
Autores: Eduardo Pazini / Guilherme Bernieri
Supere os desafios na implementação de Chatbots inteligentes com o Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) é o processo de otimizar a saída de um grande modelo de linguagem (LLM), de forma que ele faça referência a uma base de conhecimento confiável fora das suas fontes de dados de treinamento antes de gerar uma resposta. Isso é particularmente popular hoje em dia porque aumenta a precisão e a relevância das respostas do modelo ao incorporar informações atualizadas e específicas de domínios que podem não estar bem representadas no treinamento original do modelo. Além disso, o RAG permite uma resposta mais dinâmica e adaptativa a perguntas ou tópicos emergentes.
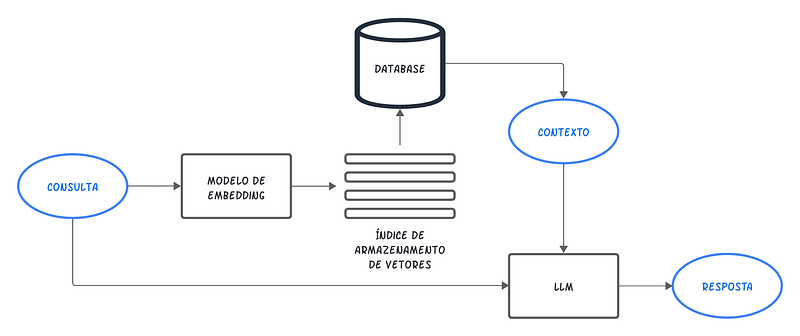
O RAG funciona integrando técnicas de busca e geração de texto. Quando uma consulta é feita, o sistema busca documentos relevantes em uma base de dados, que então servem de contexto para um modelo de linguagem gerar uma resposta final. No RAG, as bases vetoriais são essenciais para indexar e recuperar documentos de maneira eficiente. Os documentos são convertidos em vetores (Embeddings) que capturam seu conteúdo semântico, permitindo que o sistema identifique rapidamente os mais relevantes para uma consulta específica.
No Naive RAG, o formato mais tradicional, a consulta do usuário é vetorizada utilizando o mesmo modelo de vetorização empregado na base de dados. Em seguida, a pesquisa desse vetor de consulta é realizada em um índice do banco de vetores, onde são encontrados os k trechos de documentos mais relevantes, medindo a similaridade entre os vetores. Dessa forma, esses trechos de texto são recuperados e integrados para enriquecer o prompt de geração de respostas, proporcionando ao modelo uma base de conhecimento externa que pode não estar presente em seu treinamento inicial. Isso permite uma geração de respostas mais informada e contextualmente apropriada.
Existem várias opções de modelos de linguagem no mercado, e cada um tem suas próprias estratégias de engenharia de prompt. Conhecer as melhores estratégias e as boas práticas de engenharia de prompt é fundamental para que a resposta final do RAG atenda às necessidades e exigências específicas dos usuários. A seguir, apresentamos um exemplo de como um prompt pode ser construído para uma aplicação utilizando a OpenAI.
def question_answering(context, query):
prompt = f"""
Use the context provided to craft a clear and detailed answer to the given question.
Context: {context}
Question: {query}
\n
If the context provided does not contain information to answer the question, answer exactly the following sentence:
Sorry, I don't know the answer to that, I couldn't find that information in my knowledge base. Please, redo your question with more details.
\n
Answer in Portuguese and in Markdown format, without using tags.
"""
response = get_completion(instruction, prompt, model="gpt-3.5-turbo")
answer = response.choices[0].message["content"]
return answer
Porém, comumente a implementação do Naive RAG não é suficiente para atender às demandas de produção devido às seguintes razões:
- Ambiguidade das perguntas: Ocasionalmente, os usuários formulam perguntas que não estão claramente definidas, o que pode resultar em uma recuperação de informações irrelevantes;
- Baixa precisão de recuperação: Os documentos recuperados podem não ser todos igualmente relevantes para responder às questões;
- Conhecimento limitado: A base de conhecimento não inclui a informação que o usuário procura;
- Restrições de desempenho: Recuperar informações em excesso pode exceder a janela de contexto ou, de outra forma, produzir uma janela de contexto muito grande para retornar um resultado em um período de tempo razoável.
