
A capacidade de grandes modelos de linguagem, ou Large Language Models (abreviados como LLMs), de criarem conteúdo é incontestável. As novas aplicações dos LLMs através de soluções de Inteligência Artificial Generativa surgem a cada dia. Porém, nem tudo acontece de forma “mágica” com LLMs. Existem casos em que os modelos precisam de uma especialização. Semelhante a um médico geral, que decide se tornar um especialista. Chamamos esta especialização de Fine-Tuning, ou Ajuste Fino, quando falamos de Inteligência Artificial.
Os LLMs, dotados de um conhecimento linguístico vasto e geral, são como médicos recém-formados, cheios de potencial, mas necessitando de treinamento adicional para tratar condições específicas.
Um médico passa por uma residência para se especializar em cardiologia ou nefrologia. Da mesma forma, os LLMs passam pelo Fine-Tuning, para se aperfeiçoar em determinadas aplicações ou casos de uso.
O conceito de Fine-Tuning refere-se ao processo de modificar os modelos pré-treinados utilizando dados específicos para a aplicação desejada e/ou dados proprietários. Para conhecer mais sobre LLMs e o processo de pré-treinamento confira nosso post Introdução aos LLMs e à IA Generativa.
Existem diferentes formas de realizar o Fine-Tuning nos modelos. No entanto, antes de abordarmos algumas delas, vamos entender mais profundamente quais os benefícios e pontos de atenção desse processo.
Benefícios e Riscos do Fine-Tuning em LLMs
Entender a aplicação desejada é o primeiro passo para a tomada de decisão em realizar o ajuste fino dos modelos. Além dessa informação é importante considerar os seguintes pontos:
Benefícios do Fine-Tuning
- Personalização: O ajuste fino do modelo com dados específicos para o domínio desejado resulta em uma maior especialização dos outputs do modelo. Essa adaptação pode ser exemplificada através de respostas mais relevantes para os inputs.
- Aumento da Precisão: Modelos ajustados tem menor chance de alucinar (Hallucination). O conceito de alucinação em LLMs refere-se à ocorrência de informações incorretas, irrelevantes ou fictícias, pelos modelos, que não estão baseadas nos dados ou na realidade. Com o processo de ajuste fino o modelo utiliza o conhecimento específico adquirido e tende a gerar respostas baseadas nos dados utilizados.
- Maior Confiabilidade e Menor Tempo de Resposta: Modelos ajustados possibilitam uma maior moderação dos outputs além de aumentar a transparência das informações utilizadas na geração de respostas. Outro item relevante é o fato de em geral modelos ajustados apresentarem um menor tempo de latência (tempo para gerar outputs) sendo que o conhecimento do modelo está otimizado.
- Custos e Recursos: veremos abaixo que os custos para se realizar esse ajuste fino são geralmente altos. Entretanto, após o Tuning, tendemos a ter resultados melhores com menos Tokens. Como sempre, é uma gangorra. Precisamos encontrar o equilíbrio.
Riscos e Desafios do Fine-Tuning
- Custos e Recursos: A aquisição e classificação (anotação, ou labeling) de dados para domínios específicos pode ser significativamente custoso. O processo de ajuste fino de modelos, apesar de usar uma quantidade muito menor de dados para treinamento, requer que a quantidade de dados seja na ordem de milhares. A qualidade dos dados utilizados no ajuste fino impacta diretamente os resultados do processo e por isso a classificação e revisão dos dados pode se tornar um processo não só custoso como demorado. Além dos itens relacionados aos dados, temos o consumo de poder computacional. O custo total depende da quantidade de dados utilizados e da forma escolhida para realizar o ajuste (Cloud ou Local). Contudo, esse processo normalmente envolve o uso de GPUs por um longo período.
- Risco de Sobre Ajuste (Overfitting) / Esquecimento Catastrófico: Apesar do processo de ajuste fino gerar melhores resultados em casos específicos existe o risco de o modelo ficar sobre ajustado para os dados do refinamento e perder a flexibilidade original com dados fora do domínio (Overfitting). Indo além, o modelo pode sofrer o que chamamos de Esquecimento Catastrófico (Catastrophic Forgetting). Especificamente, refere-se à situação em que um modelo, ao aprender novas informações ou tarefas durante o fine-tuning, perde rapidamente ou “esquece” o conhecimento adquirido anteriormente. Isso ocorre porque o modelo é ajustado com novos dados que podem divergir do conjunto original ou da funcionalidade inicial.
- Ética e Vieses: Os riscos éticos e de viesses no processo de ajuste fino normalmente estão associados ao uso de dados de má qualidade, que por si só contém vieses. Sendo assim, uma vez o ajustado com esses dados, os LLMs apresentaram o comportamento aprendido na geração de outputs.
Em geral, os benefícios do processo de ajuste fino são mais significativos e frequentes que os riscos apresentados.
