
Atualmente o assunto mais comentado, dentro e fora do mundo da tecnologia, é sobre as incríveis capacidades dos modelos generativos. Especialmente dos grandes modelos de linguagem, ou Large Language Models (abreviados como LLMs), como os que estão por trás do fabuloso ChatGPT.
De fato, as suas capacidades são incríveis! Um único modelo que consegue resumir, classificar, analisar, revisar e criar conteúdo. E tudo isso extremamente bem. É uma era extraordinária esta que estamos vivendo.
Mas você sabe exatamente o que esses modelos fazem por dentro das suas caixas-pretas?

IA Generativa e o nosso Cérebro 🧠
Para entendermos de fato, à fundo, como os LLMs funcionam, precisamos estudar bastante matemática. Iremos avançando aos poucos nos nossos posts aqui no BRAINS. Por enquanto, nós temos em português um dos artigos mais conhecidos do mundo sobre a arquitetura de Transformers, Os Transformers Ilustrados. Esta obra prima foi escrita por Jay Alammar e traduzida por nós, com a devida autorização. É um ótimo ponto de partida para quem quer entender com um pouco mais de detalhes matemáticos como tudo funciona.
Nosso objetivo, por hora, é dar apenas uma breve e leve introdução sobre como esse tipo de modelo funciona.
Nós já definimos a Inteligência Artificial e o Machine Learning em outros posts como o Primeiramente, o que é Machine Learning? e o Foundation Models: Modelos que Revolucionaram a IA. Mas podemos resumir aqui, de forma superficial, que a Inteligência Artificial é uma máquina mimetizando a mente humana. Ou seja, uma máquina tentando fazer o que um ser humano faz bem, cognitivamente falando.
E sim, um ser humano normal costuma ser muito bom em gerar conteúdo. Nosso cérebro é excelente nesta tarefa desde que aprendemos a nos comunicar. Entretanto, há uma coisa que nosso cérebro é ainda melhor: tentar prever o futuro. Estudos indicam que os nossos cérebros estão a todo momento tentando prever o que irá acontecer nas nossas vidas.
“O cérebro é uma máquina de previsão. Ele está sempre tentando prever o que vai acontecer em seguida (…)”
Pesquisa publicada pela universidade de Oxford na revista Neuron. Fonte: https://www.cell.com/neuron/fulltext/S0896-6273(21)00124-0
E uma das formas de previsão que nosso cérebro está constantemente fazendo é a de completar cenários do nosso dia a dia com informações faltantes, que não estão disponíveis. Isso se aplica a quase tudo nessa vida, inclusive com a nossa comunicação. E com textos, obviamente, não seria diferente.
A principal habilidade dos LLMs

Eu aposto que a maioria de vocês que estão lendo este post, automaticamente, mesmo que no subconsciente, completaram a frase: “Com grandes poderes vêm grandes ____________.”
Esse é o comportamento natural do nosso cérebro. E quando falamos de modelos de IA Generativa, ou de Large Language Models (LLMs, os grandes modelos de linguagem) mais especificamente, isso é exatamente o que ele está o tempo todo tentando fazer. Completar frases prevendo qual a próxima palavra mais provável de aparecer no texto.
Sim, eu sei. Se você é um pouco mais avançado no tema deve estar me odiando agora. Tecnicamente, os modelos não preveem a próxima palavra, e sim o próximo Token. Mas para fins didáticos, vamos assumir que os modelos preveem palavras completas. Não fará diferença por enquanto. Mas caso estejam interessados em entender o que de fato são Tokens e como são gerados, recomendo o post Token e Embedding: conceitos da IA e LLMs.
E como será que esses modelos são treinados?
Pré-treino dos LLMs
Para serem treinados, os LLMs consomem enormes quantidades de texto. O que define “enorme”, ou o “Large” de LLM, é relativo. O que é enorme hoje, pode não ser mais enorme amanhã. Mas enfim, vamos ao ponto.
Nossas redes neurais conseguem hoje, graças à arquitetura de Transformers e ao mecanismo de Atenção, adquirir conhecimento dessas grandes massas de texto, de forma auto supervisionada (conhecido como Self-Supervised Learning).
