

Com a explosão do Big Data e a quantidade massiva de dados sendo gerada diariamente, uma solução tecnológica era necessária para processar todo esse montante. Vos apresento o Spark.
Com essa necessidade cada vez mais latente, surgiu um framework de processamento chamado Spark, que é uma ferramenta open-source desenvolvida para processar dados em memória, garantindo a velocidade, escalabilidade e entrega para as partes interessadas.
Abrindo a categoria Spark aqui no blog, nesse primeiro artigo, irei tratar das bases internas da ferramenta e como ela está organizada para processar dados em alta velocidade.
Então, vamos iniciar o assunto para uma das ferramentas mais utilizadas na engenharia de dados. Se quiser conhecer um pouco mais sobre o tema, recomendamos o post Engenharia de Dados: uma abordagem menos técnica.
NOTA: Não estou utilizando o software para construção desse artigo, apenas construindo os códigos utilizando a biblioteca PySpark no meu visual studio. Baixe-o aqui.
Introdução
O conceito inicial do Spark veio com base em três aplicações diferentes criadas pelo Google e outra que foi desenvolvida nos laboratórios de pesquisa da Yahoo!.
Na época, o Google havia desenvolvido o File System (GFS), Big Table e o MapReduce. Esse trio de programas tinham os seguintes objetivos:
- File System (GFS) → criar um sistema de tolerância a falhas através de uma fazenda de clusters de computadores com hardwares baratos.
- Big Table → sistema de armazenamento desenhado para ser altamente escalável e arquitetado para armazenar os dados estruturados do File System.
Com o armazenamento e a tolerância a falhas desenhadas e operando, faltava processar toda essa quantidade de dados armazenados e para isso, surgiu o MapReduce.
- MapReduce → surgiu como solução aos clusters aplicando programação paralela de processamento distribuído.
O esquema de processamento antigo era basicamente nesta estrutura.
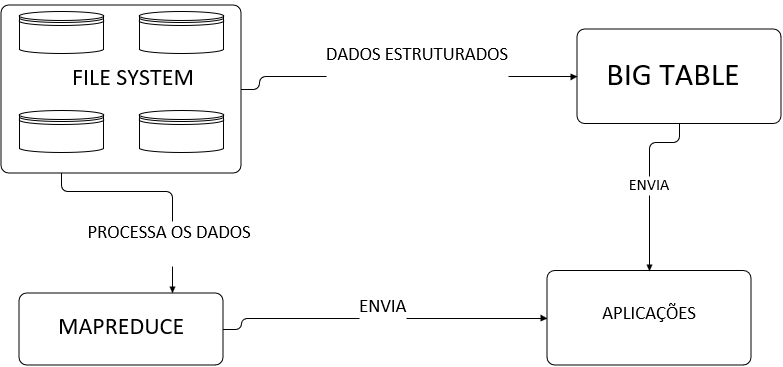
Essa estrutura foi base para a criação do Hadoop MapReduce, pelos laboratórios da Yahoo!. Logo após, surgiram outros softwares que passaram a compor o ecossistema Hadoop, como o Hive e o Storm.
Ainda que a solução atendesse aos requisitos da época, era considerada lenta e problemática, principalmente para administrar. Com esses prós e contras no jogo, em 2009 surge a tecnologia Spark.
Criação do Spark
Criado para ser rápido, simples e fácil, logo nos seus primeiros dias a ferramenta atendeu prontamente os desejos dos seus idealizadores. Se provando entre 10 a 20 vezes mais rápido do que o Hadoop MapReduce, ela adquiriu usuários em larga escala, se tornando a principal ferramenta de processamento de Big Data.
O conceito inicial do Spark veio com base em três aplicações diferentes criadas pelo Google e outra que foi desenvolvida nos laboratórios de pesquisa da Yahoo!.
Avançando para os dias atuais, ele ganhou novos componentes que otimizaram seu processamento. O que antes era apenas um modelo de programação similar ao MapReduce, com a adição de um componente chamado RDD, (Resilient Data Distributed), ele agora evoluiu para um software que processa desde queries em SQL até Grafos, passando por Machine Learning.
NOTA: RDD é uma camada de abstração que permite o Spark capturar uma alta variedade de workloads que antes seriam processados separadamente.
E quais foram os benefícios reais que o Spark trouxe para o mundo dos dados?
- Facilitou o desenvolvimento de aplicações uma vez que ele possui uma API unificada;
- O processamento passou a ser em memória e multitarefa, excluindo inclusive, a necessidade de escrita em disco antes de passar para outro processo.
Spark e a Stack Unificada
Unificação é a palavra-chave dentro do Spark e quando ele foi concebido, criou-se uma stack de componentes dentro de um único software, o que ficou conhecido como a stack unificada do Spark.
Os criadores agruparam diversas bibliotecas dentro da ferramenta, com API’s de integração que facilitam o trabalho.
Desse modo, podemos escolher a linguagem que mais dominamos, sendo Python, Scala, Java ou R e trabalhar com uma delas utilizando a API estruturada.
Independente da linguagem, seu código será decomposto em bytecode e executado pelos workers gerenciados pela JVM através dos clusters.