O Processo de Fine-tuning
Usando uma separação macro, os processos de ajuste fino de LLMs podem ser divididos em dois. Ajuste Total (Full Tuning) ou Ajustes Fino de Parâmetros Eficientes (Parameter-Efficient Fine-Tuning, ou PEFT).
Ajuste Total (Full Tuning)
O processo de Ajuste Total dos modelos considera o treinamento de todos os parâmetros do modelo para a tarefa específica. Uma das técnicas nesse processo é a de Instruct Tuning. Discutimos sobre Instruct Tuning no post Introdução aos LLMs e à IA Generativa. Em resumo, o ajuste para instruções considera um conjunto de dados com pares de Prompt-Completion. Podem ser perguntas e repostas, ou instruções e ações tomadas.

Durante a etapa de preparação para o processo de ajuste fino os dados, os pares de Prompt-Completion são divididos três conjuntos.
- Treinamento: Os dados no conjunto de treinamento correspondem aos pares que serão usados para ajustar todos os parâmetros do modelo para a tarefa específica. De forma geral, os dados de treinamento costumam representar 70-80% do total de pares.
- Validação: A etapa de validação utiliza uma quantidade menor de dados (10-15%) com o objetivo de avaliar se o processo de ajuste fino gerou resultados positivos durante a fase de treinamento. Esses dados auxiliam no ajuste dos hiper parâmetros e são uma avaliação contra sobre ajuste (Overfitting).
- Teste: Por fim os dados de teste (10-15%) servem como uma forma de avaliação final do resultado do processo de ajuste fino. Esse conjunto de dados é importante para expor o modelo ajustado a pares nunca vistos e avaliar sua performance.
Base de dados para resumos – SAMSUM (Hugging Face)
Uma base de dados comumente utilizada para ajuste fino de modelos em tarefas de resumir conteúdos é a SAMSUM disponível no Hugging Face: https://huggingface.co/datasets/samsum
Em resumo, o processo de ajuste total tem alta eficiência em especializar os LLMs. No entanto, o fato de o ajuste acontecer com todos os parâmetros do modelo torna esse processo lento e custoso. A alternativa desenvolvida foram os processos de PEFT.
PEFT: Ajustes Fino de Parâmetros Eficientes (Parameter-Efficient Fine-Tuning)
O processo de PEFT pode acontecer de diferentes formas, porém sendo todas elas aplicadas somente em alguns parâmetros do modelo. Algumas formas são:
- Seletiva: Utilizando a técnica seletiva são escolhidos alguns parâmetros do modelo original para passarem pelo processo de ajuste fino. A definição de quais e suas quantidades depende das aplicações desejadas para o modelo ajustado.
- Reparametrização: Durante a reparametrização, os pesos (Weights) utilizados são os de baixo ranking de representação (Low-Rank Representation). A técnica mais conhecida de reparametrização é a de LoRA.
- Aditivo: No processo aditivo novas camadas de parâmetros ajustáveis são adicionadas ao modelo original. Dentre as técnicas aditivas temos a de Prompt Suave (Soft Prompt) e Adaptadores (Adapters).
Podemos considerar que as técnicas seletivas são similares ao processo de ajuste total. Portanto, vamos explorar as técnicas de reparametrização, com foco em LoRA, e a aditiva com o estudo de Soft Prompt.
Low-Rank Adaptation (LoRA)
O paper original sobre LoRA foi apresentado em 2021 por um grupo de pesquisadores da Microsoft. O artigo tem como intuito de fornecer uma alternativa de baixo custo para o processo de ajuste total de LLMs.
A técnica LoRA consiste em congelar os pesos (Weights) pré-treinados dos modelos e injetar nas camadas da arquitetura Transformer um conjunto de matrizes decompostas ajustáveis/treináveis, reduzindo assim o número total de parâmetros durante o ajuste.
Para conhecer mais sobre a arquitetura Transformer, veja nosso post Os Transformers Ilustrados.
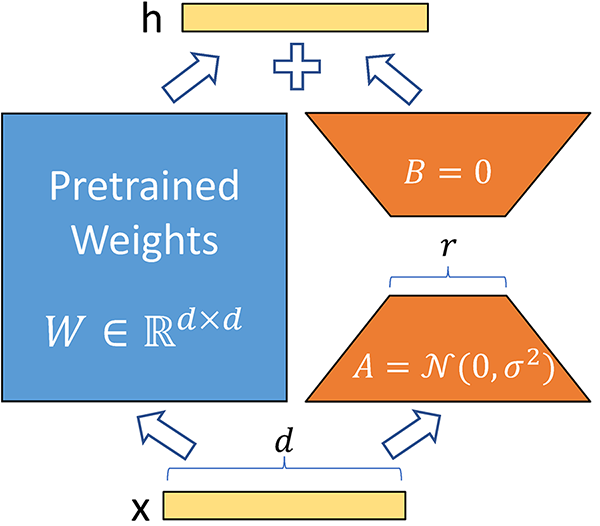
Exemplificando o LoRA
- O modelo base da arquitetura Transformer tem pesos com dimensões \(d \times k = 512 \times 64\). Sendo assim temos \(512 \times 64 = 32.768\) parâmetros ajustáveis.