Conseguimos alimentar esses grandes modelos com uma quantidade massiva de texto. O modelo lê, encontra padrões no texto, e começa a aprender a escrever. Basicamente ele começa a assimilar quais palavras são mais prováveis de aparecer após as outras. Como falamos, isso na maioria das vezes gera textos com sentido e semântica para nós.
Toda essa quantidade de dados em formato texto pode ser passada para o modelo aprender sem a necessidade de um ser humano de fato rotular esses dados, como acontece com o Machine Learning clássico. Esta nova abordagem permite um treinamento eficiente dos grandes modelos.
De fato, esta etapa é chamada de Pré-Treino (ou Pre-Training), pois há outras etapas de treino depois. E neste momento, onde o modelo está assimilando as palavras, podemos alimentá-lo com livros, artigos científicos, relatórios financeiros e médicos, conteúdo da internet, código e muito mais. Basicamente, tudo o que é texto.
Há datasets gigantescos disponíveis na internet, como o Common Crawl e o The Pile. Muitas empresas vêm desenvolvendo também seus próprios datasets curados, como a IBM criou e mantém o IBM Data Pile.
Podemos dizer que neste primeiro momento, o modelo aprende a ler. Uma analogia é a gente dar uma biblioteca para uma (super) criança e falar: “Leia e assimile o máximo possível, pois você vai precisar reproduzir esses textos”.
Alguns modelos do tipo LLM
Atualmente nós temos uma infinidade de modelos disponíveis. E a cada dia que passa, novos modelos são treinados (ou retreinados) e disponibilizados. A cada momento um novo modelo quebra recordes e toma a liderança como “melhor modelo” em determinada tarefa, ou de acordo com determinada metodologia de avaliação. No momento da escrita deste post, a Hugging Face hospeda mais de 400 mil modelos – nem todos são LLMs, entretanto.
Se você quiser ver uma linha do tempo dos modelos e marcos mais relevantes, o site Life Architect disponibiliza uma timeline interessante. Disponível em: https://lifearchitect.ai/timeline/
Há diversas formas de se diferenciar modelos LLMs. Uma delas é pelo tamanho do modelo: a quantidade de parâmetros aprendidos durante o treinamento do modelo.

Os parâmetros de um modelo de IA, especialmente dos LLMs, são os valores que o modelo ajusta durante o treinamento para aprender a realizar tarefas específicas. Eles são essencialmente as “configurações” internas do modelo. Mais especificamente, os parâmetros são as matrizes que o modelo aprende para realizar as transformações lineares necessárias para, dada uma entrada, termos uma saída precisa. Esses parâmetros incluem pesos (weights) e vieses (biases) nas conexões das redes neurais.
Quanto maior o número de parâmetros, em teoria, maior a capacidade do modelo de capturar e aprender padrões complexos nos dados. Modelos com mais parâmetros podem ser mais precisos e versáteis, mas também requerem mais dados para treinamento e são mais custosos em termos de recursos computacionais.
Outras características dos LLMs
Eu disse que modelos maiores são melhores em teoria, pois na prática nós temos muitas outras variáveis envolvidas. Uma dessas variáveis é a quantidade de Tokens que o modelo conhece. Vamos manter a visão supersimplificada de que um Token é uma palavra. Logo, a quantidade de palavras que este modelo conhece irá influenciar muito no desempenho do modelo.
Há inclusive um artigo chamando Training Compute-Optimal Large Language Models que investiga a relação ideal entre a quantidade de parâmetros versus a quantidade de tokens para um treino de modelo eficiente.
Neste artigo, a equipe do DeepMind treinou um modelo chamado Chinchilla, que com 70 bilhões de parâmetros – e pelo mesmo budget computacional – teve um desempenho consideravelmente maior que um modelo com 280 bilhões de parâmetro. Ou seja, tamanho não é documento!
Além da quantidade de tokens, outras características são cruciais para um bom desempenho de um LLM. O seu processo de Embeddings, a sua arquitetura, o processo de treinamento e refinamento e, principalmente, a qualidade dos dados, são fatores definitivos para a qualidade dos LLMs.
Se você não conhece alguns desses termos acima, não se preocupe. Em breve iremos falar um pouco sobre eles. Agora vamos entender como interagimos e tiramos valor desse tipo de modelo.
Prompts e Geração de Texto
É um pouco óbvio que a forma com a qual interagimos com modelos de linguagem natural seja via… linguagem natural! Ou seja, para extrairmos valor dos grandes modelos de linguagem, iremos trabalhar com textos.
