
No post anterior (aqui) ao qual apresentei a tecnologia Spark, vimos como a ferramenta se organiza e processa dados por debaixo do que nos é apresentado.
Entendemos seus principais componentes, APIs, bibliotecas disponíveis e as ferramentas de administração na web.
Continuando diretamente o artigo anterior, quero terminar de apresentar os princípios básicos do Spark mostrando como ocorre o processamento e quais tipos de transformações temos para trabalhar com big data.
Desse modo, vamos finalizar a primeira parte e melhorar o nosso conhecimento sobre essa ferramenta.
INTRODUÇÃO
O que sustenta as high-level APIs (DataFrames e Datasets) é o engine do SparkSQL. Com essa engine embutida, o Spark passou a ser capaz de trabalhar com comandos SQL-like.
O maior benefício das APIs estruturadas foi entregar simplicidade e clareza. Graças a sua construção em cima da linguagem SQL.
Quando operamos com a API, trabalhamos com DataFrame, que é uma estrutura muito similar às tabelas de banco de dados, tornando o objeto de manipulação em uma entidade estruturada.
DATAFRAME & SCHEMAS
Assim como o pacote Pandas para Python que serve para tratamento e análise de dados, o Spark também utiliza uma importante estrutura presente nesse pacote, o Dataframe.
A manipulação de dataframes utilizando a API da linguagem Python é feita com a biblioteca PySpark.
Dataframe é como uma tabela ‘virtual’ armazenada em memória com colunas e linhas. Toda vez que importamos algum arquivo para o Spark, estamos criando um dataframe de dados para transformar.
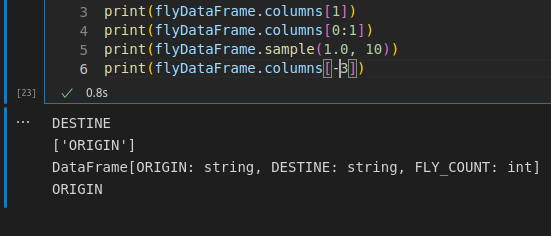
Abaixo, veja um dataframe criado como exemplo. Perceba que no mesmo bloco de comando, eu busco o tipo para saber se é um dataframe ou não.

Dentro do comando, é possível utilizar uma estrutura de colunas e linhas para criar um dataframe ‘manual’ com PySpark.

Um dataframe também possui um Schema, que é uma forma de apresentar o nome das colunas e seus data types. Quando criamos um dataframe utilizando a biblioteca PySpark, normalmente criamos um schema e após, criamos o dataframe passando as informações do schema para ele.
Existem duas formas de se definir um schema no Spark. Uma utilizando a linguagem de programação e a outra, SQL com comandos DDL.
Antes de começar a criar o Schema é preciso importar um pacote que contém as classes e métodos necessários.
O primeiro a ser criado foi com PySpark.

Agora utilizando o SparkSQL como método para criar o schema para o dataframe.

É ainda mais fácil criar a estrutura com o SparkSQL do que PySpark.
Para a estrutura PySpark, primeiro devemos importar o pacote que está dentro do grupo Types.

Criando os dataframes, basta passar os schemas que estão na variável e exibir.
Criação de um dataframe utilizando PySpark.
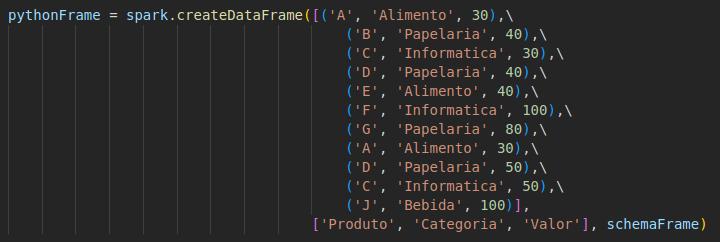
NOTA: O Spark consegue identificar o schema dos dados que está trabalhando, porém, isso pode custar processamento extra. O recomendado é que caso vá utilizar o Spark como ETL, defina o Schema manualmente.
Como resultado, veja uma operação com o dataframe utilizando o schema.

Utilizando o comando PrintSchema, o schema do dataframe nos é exibido.