Para contornar essas limitações, existem técnicas avançadas de RAG que buscam abordar esses desafios de forma mais eficaz e robusta. Essas técnicas de otimização serão investigadas em três fases distintas: pré-recuperação, recuperação e pós-recuperação. É importante ressaltar que não existe uma solução única para esses problemas e que cada abordagem pode encontrar obstáculos específicos em diferentes contextos.
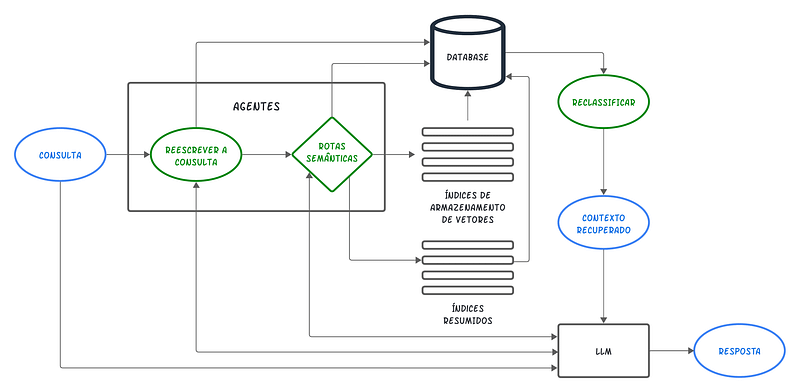
Pré-recuperação
Na etapa de pré-recuperação, os dados que estão fora do conjunto de dados de treinamento original do modelo de linguagem, também chamados de dados externos, precisam ser preparados e divididos em partes (chunks). Em seguida, é necessário indexar esses dados usando modelos de Embeddings, que convertem os dados em representações numéricas e os armazenam em um banco de dados vetorial. As técnicas de otimização da fase de pré-recuperação incluem a melhoria da qualidade dos dados indexados e a otimização dos chunks.
Melhoraria da qualidade dos dados
O desempenho de uma solução RAG depende de quão bem os dados são limpos e organizados. Isso inclui a remoção de informações desnecessárias, como caracteres especiais, metadados indesejados e tags HTML, bem como a identificação e correção de erros. Além disso, substituir pronomes por nomes nos textos dos documentos ajuda a aumentar a significância semântica durante a recuperação dos chunks.
Utilização de metadados
Adicionar metadados aos índices do banco de vetores, tais como categorias, datas ou conceitos, melhora a eficiência da recuperação das informações indexadas e, consequentemente, a qualidade das respostas. Existem diferentes cenários nos quais o uso de metadados pode ser benéfico, incluindo:
- Recência: Se a data de publicação ou a última atualização de um documento for relevante para a consulta;
- Tipo de Documento: Se a consulta exigir um tipo específico de documento, como artigo científico, relatório financeiro ou manual de instruções;
- Localização: Se a consulta estiver relacionada a eventos ou informações de um local específico;
- Autoria: Se a consulta estiver interessada em documentos de um autor específico.
Otimização de chunks
O grande desafio da otimização de chunks é encontrar o tamanho ideal para a sua solução. Nessa técnica, se o chunk for muito pequeno, pode não incluir todas as informações necessárias para o modelo de linguagem responder à consulta do usuário. Entretanto, se o chunk for muito grande, pode conter informações irrelevantes em excesso, que confundem o modelo ou podem ser grandes demais para se adequarem ao tamanho do contexto.
Não há um número mágico definido para o tamanho ideal de chunking. No entanto, observa-se que em aplicações de baixo nível, como análise de códigos, o uso de chunks menores, de cerca de 128 tokens, tende a proporcionar melhores resultados. Por outro lado, em aplicações de alto nível, como a sumarização de documentos, janelas de tokens maiores, de até 512 tokens, são mais adequadas.
Existem diversas estratégias para otimização de chunks, e cada uma pode ser adequada para situações diferentes. Ao examinar os pontos fortes e fracos de cada estratégia, é possível identificar o cenário correto para aplicá-las.