Mas é importante definirmos alguns conceitos aqui. O primeiro, que muito de vocês deve conhecer, é o Prompt. Para um LLM, o prompt é a entrada de texto fornecida pelo usuário que serve como gatilho para que o modelo desempenhe a sua tarefa de geração de texto.
O prompt desempenha um papel crucial na interação com os LLMs, pois orienta a direção e o contexto da resposta do modelo. Muito em breve iremos compartilhar um conteúdo sobre a Engenharia de Prompts, ou Prompt Engineering, que são técnicas de como bolar prompts mais eficientes e eficazes.
Mas vamos voltar às nossas definições de conceitos.
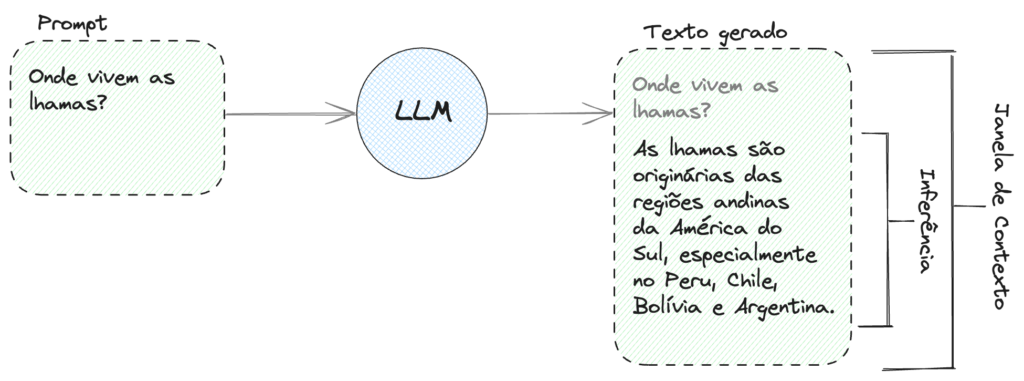
Prompt, Inferência e Janela de Contexto
O Prompt, como já vimos, é a instrução que damos para o modelo LLM. É o que queremos que o modelo faça ou responda.
A Inferência é o texto propriamente gerado pelo modelo. Ou seja, é a resposta da sua pergunta ou a execução do seu comando.
Reparem que na saída do modelo, acima da Inferência, temos ainda o Prompt, em cinza. O conjunto de Prompt mais Inferência forma o que chamamos de Janela de Contexto, ou Context Window.
A Janela de Contexto é um conceito muito importante, pois ela é limitada. Todo LLM tem um tamanho máximo de janela de contexto, e isso varia de modelo para modelo. Nós podemos encontrar janelas de contexto desde 2 mil a 128 mil tokens palavras (sim, vamos continuar considerando que um token é igual a uma palavra por enquanto). Até recentemente o modelo com maior janela de contexto era o GPT-4 com 32 mil, mas há alguns dias atrás a OpenAI anunciou o GPT-4 Turbo com 128 mil! Impressionante.
Modelo Claude 2.1 traz Janela de Contexto de 200k tokens
Enquanto escrevia este post, a Anthropic anunciou o lançamento do seu modelo Claude 2.1 que suporta uma janela de contexto de 200 mil tokens! Preferi colocar esta informação como uma nota para demonstrar o quão rápido as coisas estão evoluindo. Fonte: https://www.anthropic.com/index/claude-2-1
Esse limite de janela de contexto quer nos dizer que a soma das palavras de entrada com as palavras de saída não pode ultrapassar a limitação do modelo. Portanto, não podemos enviar uma enciclopédia de uma vez para um LLM como prompt e não podemos também pedir para ele escrever um livro completo de apenas uma vez.
Há diversas técnicas para contornar as limitações de Janela de Contexto e permitir que os modelos lidem com enormes quantidades de texto de maneira performática. Em breve traremos posts falando sobre isso.
Dois tipos básicos de LLMs
Nós temos dois tipos básicos de LLMs: os Base Models (ou Modelos Base) e os Instruct-tuned Models (ou “Modelos Ajustados para Instruções”, em tradução livre).
E a diferença entre os dois é que o primeiro passou apenas pela etapa de pré-treino, ou Pre-Training, e o segundo passou pela etapa de Instruct Tuning.