É importante destacar que na criação do dataframe e do schema, em alguns casos, mesmo que seja explicitado um datatype, o Spark pode reconsiderar e aplicar outro.
Isso fica claro na coluna valor que passei como sendo Integer, mas o Spark atribui como Long.
Em Python/R os Dataframes possuem algumas exceções, sendo uma delas, trabalharem em um máquina local, não permitindo o particionamento e o benefício do paralelismo.
IMPORTANTE: Na maior parte das transformações, o Spark utilizará o seu próprio Data Type (Spark Type). Mesmo que haja transformação envolvendo Python ou R, o que prevalecerá será o Spark.
Ainda que um schema de um dataframe permita que ele contenha NULL, o campo precisa ser informado.
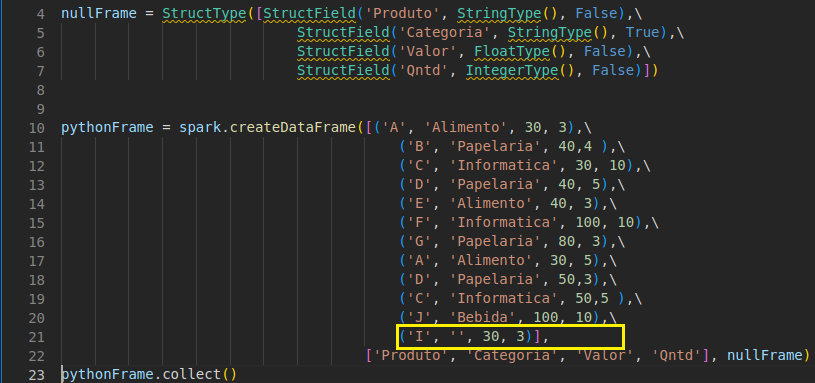
Perceba que Spark aceita campo vazio, mas não aceita campo ‘faltante’. Na imagem acima, há uma string vazia, indicando NULL, porém, na próxima não há.
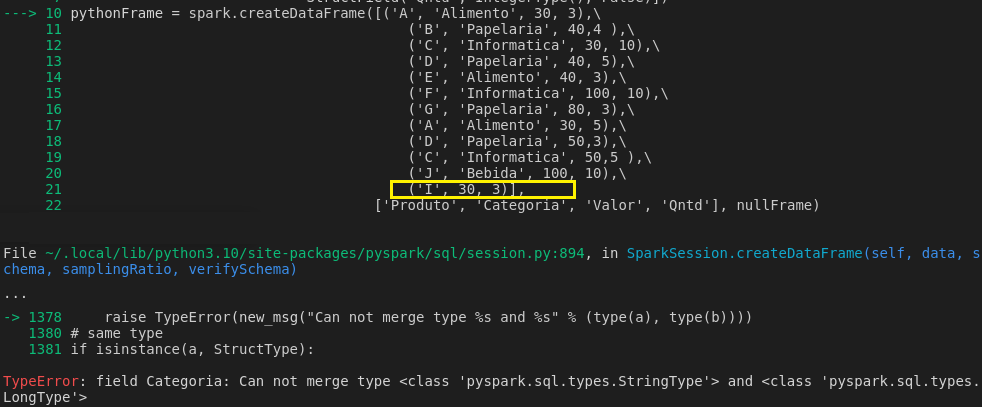
Como o Spark converte a operação por possuir uma interface linguística que interpreta o código em uma dessas linguagens, o Dataframe criado em Python/R acaba sendo convertido para Spark Dataframe, permitindo assim, utilizar os benefícios da tecnologia.
O benefício do dataframe é a facilidade com que se distribui a estrutura nos clusters. Assim, se for muito grande para ser processado em uma máquina, não enfrentará problema e se for pequeno, será mais rápido do que um processo single-node.
CRIANDO DATAFRAMES COM PANDAS, RDD E PYSPARK
Uma das formas de se criar um dataframe é através de uma lista de linhas (ROW), que é uma estrutura do dataframe.
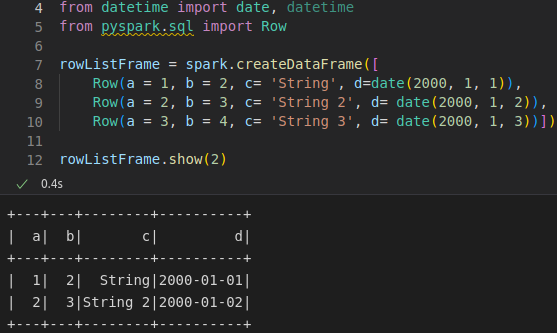
Quando trabalhando com Spark utilizando a linguagem Scala, Dataframes são simples Datasets do tipo ROW. ROW é uma estrutura de dados que compõe os Dataframes em Scala e é otimizado para operar In-Memory.
Como ROW é um formato interno do Spark, não há uma operação de adaptação na JVM para operar o Dataset.
Sabendo que PySpark e o próprio Spark possuem integração com a biblioteca Pandas, podemos utilizar o comando de criação de dataframe e passar para o Spark.