- Caso aplicássemos Rank igual a 8 dimensões (\(r = 8\)), onde o Rank é o fator de multiplicação das dimensões do modelo base, teremos:
\[ A = r \times k \longrightarrow 8 \times 64 = 512 \text{ parâmetros} \]
\[ B = d \times r \longrightarrow 512 \times 8 = 4.096 \text{ parâmetros} \]
Aplicando LoRA (4.068 parâmetros) e comparando com o ajuste total (32.768 parâmetros) o processo de ajuste fino tem uma redução de 86% de parâmetros para serem ajustados.
A aplicação de LoRA no ajuste fino melhora significativamente o consumo de memória e armazenamento. Reduzimos a VRAM necessária no GPT-3 175B de 1.2 TB para 350 GB, por exemplo, conforme testes empíricos (fonte: LoRA paper). Além disso, LoRA permite ajustar o modelo para diversas tarefas sem perder o conhecimento prévio.
Usando LoRA, há uma compensação entre eficiência e profundidade no ajuste fino de LLMs. Focamos em menos parâmetros para rapidez, o que pode limitar mudanças profundas no modelo. Principalmente em tarefas complexas.
A abordagem eficiente dessa técnica é ótima para atualizações rápidas e adaptações. Porém, pode não ser tão eficaz para transformar profundamente o comportamento ou a base de conhecimento de um modelo. Especialmente em tarefas complexas ou especializadas.
Soft Prompting
A técnica de Soft Prompting também é conhecida como Prompt Tuning. E a primeira coisa a ressaltar é que ela é diferente da técnica de Engenharia de Prompt (Prompt Engineering). Na Engenharia de Prompts, trabalhamos na linguagem do nosso prompt para obter melhores resultados de resposta. Esse processo requer trabalho manual e o prompt é limitado pelo tamanho da janela de contexto. No ajuste Suave de Prompts (Soft Prompting), adicionamos Tokens treináveis ao prompt de entrada.
No processo de ajuste fino com Soft Prompting, os pesos originais do modelo base são congelados e Tokens são adicionados com o objetivo de ajustar o modelo.
Os resultados de Soft Prompting, quando comparados com o processo de ajuste total apresentam melhores resultados em modelos com mais parâmetros. Sendo comparáveis para modelos com parâmetros na ordem de 1010.
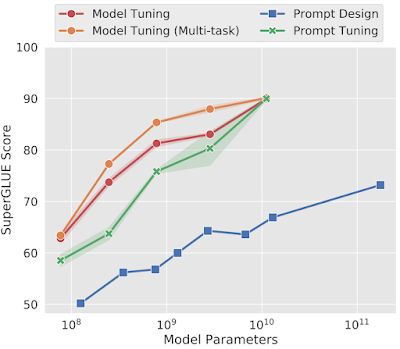
Algumas plataformas, como o watsonx.ai da IBM oferecem a opção de realizar o Soft Prompt Tuning através de interfaces gráficas, ou APIs. Basta fazer o upload da base de treino que a ferramenta faz todo o trabalho sujo.

Conclusão
O processo de ajuste fino em Large Language Models (LLMs) representa um avanço notável na personalização e eficiência da Inteligência Artificial. Apesar de alguns desafios, como custos e potenciais riscos de sobre ajuste, os benefícios superam amplamente as limitações.
Como sempre, cada caso é um caso. E saber se o Fine Tuning tem de fato o melhor custo-benefício para o seu negócio, vai depender de uma análise mais profunda.
Com a capacidade de adaptar LLMs a contextos e tarefas específicos, o ajuste fino abre um leque de possibilidades para aplicações mais precisas, confiáveis e rápidas. Este processo não apenas enriquece o repertório dos modelos, mas também os torna mais alinhados às necessidades reais dos usuários, garantindo respostas mais relevantes e contextuais. Assim, o ajuste fino se estabelece como uma ferramenta poderosa no campo da IA.
Este texto foi uma introdução mais conceitual sobre o Fine-Tuning. Em breve iremos trazer conteúdo prático sobre como de fato realizar esses ajustes finos. Tanto via código, manualmente, quanto usando ferramentas e APIs de fornecedores, como a IBM com o watsonx.
Se tiverem ficado com dúvidas, entrem em contato pelos comentários ou pelo LinkedIn! E se você quiser colaborar com material sobre IA e Machine Learning, leia o nosso posto apresentando o BRAINS – Brazilian AI Networks.