Vamos tentar ilustrar a diferença do comportamento dos dois.
Modelos Base
Como falamos anteriormente, os LLMs são muito bons em completar frases. Em prever quais são as próximas palavras mais prováveis, dadas as palavras anteriores. E assim vamos formando textos que (em sua grande maioria) fazem sentido. Por exemplo, se colocarmos em um LLM a entrada “O céu é “ ele muito provavelmente vai completar com “azul.” porque é a saída mais provável.
Então o que acontecer se perguntarmos para um Modelo base onde vivem as lhamas?
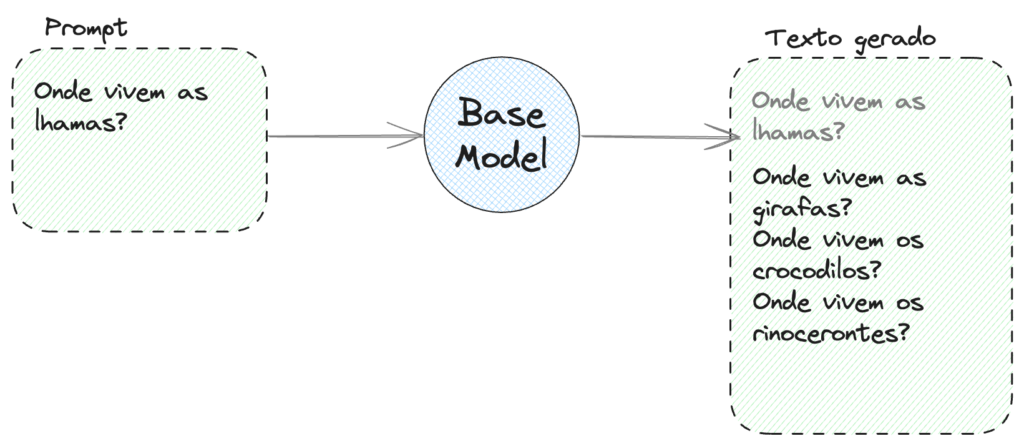
Muito provavelmente o resultado será semelhante a este. Por quê? O modelo é burro e não sabe responder? Não. Essa é a natureza desse tipo de modelo.
Como falamos, os modelos base simplesmente completam o texto com as próximas palavras mais prováveis. E os LLMs são pré-treinados em enormes quantidades de textos. Textos provenientes de livros e da internet, como falamos. E nestes formatos de texto, é estatisticamente mais provável que uma pergunta seja seguida de outras perguntas, e não de respostas.
Dado que o modelo aprendeu que na maior parte das vezes perguntas são seguidas por outras perguntas, é assim que ele se comporta. Vamos ver na prática?
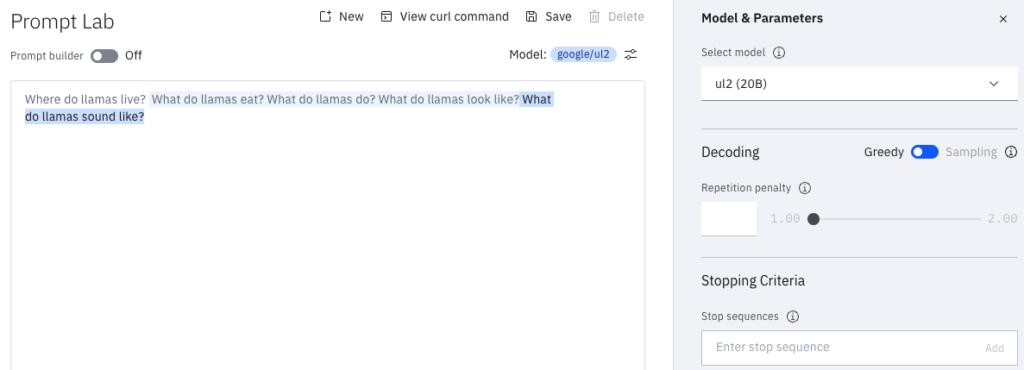
google/ul-2 para a pergunta: “Onde vivem as lhamas?”Esse teste foi feito no IBM watsonx.ai. É possível fazer testes e usar o watsonx.ai grátis. Vale a pena! Tudo que está destacado em azul são as inferências do modelo para a pergunta “Onde vivem as lhamas?”. O prompt foi feito em inglês pois esse modelo não fala português.