Note que na variável pandasFrame, chamei a biblioteca Pandas para criar o DataFrame. Porém, como as estruturas são diferentes, precisamos converter para o Spark dataframe.
Basta passar a estrutura pandasFrame para o Spark que ele converte.
NOTA: internamente pandas dataframe e spark dataframe são objetos diferentes. Embora o Spark aceite que seja criado, ele processa de forma independente, o que nos impede de utilizar funções com a API PySpark. Por isso, a conversão.
O interessante é poder imprimir o dataframe com a função toPandas(). Apesar de ser um pouco mais lenta que show(), porém, mais amigável.
Criação dinâmica de um dataframe com a função range. Apenas para teste, utilizando toDF().
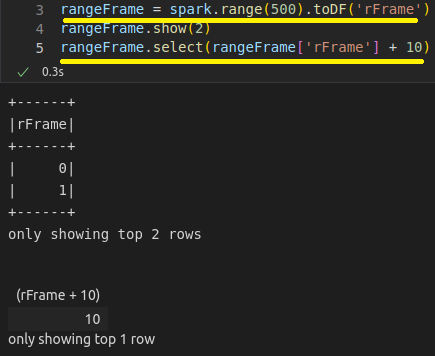
Com RDD, utilizamos o parallelize para criar um dataframe:

DATAFRAMES
Até aqui vimos como e quais as maneiras de se criar um dataframe. A partir de agora, vamos aprofundar e entender um pouco mais sobre esse objeto.
Dataframes e Datasets são estruturas tabulares otimizadas para trabalhar em memória.
Datasets são possíveis apenas nas linguagens baseadas em JVM (Java Virtual Machine), que são Scala e Java. Já nas linguagens que utilizam API, Python e R, utilizamos os Dataframes.
DIFERENÇA ENTRE DATAFRAME E DATASET.
Existe uma diferença entre Dataset e Dataframe que merece destaque aqui que é relacionado ao seu datatype ou schema.
Quando operamos um Dataframe, seja convertendo ou criando, podemos passar ou não o schema, muito antes da execução. Isso o torna uma estrutura schemaless. Porém, isso não ocorre com o Dataset.
Esse é um fluxo representativo que acontece quando o Spark recebe uma aplicação com a linguagem SCALA.
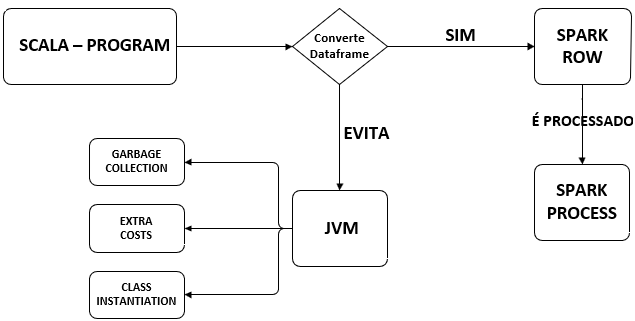
- Spark recebe uma aplicação em SCALA;
- Converte para Dataframe;
- Utiliza o datatype ROW para ler os registros do Dataframe;
- Envia para o Spark Process;
- Dados são processados;
- Trabalho é concluído evitando o custo extra envolvido na JVM.
Ao trabalhar com Dataset, eles são checados quando a estrutura é compilada. As informações ficam armazenadas na JVM.
Então, quando for trabalhar com as linguagens JVM, talvez tenha que dar mais atenção à questão do schema.
COMO SPARK COMPUTA UM DATAFRAME E DATASET.
Para manipular e manter todas as informações necessárias da operação, existe um componente interno do Spark chamado Catalyst.
Na operação dentro desse engine, ele vai utilizar um LOOKUPTABLE para mapear os os tipos de dados que está recebendo da linguagem de programação.
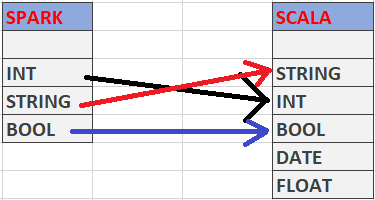
Então, quando ele recebe um comando de criação de Dataframe, acaba ocorrendo essa equiparação para que o Spark possa trabalhar com seus próprios datatypes.
OPERAÇÕES NO DATAFRAME: MANIPULAÇÃO DE COLUNAS E LINHAS
Por mais que o Dataframe ou Dataset sejam objetos ‘virtuais’ dentro do Spark, eles simulam todo o desenho de uma planilha CSV ou Excel.
Toda manipulação feita no Dataframe é considerada uma expressão, seja ela uma exclusão de coluna, seleção ou manipulação de dados.
Não existe forma de manipular linhas ou colunas fora de um Dataframe e além disso, utilizamos as transformações do Spark para alterar o conteúdo do objeto.
Na seção abaixo, vamos conhecer algumas funções e formas de manipulação de colunas do dataframe.
A primeira é com a função withColumnRenamed, que permite criar uma expressão com colunas existentes e renomeá-las ao final.
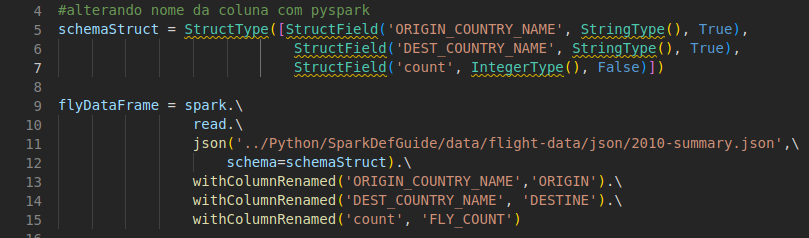
Também existe a opção com selectExpr, que é melhor utilizada quando há alguma função de agregação.

Como nos dataframes de Pandas, também podemos criar slices.
Sabendo que SQL é a linguagem franca e mais importante para trabalhar com dados, Spark e PySpark possuem diversos comandos que foram importados para o framework.
No exemplo abaixo, podemos selecionar colunas com select criar expressões com expr.
Destaco que expr só funciona quando há o select. Ele precisa atuar sobre uma das colunas selecionadas.

Veja o resultado das expressões acima.

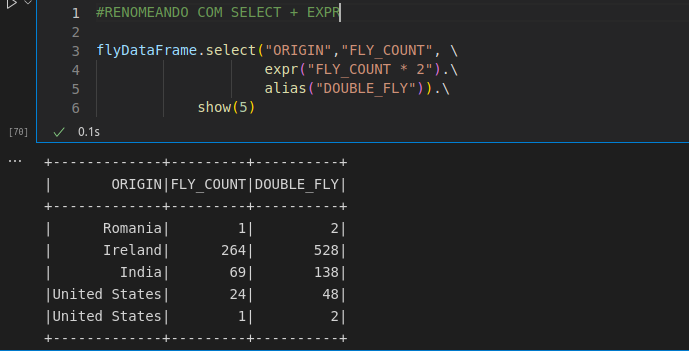
Outro exemplo do uso do select.