Stack unificada do Spark e suas bibliotecas.
Uma boa demonstração é criar uma pequena aplicação que lê uma stream do servidor local e escreve em uma aplicação de streaming de dados, como a Kafka, por exemplo.
Perceba que na aplicação, eu passo a origem da leitura e o destino da escrita. Como basicamente todo processo de ETL.

Ao final, se executar um print da variável query, verá que essa aplicação foi fixada em um endereço de memória.

Mas se quisermos entender de fato como essa pequena aplicação foi processada, precisamos entender como o internals do Spark funciona.
Spark: Execução Distribuída e como ela se organiza
Os criadores então, agruparam diversas bibliotecas dentro da ferramenta, com API’s de integração que facilitam o trabalho. Desse modo, podemos escolher a linguagem que mais dominamos, sendo Python, Scala, Java ou R e trabalhar com uma delas utilizando a API estruturada.
Já entendemos que o Spark é uma ferramenta de processamento distribuído e funciona através de APIs que enviam aplicações para processarem dados armazenados.
Para que tudo isso funcione perfeitamente, existem três principais componentes que gerenciam todo o trabalho interno, são eles:
- Spark Driver → é o responsável por instanciar a sessão criada com o SparkSession.
dentro da ferramenta, possui algumas tarefas como:- Comunicação constante com o Cluster Manager para requisitar recursos como memória e CPU;
- Aloca os recursos de hardware nos executores (JVM);
- Transforma as operações em DAGs que serão agendadas e enviadas para os executores trabalharem com elas como se fossem tasks.
- SparkSession → é como o core principal desses três componentes. Ele fornece uma espécie de canal único para todas as operações de dados. Através do SparkSession, criamos e acessamos os seguintes recursos dentro do Spark:
- Criamos a JVM e os parâmetros de execução;
- Criamos DataFrames e acessamos Datasets;
- Leitura de fontes de dados;
- Acesso ao catálogo de metadados;
- E por fim, edição de queries com o SparkSQL.
- Spark Application → é um driver programável que é responsável por orquestrar as operações em paralelo do cluster que o Spark se encontra.
NOTA: na realidade, as DAGs que o SparkDriver converte após receber aplicação são vistas como Tasks pelos executores dentro do Spark.
Na imagem abaixo, veja como construir uma SparkSession.
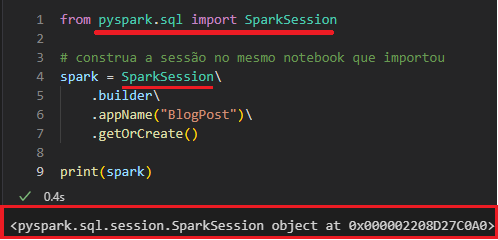
Exemplo de construção de sessão utilizando o SparkSession. Agora, a partir da variável Spark, eu posso manipular dados como quiser, veja.
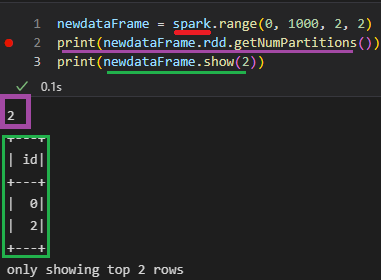
O que foi feito no código acima:
- Criado uma variável que irá armazenar um DataFrame;
- Chamei a variável Spark (contendo a SparkSession) e utilizei a função range passando:
- O número inicial;
- Número final;
- Step, irá contar de 2 em 2 números;
- E por fim, o número de partições que esse dataframe irá trabalhar.
- Utilizei o print para confirmar que somente duas partições foram atribuídas ao dataframe;
- Printei o resultado do dataframe.
Visto alguns conceitos importantes do Spark, vamos avançar e entender a sua arquitetura interna e como ele processa as transformações com seus recursos.
Arquitetura e Conceitos da aplicação Spark
No tópico anterior entendemos alguns dos principais componentes para o funcionamento do Spark. Compreendemos que a aplicação é construída através de uma de suas API’s e que o driver envia para os executores processarem.
Além disso, sabemos que a SparkSession é instanciada pelo driver e é ela quem permite a programação de aplicações no Spark através das APIs.
Uma breve olhada no código, podemos ver isso:

Sem instanciar a sessão através da SparkSession, não conseguimos acessar as bibliotecas de manipulação necessárias.
E como tudo isso é processado internamente? Veja a imagem abaixo!
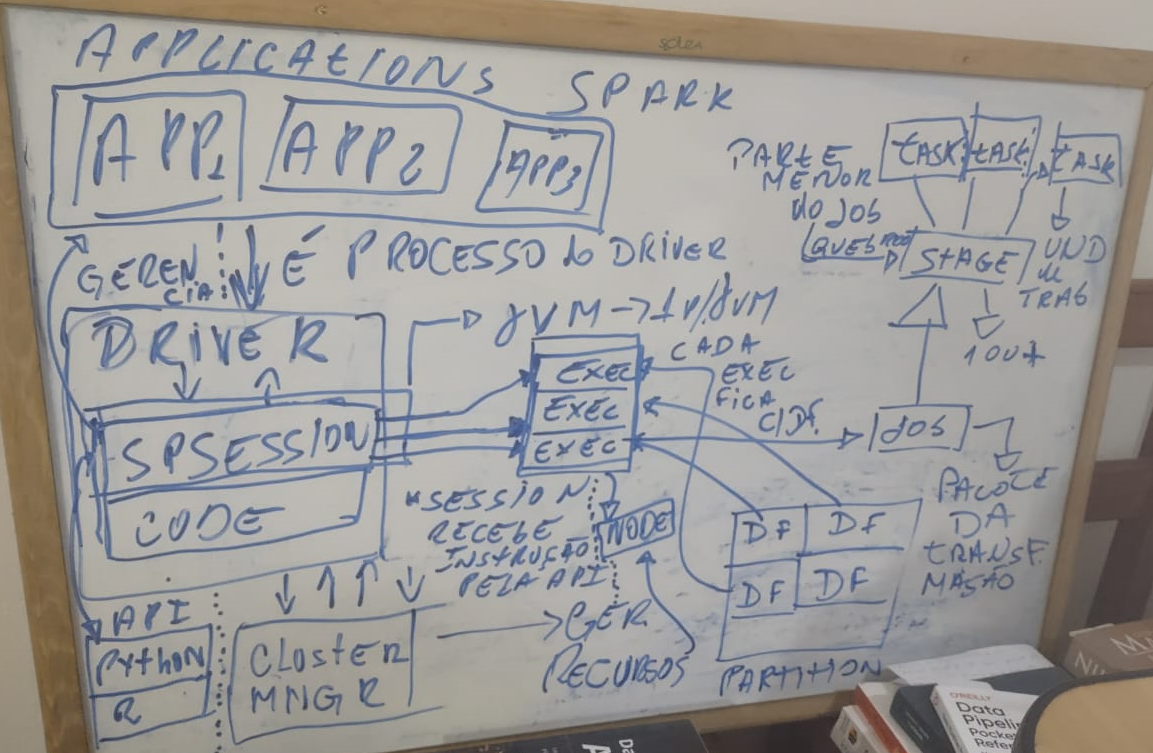
Essa é a forma mais bagunçada de transformação, mas não está errada. Vamos torná-la um pouco mais agradável para compreensão e leitura!