Novamente você pode estar se perguntando: esse modelo é burro? Novamente te digo que não. Ele é um modelo que só completa frases. E sabendo disso, podemos ajudar o nosso modelo a se sair melhor.
Ajudando os nossos Modelos Base

Agora o prompt é basicamente o mesmo. Porém no prompt nós damos uma dica pro nosso modelo, dando indícios que queremos que ele responda a nossa pergunta. Depois da nossa pergunta original, nós começamos a responder à pergunta, adicionando “As lhamas vivem “ após nossa pergunta.
Desta forma o modelo irá continuar completando com as palavras mais prováveis. Porém agora ele irá trazer as palavras mais prováveis já respondendo à nossa pergunta. Vamos ver na prática novamente?
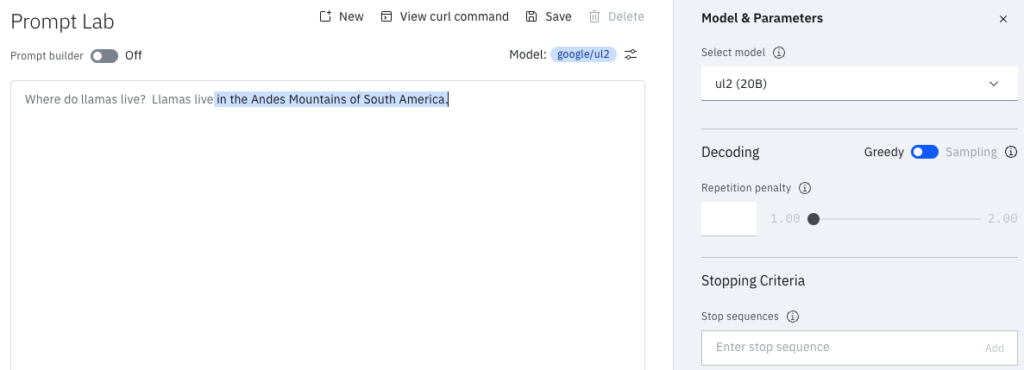
google/ul2 respondendo à mesma pergunta, agora com uma dica.Bem melhor, né? Isso nos mostra que saber como os modelos são construídos e como eles funcionam nos possibilita lidar melhor com eles. Assim podemos extrair mais valor, principalmente de modelos menores, mais simples, mais rápidos e mais baratos.
Mas não é assim que os grandes modelos LLMs impressionantes funcionam. A gente não precisa dar dicas para o ChatGPT, certo? E por que será que não? Bom, é porque esses modelos são do tipo Instruct-tuned.
Modelos Instruct-tuned
Os modelos mais impressionantes, que conseguem fazer quase tudo o que pedimos para eles (relacionados ao tratamento de texto, óbvio) são modelos Instruct-tuned. Isso quer dizer que depois de eles passarem pelo Pré-Treino, onde eles apenas assimilam uma enorme quantidade de texto sem uma finalidade específica que não seja reproduzir esses textos, eles passam por mais uma rodada de treinamento.
Essa segunda rodada de treino é mais conhecida como um Tuning (Ajuste). Para ser mais preciso, um Instruct Tuning, ou um “ajuste para instruções”. Ou seja, primeiro ele adquire todo o seu conhecimento e, num segundo momento, aprende a tornar o seu conhecimento mais útil para nós, usuários.
Neste momento, o modelo aprende que quando recebe uma pergunta, ele deve gerar uma resposta. E não uma outra pergunta.

Mas como isso é possível?