Caso queira criar diversas expressões de uma única vez, utilize o selectExpr. Note que em uma única função, eu seleciono as colunas do dataframe e crio as expressões com ela.
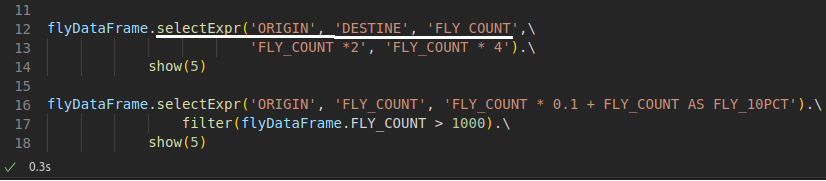
Veja na próxima imagem, o resultado das expressões acima.
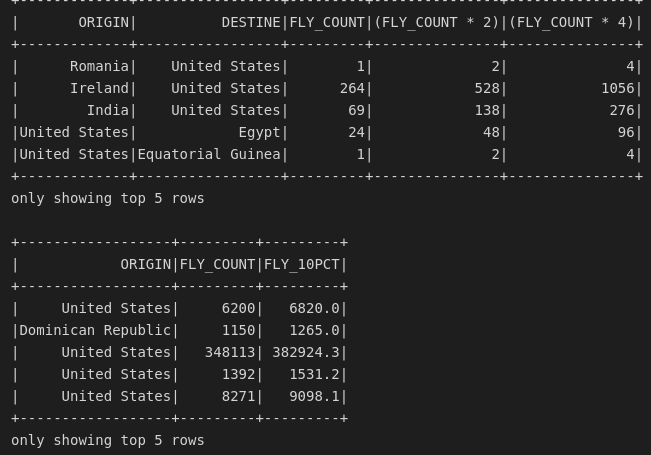
Caso queira renomear as colunas utilizando selectExpr, faça da seguinte forma.
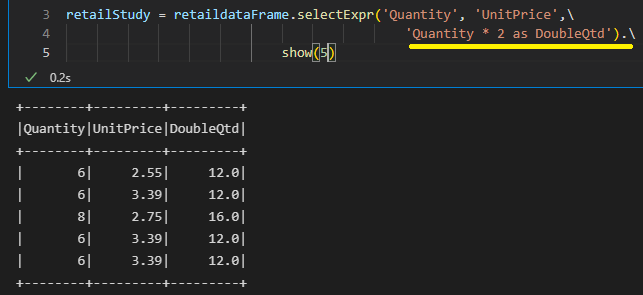
Ou podemos utilizar a função alias.
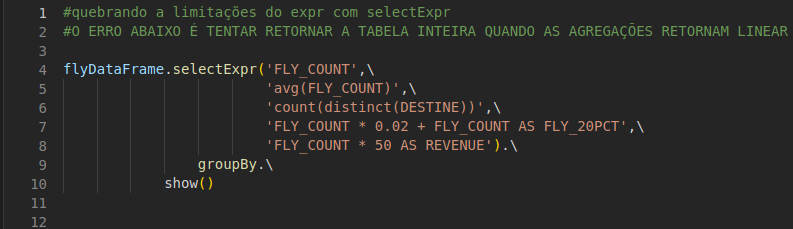
Cuidado com o selectExpr e as funções de agregação. Como elas seu resultado é linear, aplique a mesma regra para o GROUP BY do SQL.
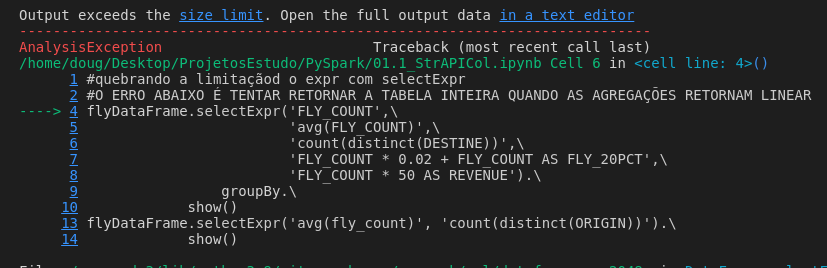
Mensagem de erro da função anterior.
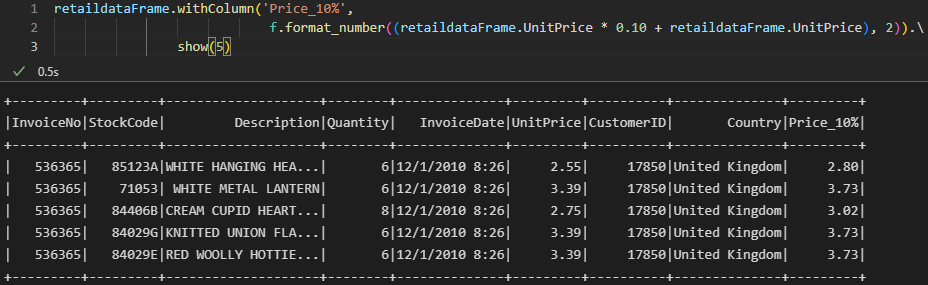
Das funções que selecionam colunas, a que mais gostei foi a withColumn. Além de permitir criar expressões, ela não renomeia com a fórmula da expressão como vimos em outros exemplos.