- Segmentação de Tamanho Fixo
Essa técnica segmenta o texto em blocos contendo um número predefinido de tokens. A sobreposição entre os blocos é opcional, mas frequentemente utilizada para manter a continuidade do contexto semântico. Devido à sua simplicidade e baixo custo computacional, essa é a abordagem mais comum, ideal para cenários onde a complexidade do conteúdo é mínima ou uma segmentação rápida é necessária. - Segmentação Recursiva
Neste método, o texto é inicialmente segmentado em blocos que são progressivamente subdivididos em tamanhos menores e mais gerenciáveis. Este processo continua até que os blocos atinjam o tamanho ou formato desejado. Esse tipo de segmentação é útil para textos onde a uniformidade de tamanho dos blocos é menos crucial, mas uma distribuição equilibrada é benéfica. - Segmentação Especializada
Alguns formatos de texto, como Markdown e LaTeX, requerem métodos de segmentação que respeitem sua estrutura formatada e organização lógica. Em Markdown, a segmentação pode ser baseada na hierarquia dos elementos de marcação, como cabeçalhos ou listas. Já em LaTeX, a estrutura complexa e os elementos de marcação específicos, como seções ou ambientes matemáticos, exigem que a segmentação preserve as divisões lógicas do documento.
Rotas semânticas
O roteamento semântico de consultas é o passo de tomada de decisão sobre o que fazer, dado uma consulta do usuário. As opções geralmente são resumir, realizar uma pesquisa em algum índice de dados ou tentar várias rotas diferentes e, em seguida, sintetizar suas saídas em uma única resposta.
As rotas semânticas também são usadas para selecionar um índice, ou de forma mais ampla, um armazenamento de dados, para onde enviar a consulta do usuário. Em termos práticos, é possível ter várias fontes de dados, por exemplo:
- Um armazenamento vetorial clássico, um banco de dados de grafos e um banco de dados relacional;
- Uma hierarquia de índices — para o armazenamento de vários documentos, um caso bastante clássico seria um índice de resumos e outro índice de vetores de chunks de documentos.
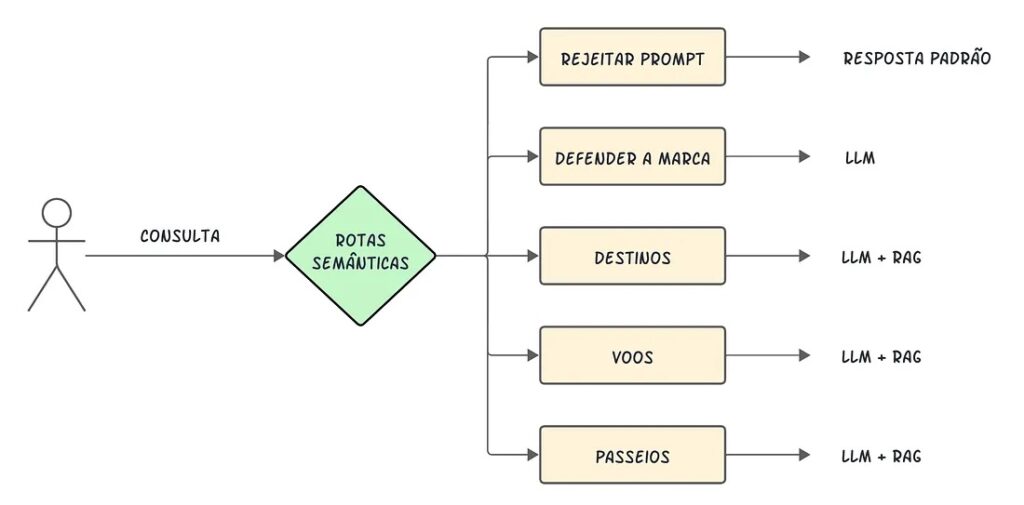
As rotas semânticas podem ser implementadas utilizando o LlamaIndex ou LangChain, essas que são as duas principais bibliotecas de código aberto para aplicações baseadas em LLMs.
Recuperação
Nessa fase, o objetivo é selecionar um conjunto de documentos ou informações que são mais propensos a conter a resposta adequada à consulta do usuário. Geralmente, a recuperação é baseada na busca por vetores, que calcula a similaridade semântica entre a consulta e os dados indexados.