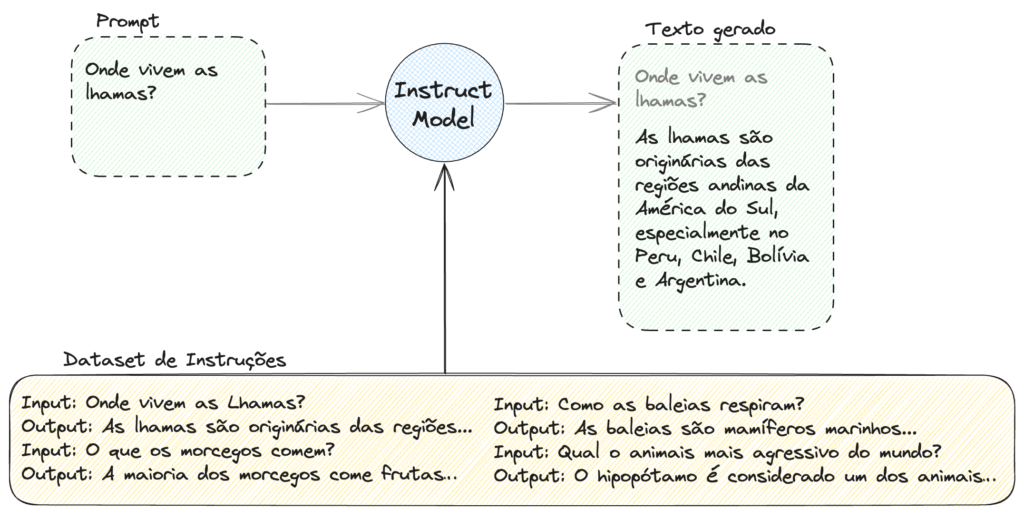
Esse ajuste do modelo para que ele passe a seguir instruções é feito por meio de uma segunda etapa de treino, onde alimentamos o LLM com um dataset de instruções. Nesta nova base de dados, ensinamos que quando há uma pergunta na entrada, a saída deve ser uma resposta para esta pergunta. Quando há um pedido de atividade, esta atividade deve ser executada.
Um exemplo de um dataset de instruções Open Source em português é o Cabrita, uma variação tupiniquim do dataset do Llama.
Vamos ver na prática como sai o resultado?

ibm/mpt-7b-instruct para a mesma pergunta sobre as lhamas.Agora sim! Bem melhor. Mas repare em algo interessante. O modelo MPT-7B é um modelo base Open Source. Mas esse em específico, do watsonx.ai, tem um -instruct2 no nome. Isso quer dizer é que uma versão orientada a seguir instruções do modelo base MPT.
Nomenclatura dos LLMs
O modelo acima é um ótimo exemplo para entendermos um pouco mais sobre a nomenclatura dos modelos.
Vamos analisar este modelo para ilustrar.

O nome do modelo nos diz que a IBM o publicou. Diz que é o LLM da família MosaicPretrainedTransformer (MPT), na sua versão com 7 bilhões de parâmetros. E nos diz também que ele é uma versão ajustada para seguir instruções, com a informação -instruct2.
Esse formato de nomenclatura segue uma convenção adotada na Hugging Face, o maior repositório de modelos da atualidade. E por convenção os modelos com -instruct são treinados para seguir instruções e os modelos com -chat para atuar como chatbots. Ambos vão ser modelos extremamente úteis, no geral.
Conclusão
Os Large Language Models são tema para uma graduação inteira. Nosso objetivo aqui é, aos poucos, tentar simplificar um pouco alguns conceitos para que a nossa comunidade siga ficando cada vez mais íntima com esse tipo de modelo, e com a Inteligência Artificial como um todo.
O plano é fazer uma série de posts que se conectam e dão sequência à linha de raciocínio. Para os mais avançados, me perdoem se simplifiquei demais neste primeiro momento. Prometo que nos próximos posts vamos pisar um pouco mais fundo nesse oceano. Sugiro como próxima leitura o post Token e Embedding: conceitos da IA e LLMs, onde conceitos muito importantes são explicados.
Se você quiser se aprofundar mais nestes temas, recomendamos o post Os Transformers Ilustrados. E fique de olho aqui no site e na nossa página no LinkedIn, pois em breve vamos liberar mais conteúdo.
Entre em contato com a gente caso tenha conhecimento sobre LLMs. Toda colaboração é bem-vinda para a nossa comunidade, e todos podem colaborar! Os mais avançados podem nos ajudar com conteúdo. E os que não se sentem prontos para escrever, podem ajudar com suas dúvidas e sugerindo temas para os próximos posts. É sempre um prazer ter vocês por aqui.
Para nos conhecer um pouco mais e saber sobre a nossa proposta da comunidade, peço para que leiam o post principal do BRAINS – Brazilian AI Networks aqui no nosso site. E não se esqueçam que…

3 comentários
Parabéns pelo artigo, conteúdo rico e fácil de entender.
Muuito obrigado Henzo! Fico SUPER feliz que você gostou do conteúdo!
Sensacional, artigo super didático, obrigado!