O segundo resultado foi renomeado pois utilizei a função withColumnRenamed.
Outra forma de utilizar withColumn é como um dicionário. Veja que primeiro eu passo o novo nome da coluna e após, a coluna e a expressão, adicionando inclusive, o formato de exibição do valor.
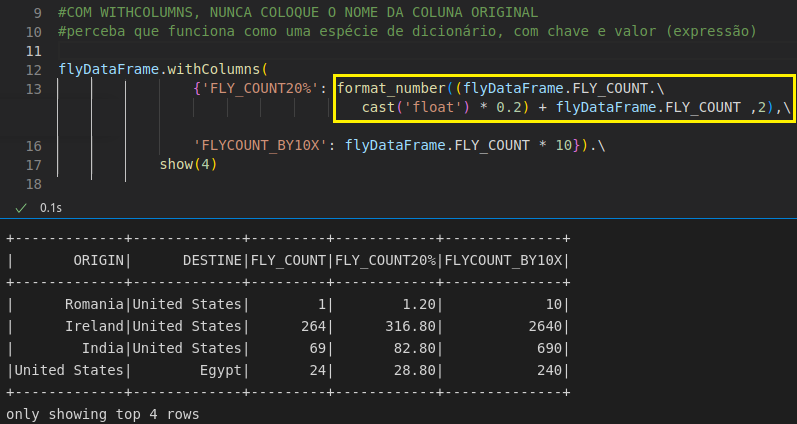
Entre o select e withColumns, eu achei e prefiro trabalhar com a segunda opção. Repare que o código é mais limpo e precisa de bem menos função.
O único problema é que ele não permite selecionar colunas específicas, retornando todas de uma única vez. Se não houver essa necessidade por colunas específicas, escolheria essa função.
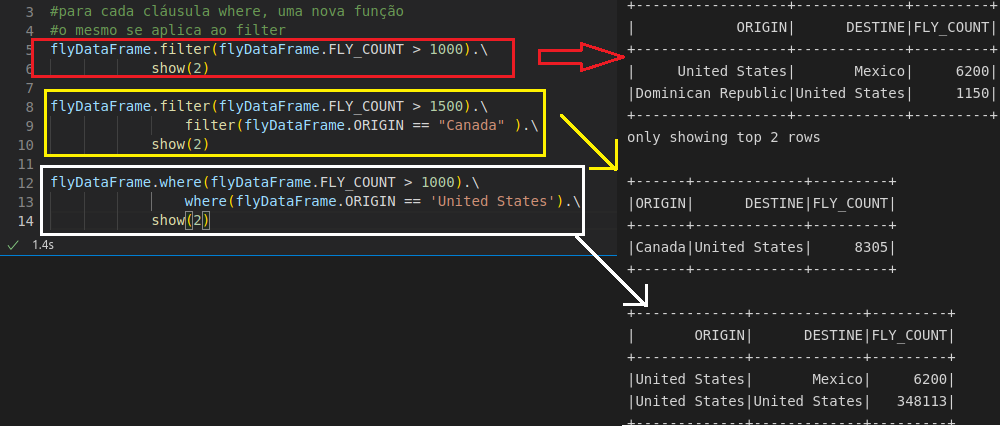
PySpark permite filtrar colunas com dois métodos muito conhecidos: filter e where.