Enriquecimento do contexto
O conceito aqui é recuperar chunks menores para melhorar a qualidade da pesquisa, enquanto fornecemos o contexto circundante para o LLM construir respostas mais assertivas e detalhadas. Dentre as alternativas para essa técnica podemos destacar:
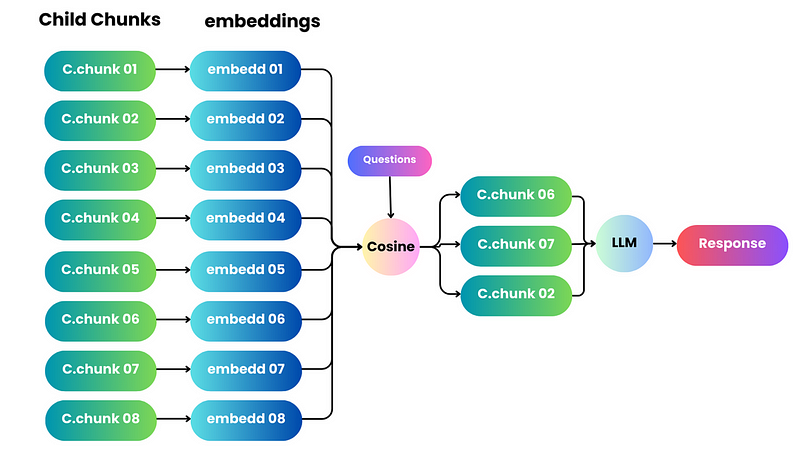
- Sentence Window Retrieval
Nessa técnica, cada frase em um documento é incorporada individualmente, garantindo uma precisão considerável na contextualização da pesquisa através da similaridade por cossenos. Para aprofundar o entendimento do contexto após encontrar a frase única mais relevante, ampliamos a janela contextual em k frases antes e depois da frase recuperada e, em seguida, enviamos esse contexto ampliado para o LLM.

- Parent Document Retrieval
A abordagem aqui é muito semelhante à do Sentence Window Retriever: primeiramente busca-se por informações mais detalhadas e, em seguida, amplia a janela de contexto antes de fornecer esse contexto a um LLM para análise. Os documentos são fragmentados em partes menores, referenciando-se a segmentos pais maiores.
Reescrita da consulta
É possível utilizar a capacidade dos próprios modelos de linguagem para reformular a consulta do usuário de forma otimizada e fazer a recuperação. É importante notar que duas perguntas que possam parecer idênticas para uma pessoa podem não ser consideradas semelhantes no contexto de incorporação de dados. Dentre as alternativas para a reescrita da consulta, podemos destacar:
- Stand-alone query
Uma “stand-alone query” é uma consulta formulada de forma clara, específica e autossuficiente, projetada para ser compreendida e respondida sem necessidade de contexto ou informações adicionais. Dessa forma, um modelo de linguagem pode ser utilizado para reescrever perguntas ambíguas ou incompletas em consultas stand-alone. O modelo analisa a consulta original para identificar termos vagos ou referências que requerem esclarecimentos, depois, com base no contexto, reformula a pergunta adicionando detalhes necessários, definindo termos, e esclarecendo o objetivo. Isso aprimora a capacidade do sistema de processar a consulta e de recuperar informações pertinentes de forma mais eficiente e precisa. - Recuperação multiconsulta
Aqui, o modelo de linguagem gerará várias consultas diferentes a partir de uma única consulta do usuário, buscando dividir a questão em vários subproblemas. Para cada consulta gerada, retorna-se um conjunto de documentos relevantes e combina todas as respostas em uma única para ampliar o conjunto de documentos potencialmente úteis. Essa abordagem supera limitações da recuperação baseada em distância, resultando em um conjunto mais diversificado e rico de resultados.