Agora vamos destrinchar o processamento da forma mais sequencial possível, ainda que não traduza 100% a realidade dentro da ferramenta. Siga abaixo:
- Quando executamos o Spark através do Spark-Shell, o que temos ali é apenas o SparkDriver funcionando.
- Com o driver operando, abrimos a conexão criando o Spark-Master e o Worker.
- Com os ‘operadores’ criados, conectamos utilizando o endereço do Spark-Master.
- Uma vez conectado, a aplicação criada na Session aparecerá na interface gráfica do Spark Web – que permite gerenciar as operações.
- Com o Driver iniciado, podemos criar a SparkSession utilizando uma das quatro linguagens dentro do Spark.
- Quando a Session é finalmente instanciada, lhe é atribuída uma JVM (Java Virtual Machine) que irá traduzir seu código criado na aplicação em bytecode para o Driver.
- A sessão é criada pela Aplicação, se tornando um objeto instanciado e gerenciado pelo SparkDriver.
- O Driver fica no intermediário, entre a aplicação e a session, e o acessa através da variável “spark”.
- Com a SparkSession criada, passamos a programar utilizando a API, criando nossas operações.
- Quando finalizamos e enviamos a aplicação criada para o processamento, a JVM traduz para código de máquina (bytecode), enviado para o Driver.
- O Driver converte a aplicação em Jobs, podendo ser um ou mais e estes se tornam DAG’s (Directed Acyclic Graph – Grafos não Acíclicos).
- Os Stages são criados a partir das DAGs do processo anterior. O Spark avaliará se serão necessários mais de um Stage para trabalhar com aquela transformação.
- Esses Stages são como containers de Tasks de processamento. Entendido a “unidade” de trabalho que cada Stage terá, as Tasks são atribuídas a cada unidade de particionamento, Data Partitions, que serão acessadas pelos Cores dos Executors.
- A relação fica da seguinte forma: 1 Task — 1 Partition — 1 Core.
IMPORTANTE: a partição pode receber tasks que vão de 32 até 128MB. Essa condição pode ser um problema quando temos tasks muito pequenas que não ocupam a partição inteira.
Agora que destrinchei como o Spark se organiza e processa as operações, vamos ver todo esse sequenciamento na prática.
Processo Spark Prático: Criando Sessão e Transformando DataFrame
Para mostrar de forma ilustrada tudo que está escrito acima, abri uma máquina virtual no meu computador e fiz passo a passo.
O primeiro processo é acessar a pasta que o binário do Spark Master e Worker se encontram para executá-los.
Na imagem abaixo, vou ao diretório Sbin do Spark e executo o start-master.sh.
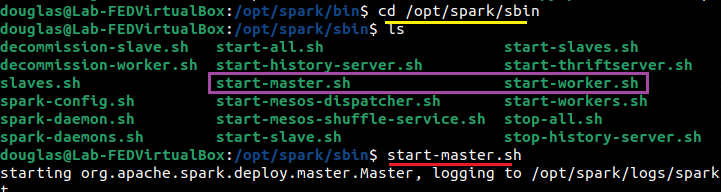
Com o Master iniciado, precisamos do endereço e porta que ele está utilizando para conectar os Workers.
Em vermelho, a URL que utilizaremos para conectar os Workers. Perceba que não há nenhum conectado ou operando.
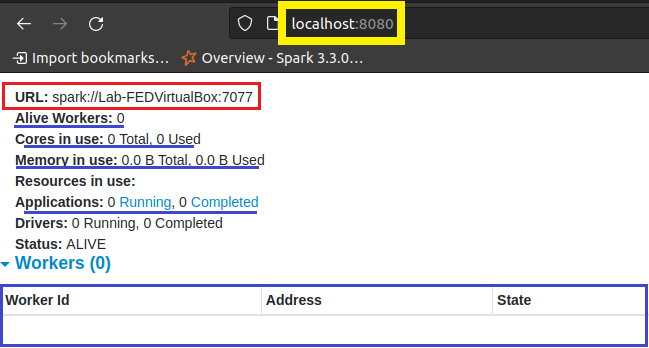
Utilizando o comando para conectar o worker no master. Veja que ao lado do comando, passei a URL indicando o caminho que ele deve seguir.