Outros exemplos com filter e where.
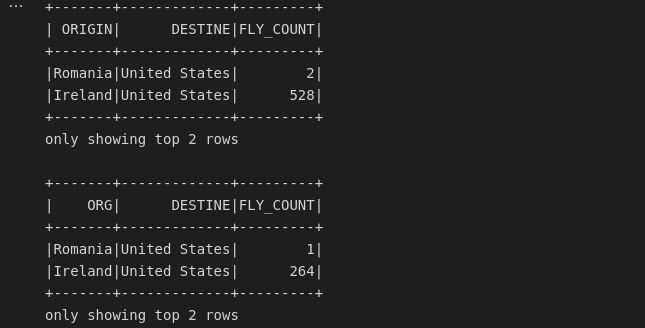
Assim como no banco de dados SQL, podemos unir dataframes com a função union.
Primeiro irei criar dois dataframes com dados diferentes para unir.
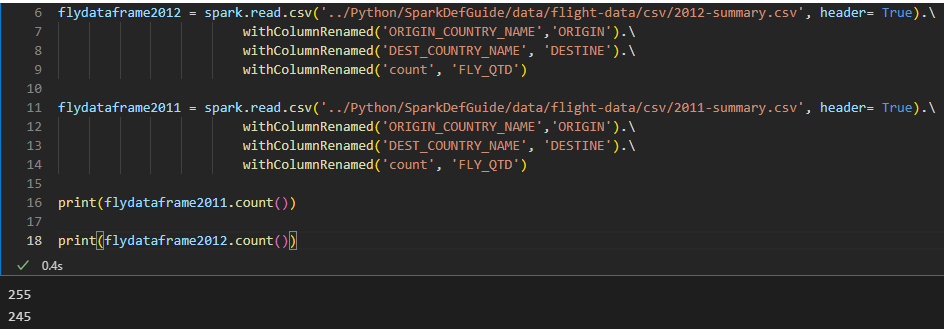
Note que cada dataframe possui uma quantidade de linhas diferentes.
É importante destacar que os nomes das colunas e os datatypes precisam ser iguais.
Unindo ambos.

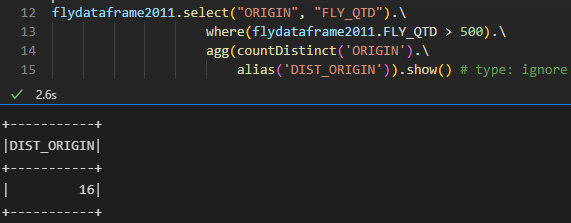
Por fim, existem duas formas de contar os valores distintos com PySpark no Spark.
Podemos simplesmente utilizar distinct:

Ou countDistinct.
OVERVIEW DA EXECUÇÃO DE UM DATAFRAME: ESTRUTURA BÁSICA
Vimos em tópicos anteriores o básico da manipulação de dados no Dataframe com PySpark.
Agora, vamos entender basicamente como funciona esse processo de transformação por debaixo da aplicação e dos códigos. Veja a imagem com o fluxo estruturado.
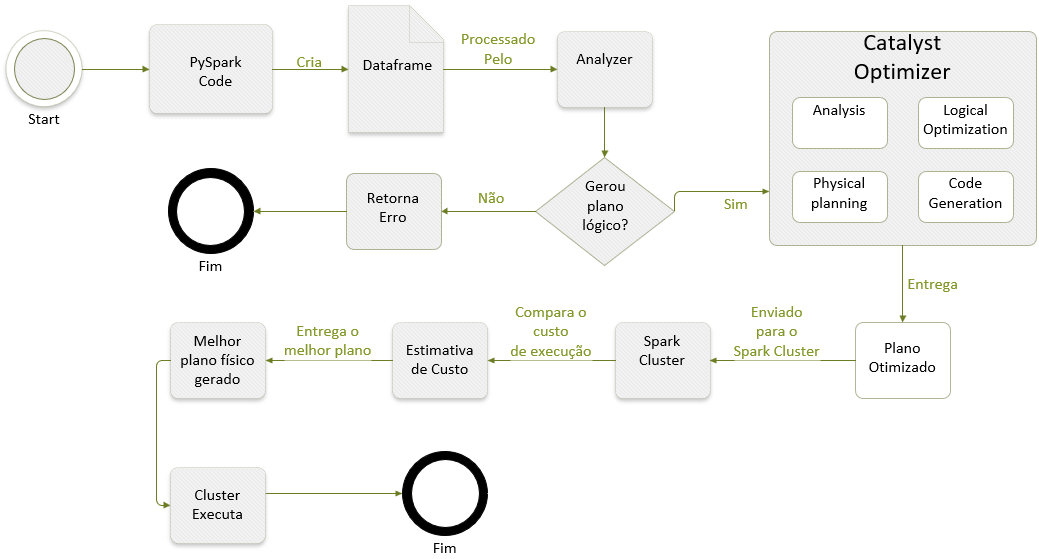
Quando o Spark recebe o código (PySpark) ele automaticamente cria o Dataframe e envia para o Analyzer avaliar e validar.
Se o Analyzer validar o código, ele envia um Logical Plan para o Catalyst Optimizer. Caso não consiga, retorna o erro e finaliza o processo.
Quando o Logical Plan chega no Catalyst Optimizer, ele passa por 4 etapas dentro do otimizador.
- Analysis → primeira fase do processamento e o Spark SQL engine começa gerando uma sintaxe abstrata em forma de árvore (AST). Outra ação que ocorre nesta etapa é a consulta ao catalog – uma interface do Spark SQL que contém tabelas, colunas, datatypes, funções e outros objetos que irão ajudar a validar o dataframe processado.
- Logical Optimization → compreendida por duas fases, sendo a primeira, a construção de diversos planos de execução com base em custo e atribuindo os custos para cada plano.
- Physical Planning → com o plano lógico otimizado criado, o plano físico é gerado pelo output do processo anterior. Esse plano otimizado é criado pelo Spark SQL engine e liberado para o Spark Execution.
- Code Generation → fase final do processo que possui o java bytecode com produto final para ser processado em cada máquina do cluster. Como o engine Spark SQL consegue trabalhar com datasets in-memory, ele acaba conseguindo acelerar o processo de execução nesta etapa.
Após as quatro etapas, o plano físico é gerado e enviado ao Spark Cluster para processar o dataframe.
Quando o plano com melhor custo de processamento é escolhido, o código é executado e o resultado entregue para o usuário.
TRANSFORMATIONS, ACTIONS & LAZY EVALUATION: TRANSFORMAÇÃO NO SPARK
Uma vez que vimos brevemente como um dataframe é processado pelo engine do Spark vou abordar rapidamente os conceitos de transformação ao qual, o objeto passa.
Toda a transformação do Spark ocorre como Lazy Evaluation, isso é, ele não ‘comita’ o processo ao fim do código, mas mantém a ação que uma Action seja executada.
NOTA: As actions são comandos como: show, toPandas, collect e etc.
Esse processo Lazy garante que caso uma ação não tenha o resultado desejado, ela pode retroceder ao ponto anterior ou até mesmo, estado original.
Outra vantagem que esse modo de processamento traz é na otimização das queries pelo engine, além da tolerância a falha e um lineage para ter acesso ao histórico.
Importante destacar que quando uma action é executada, o lineage se encerra e o dataframe é criado.
CONCLUSÃO
Este foi um artigo bastante extenso sobre a estrutura de dataframes dentro do Spark.
Quis abordar da melhor maneira possível como ele é criado e processado pelo framework de Big Data.
Consegui mostrar ao logo do post como criar transformações e expressões nas colunas e os principais comandos para criar análises dentro da ferramenta.
Abordei brevemente como um dataframe é processado pelo engine interno e o motivo dele ser tão rápido.
Por fim, uma breve explicação sobre as transformações e o modo de operação básico da ferramenta, o Lazy Evaluation.
E caso queria acessar o mapa mental com os principais comandos PySpark, clique aqui!
OLÁ!
Se chegou até aqui e gostou do pequeno tutorial, deixe seu like e compartilhe. Ajude a crescer esta comunidade!
Muito obrigado!