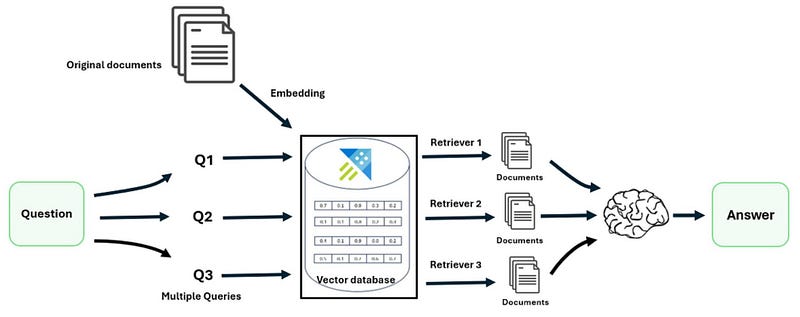
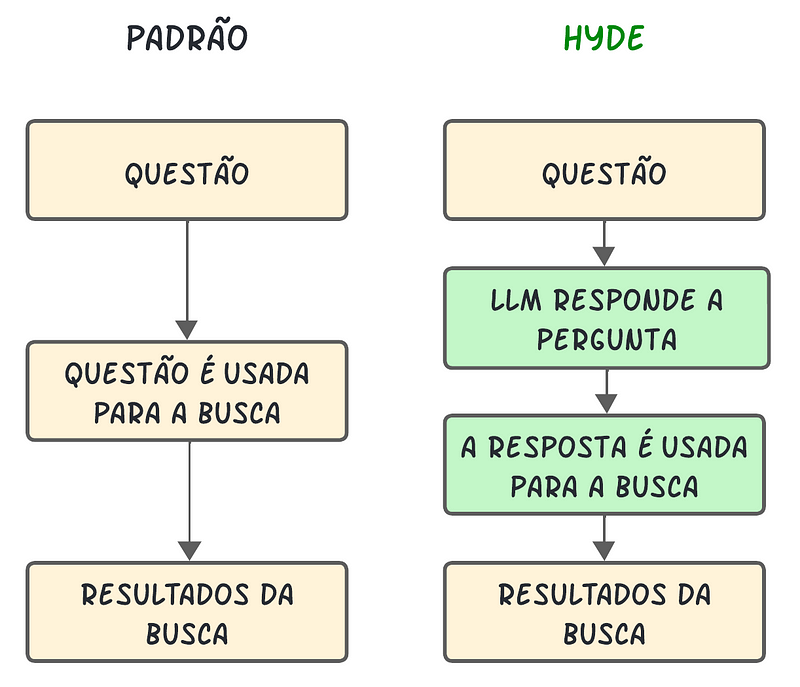
- HyDE ou Query2doc
Essas duas abordagens são semelhantes em seus processos para reescrever a query. Como as consultas geralmente são curtas, ambíguas ou carecem de informações essenciais, os LLMs podem fornecer informações relevantes para melhorar os sistemas de recuperação. Isso ocorre porque esses modelos memorizam vasto conhecimento e padrões linguísticos durante o pré-treinamento em trilhões de tokens. O HyDE, por exemplo, cria uma resposta “hipotética” com a ajuda do LLM e, em seguida, procura uma correspondência nos embeddings. No entanto, se o assunto em discussão não for totalmente familiar ao modelo de linguagem, esta abordagem não é eficaz e pode levar a um aumento na geração de informações incorretas.
Fine-tuning embedding
Esse processo envolve a personalização do modelo de embeddings para melhorar a relevância da recuperação em contextos específicos, especialmente em domínios profissionais que lidam com termos em evolução ou raros.
A ideia principal é que os dados de treinamento para fine-tuning podem ser gerados usando modelos de linguagem para formular perguntas com base em trechos de documentos. Isso nos permite gerar pares sintéticos positivos de forma escalável sem a necessidade de rotulagens manuais. O conjunto de dados final consistirá em pares de perguntas e trechos de texto.
Pesquisa híbrida
O RAG melhora seu desempenho ao integrar de maneira inteligente várias técnicas, incluindo pesquisa baseada em palavras-chave, pesquisa semântica e pesquisa vetorial. Essa abordagem combina os pontos fortes únicos de cada método para lidar com diferentes tipos de consultas e requisitos de informação. A utilização da busca híbrida complementa de forma robusta as estratégias de recuperação.