Agora, com o worker conectado, veja a mudança no painel de controle do Spark.
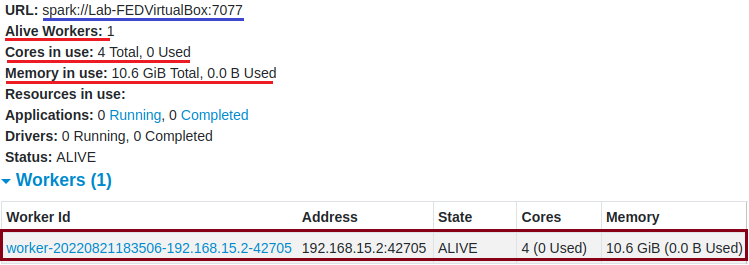
Perceba que ele captura a quantidade de cores que meu processador possui e a memória alocada para a Virtual Machine.
Agora já temos a instância Master e o Worker conectados e prontos para receber a Session do Spark e as transformações.
Com os pré-requisitos concluídos, abro o Visual Studio e, dele, conecto o PySpark (biblioteca que utilizarei para criar as aplicações de processamento) ao Spark Master, assim como fizemos com o Worker.
A partição pode receber tasks que vão de 32 até 128MB. Essa condição pode ser um problema quando temos tasks muito pequenas que não ocupam a partição inteira.
Primeiro vá ao diretório ao qual o binário do Pyspark se encontra.
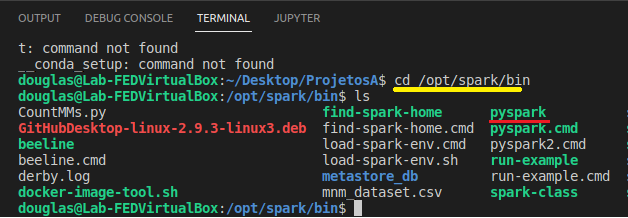
Basta executar o comando passando a url que desejamos conectar.

Spark conectado com a biblioteca Pyspark no Master e Worker. Veja que o próprio painel indica que utilizei o PySparkShell.

Agora, teoricamente poderíamos acessar a UI de visualização e controle dos Jobs e transformações do Spark, mas antes, precisamos da SparkSession instanciada.
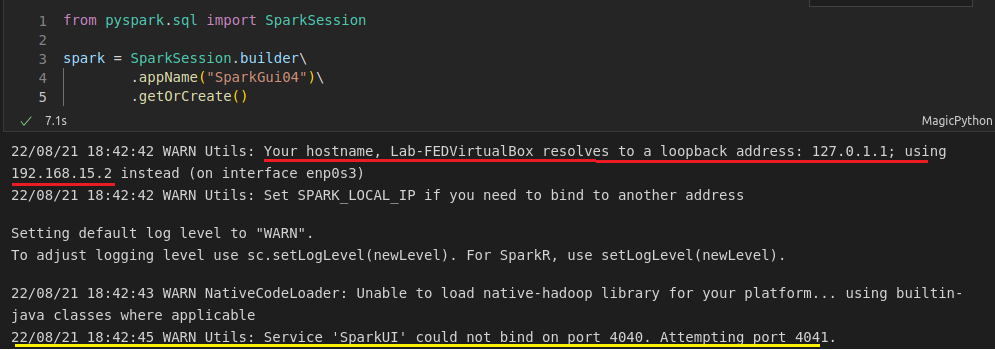
Acessando o localhost com a porta indicada, temos a interface gráfica de controle dos Jobs e Tasks.
Perceba que na aba do navegador, o nome que aparece é exatamente o mesmo que atribui à aplicação quando criei a Session.

Para o teste, executei esse arquivo em Jupyter no Visual Studio. Baixe-o aqui.
Na imagem abaixo, as transformações que foram executadas foram registradas na aba de Jobs e veja que em alguns, ele dividiu em 4 tasks enquanto outras, apenas uma.

