo de tokens foi atingido.
Escolher efetivamente estes critérios de parada são importantes para o seu caso de uso e o tipo saída desejada. Além disso, outro ponto importante que devemos considerar é o custo.
O custo atrelado ao uso de LLMs é o número de tokens gerados. Configurar estes parâmetro de maneira efetiva para seu caso de uso é uma ótima estratégia para reduzir e controlar o custo.
Abaixo eu te explico com detalhes sobre estes critérios.
Min – Max token
Se você observa que a saída do seu modelo é muito curta ou muito longa podemos ajustar estes dois parâmetros para controlarmos o número de tokens gerados na saída.
Este parâmetro nos ajuda a obter respostas mais concisas e diretas ou respostas mais verbosas. Com eles conseguimos configurar o número mínimo e máximo de tokens que o LLM irá gerar.
Então posso configurar qualquer número nestes parâmetros? Bom, o número máximo de tokens varia para cada modelo. É importante verificar na documentação do modelo que está sendo utilizado o tamanho máximo da Janela de Contexto. Descrevemos com mais detalhes este termo no artigo Introdução aos LLMs e à IA Generativa. Já o Min Token aceita números iguais ou maiores que zero.
Stop Sequence
Outra forma de dizermos para o LLM que a saída já esta completa e que não é mais necessário gerar tokens é definindo uma Sequência de Parada.
Por exemplo, imagine que a saída do nosso LLM deve ser apenas uma frase, podemos definir como uma das sequências de parada o ponto final. Assim que gerado o ponto final na saída o LLM para de gerar os tokens.
Importante lembrar que caso esteja usando a estratégia de One-Shot ou Few-Shot Prompting, é importante que todos os exemplos de saída fornecidos conterem a sequência de parada no final.
Conclusão
Como comentado, a configuração ideal dos parâmetros apresentados neste post está diretamente ligada ao caso de uso e as características da saída que ele exige. Vale a pena sucessivos testes observando as características da saída gerada e ajustando os parâmetros de acordo com a sua função.
Entender as especificações do modelo que estamos trabalhando também é muito importante. Na documentação de cada modelo conseguimos saber o tamanho máximo de tokens da Janela de Contexto – informação importante para configurarmos os Critérios de Parada, por exemplo.
Outro ponto importante é análise de custo de cada modelo. Entender a cobrança por token gerado, com isso ser efetivo na configuração dos parâmetros e consequentemente na quantidade de tokens gerados de acordo com o que o caso de uso exige.
Este post foi uma visão geral dos parâmetros de inferência e suas funcionalidades. Participe da nossa comunidade para tirar suas dúvidas. Se este conteúdo te ajudou, ou se você tem algum complemento sobre o tema, compartilhe com a gente também na comunidade do BRAINS.
Para conhecer mais sobre o BRAINS leia nosso post de apresentação BRAINS – Brazilian AI Networks, curta nossa página no Linkedin e fique à vontade em contribuir conosco e com a comunidade, vamos juntos!