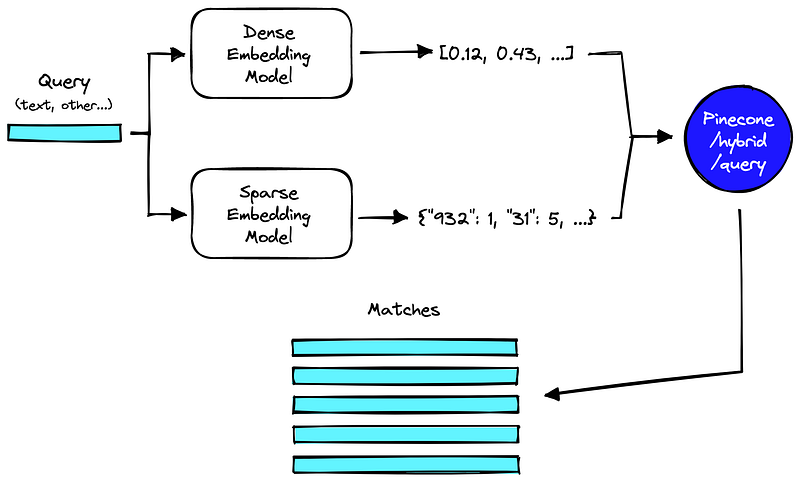
Pós-recuperação
Na pós-recuperação, o modelo RAG amplia a consulta do usuário (prompts) adicionando os dados relevantes recuperados no contexto. Esta etapa utiliza técnicas de engenharia de prompts para comunicar efetivamente com o modelo de linguagem. O prompt ampliado permite que os grandes modelos de linguagem gerem uma resposta precisa às consultas do usuário usando o contexto fornecido.
Reclassificação
Uma pontuação alta na busca de similaridade vetorial não significa que sempre terá a maior relevância. O conceito central dessa técnica envolve reclassificar os registros de documentos para priorizar os itens mais relevantes no topo, limitando o contexto a documentos mais propensos a conter a resposta da consulta.
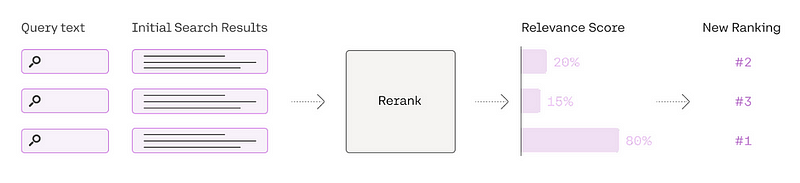
Compressão da consulta
Outra grande vantagem na construção de um sistema RAG eficaz é a aplicação da lógica de conversação. Isso é essencial para suportar perguntas de acompanhamento ou comandos arbitrários do usuário relacionados ao contexto do diálogo anterior. Essa capacidade é abordada pela técnica de compressão de consultas, que incorpora o contexto do chat juntamente com a consulta inicial do usuário. Existem diversas alternativas para essa abordagem, porém podemos destacar:
- ContextChatEngine: Recupera-se o contexto relevante para a consulta do usuário e depois o envia para o LLM junto com o histórico do bate-papo do buffer de memória para que o LLM tenha mais contexto enquanto gera a próxima resposta.
- CondensePlusContextMode: O histórico do chat e a última mensagem são condensados em uma nova consulta, como uma stand-alone, então essa consulta recupera contexto do banco de vetores, e por fim, esse contexto é passado para o LLM junto com a mensagem original do usuário para gerar uma resposta.
Considerações Finais
Por fim, as técnicas avançadas de RAG apresentadas neste texto são apenas uma seleção das muitas abordagens disponíveis, escolhidas por sua popularidade ou impacto significativo no laboratório de pesquisa aplicada da Senior Sistemas (Senior Labs). É essencial ressaltar que essas técnicas devem ser rigorosamente testadas e validadas antes de serem incorporadas a um pipeline RAG em produção.
Os principais modelos de linguagem e bancos de dados de vetores do mercado possuem documentações que já cobrem muitas dessas técnicas, proporcionando um sólido ponto de partida para experimentação e implementação. Em nossa experiência no Senior Labs, os resultados obtidos com as técnicas de reescrita de consulta e reclassificação de documentos foram particularmente promissores, destacando o potencial dessas abordagens avançadas para aprimorar significativamente a eficácia e a relevância dos sistemas de recuperação de informações baseados em RAG.
E se você quiser discutir mais sobre RAG e LLMs, estamos na comunidade BRAINS e ficaremos felizes em conversar mais sobre! Se registrem lá e vamos conversar.