Outro ponto interessante da ferramenta é a possibilidade de analisar o plano de transformação que o Spark utilizou.
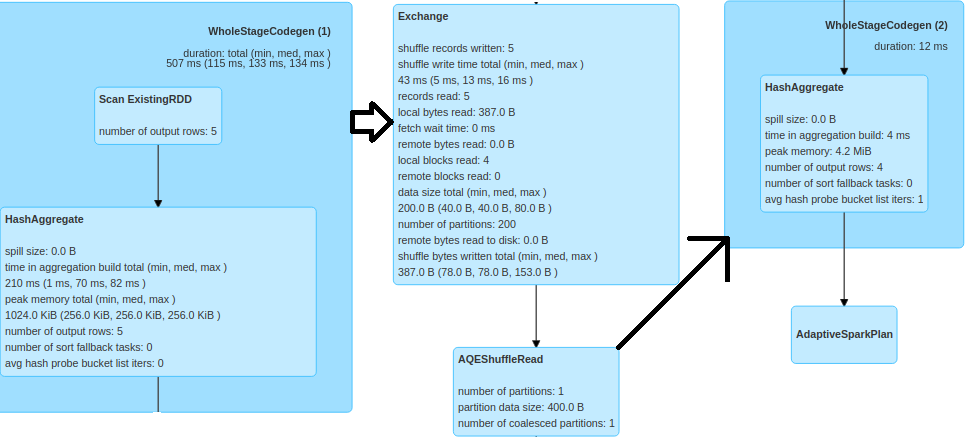
E por fim, o resumo dos Stages criados pelos Jobs.
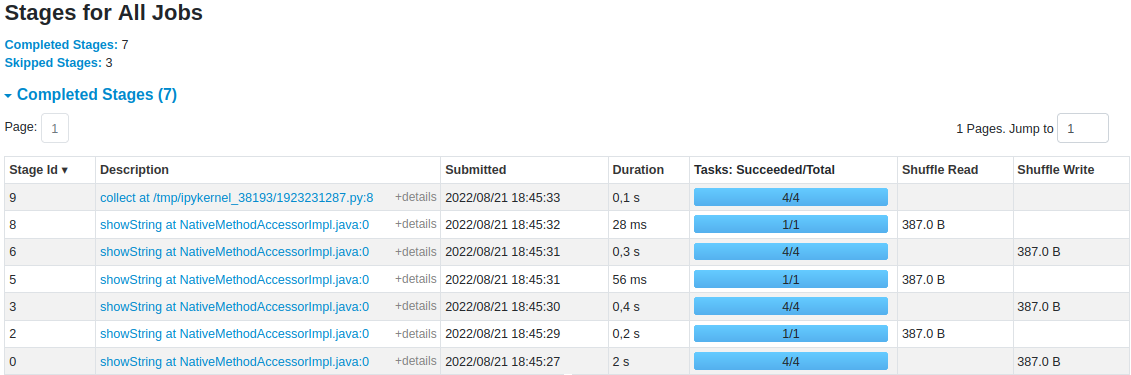
Informações dos jobs finalizados na GUI do Spark.
Como podemos ver, além do processamento massivo de dados, a ferramenta entrega bastante recurso de monitoramento e otimização de tarefas processadas.
A solução de processamento de Big Data é bem completa e atende todos os requisitos necessários para obtermos valor na ponta final do ambiente de dados.
Conclusão
Esse foi meu primeiro artigo sobre o Spark e como ele funciona. Tem um mês ou um pouco mais de estudo simplificado e ainda assim, será dividido em duas partes.
Faltou falar sobre as transformações e os processos que ocorrem até a entrega, que serão tratadas no próximo artigo; continuação direta desse.
Deixo claro que meu ambiente roda em single node (standalone), então, tenho apenas uma JVM no ambiente. Ainda não aprendi a configurar o Spark em cluster, mas em breve isso será resolvido.
Se chegou até aqui e gostou do post, deixe seu like e se possível, compartilhe com sua rede! Ajude a nossa comunidade a crescer. E se você quiser conhecer mais sobre a nossa proposta, acesse o post de apresentação do BRAINS – Brazilian AI Networks.


1 comentário