Aqui estamos novamente para dar continuidade à nossa série de posts que começou no Engenharia de Dados: uma abordagem menos técnica, onde iniciamos nosso primeiro bate-papo dando uma introdução sobre como é a área de Engenharia de Dados e de que forma o Engenheiro de Dados atua.
Hoje, seguiremos abrindo mais um tópico, onde iremos falar sobre as três soluções de armazenamento de dados. Soluções estas que estão presente em praticamente todos os projetos que envolvem dados.
Como podemos definir um Data Warehouse?
O que seria um Data Warehouse (DW), ou Armazém de Dados? Sim, utilizamos a palavra “Armazém”, mas por quê? Pois seria como traduziríamos livremente o termo Warehouse, do Inglês.
Agora que temos a tradução da palavra, qual o real significado do termo? Segundo o site de significados online dicio.com, a palavra Armazém seria um lugar, um depósito, onde se guardam mercadorias por tempo limitado. Bem, a partir daí traremos isto para o nosso contexto de dados.
Os Data Warehouses, nossos Armazéns de Dados, são repositórios unificados onde são armazenados uma abundância de dados, tendo diversas fontes diferentes. A imagem abaixo ilustra com clareza uma representação da solução.
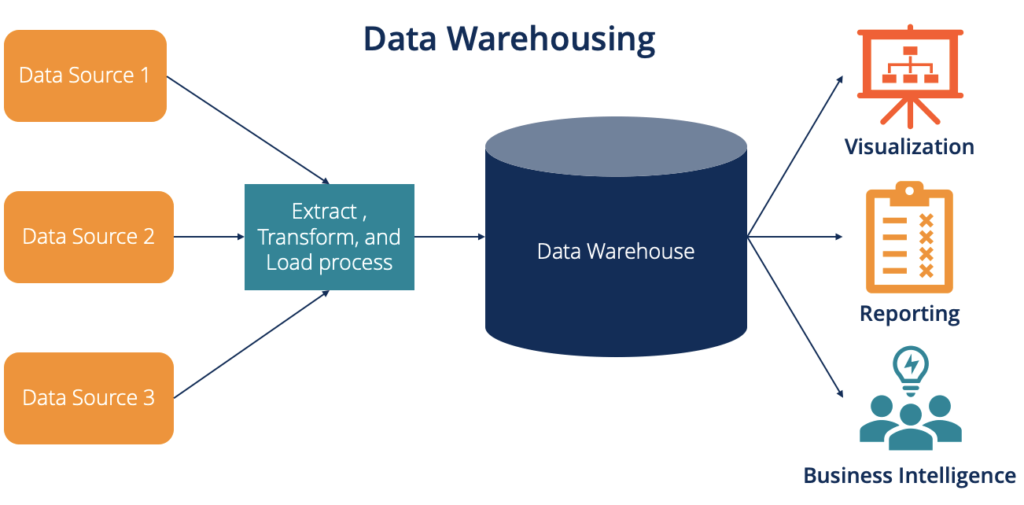
No primeiro conjunto de blocos laranjas temos o que seriam as fontes de dados. Como dito anteriormente, podem ser de diversas fontes, como por exemplo SAP, ERP, bancos de dados, entre outras.
Logo após, temos o segundo bloco, em azul-claro, onde temos o processo de ETL (Extrair, Transformar, Carregar). Falamos sobre ETLs no post Pipelines e o Processo de Engenharia de Dados, onde abordamos etapas do processamento de dados.
E em seguida, em azul-escuro, temos o bloco do DW em si. O responsável por ser o depósito dessas diversas fontes que já foram tratadas. Na sequência o conteúdo do Data Warehouse será disponibilizado para as áreas envolvidas.
O consumo do DW são nossas últimas representações do esquema, que contém áreas como BI (Business Intelligence, ou Inteligência de Negócios), Reporting (reportes e relatórios) e Visualization (visualização dos dados).
Os DWs servem como componente de fonte central para consultas de relatórios e entrega de dados às áreas de negócios. Como os dados já estão tratados e disponíveis, a conexão com o DW acaba sendo bem rápida e tendo um ótimo desempenho.
Vantagens e desvantagens
Os Data Warehouses são amplamente utilizados em muitos setores, incluindo varejo, finanças, saúde, telecomunicações e muitos outros.
Boa parte dos Data Warehouses são mantidos on-premises, ou seja, na própria infraestrutura da empresa. Eles são especialmente populares em empresas que precisam gerenciar grandes volumes de dados e realizar análises complexas para tomar decisões estratégicas.
Porém, com a evolução de soluções de armazenamento de dados, como Data Lake e Data Lakehouse, algumas empresas estão migrando seus Data Warehouses para a nuvem, o que permite escalabilidade e flexibilidade, além de reduzir custos.
Ainda é comum que empresas usem Data Warehouses. Mas a tendência é de migração para soluções mais flexíveis e escaláveis e a adoção de soluções em nuvem.

Podemos dizer que, com o passar do tempo, os DWs acabam se tornando um “luxo”. Pois armazenar tantos dados históricos exige um alto processamento, o que acaba se tornando muito caro.
Além disso, como dito, essa solução ainda é amplamente usada de forma on-premises. Portanto necessita de manutenções e atualizações constantes, pois dependem de infraestrutura interna que muitas vezes pode não atender a demanda suficiente.
Em um determinado momento esse modelo de armazenamento pode acabar se tornando um gargalo. Sua falta de flexibilidade torna-se um impeditivo para alcançar análises em um contexto de Big Data atual.
Data Lake
Para começarmos a explanar sobre os Data Lakes, temos que entender o porquê de seu nome. Isso acaba sendo muito importante, pois trazemos para um contexto mais próximo da nossa realidade, muitas vezes simplificando a explicação de algo que para muitos pode ser técnico demais.
Utilizando uma tradução livre e direta do termo Data Lake, temos Lago de Dados.

É isso mesmo que eu entendi? Lago? Um lago pode ter peixes de diferentes tipos ou animais das formas mais variadas, e é bem isso que temos dentro do nosso Data Lake.
Temos dados de diversos tipos e formas, sendo eles imagens, vídeos, textos, arquivos de sistemas como logs, tabelas, compactados ou descompactados. Toda essa variedade que torna o Data Lake uma boa prática para lidar tanto com o volume quanto com a variedade dos dados.
Menor custo e pós-processamento dos dados
Os Data Lakes são um repositório de dados, onde temos alta flexibilidade. Diferente do Data Warehouse, onde usamos o processo de ETL, podemos utilizar os processos de ELT. Assim carregamos os arquivos primeiro, mantendo sua forma bruta e não os alterando. Caso surja a necessidade de voltar em um processo anterior ou tirar novos insights, nossos dados originais estarão lá.
Mesmo com o passar do tempo, os Data Lakes se mostram mais flexíveis, duráveis e econômicos (se bem administrados) por usar computação em nuvem. Os processos executados são feitos e cobrados por demanda. Então, dependendo do seu consumo e de uma boa administração, dificilmente irá custar mais do que o modelo de armazenamento que citamos anteriormente.
Nesse ambiente, onde podemos atuar com diferentes formatos de dados, não ter a necessidade de definir o schema na hora da sua criação abre novas possibilidade para trabalhar com estudos de Ciência de Dados e Machine Learning.
Um exemplo que podemos dar é a análise de fichas médicas e radiografias, com base em pacientes anteriores, para prever se um novo paciente irá desenvolver ou já desenvolveu uma doença específica. Seria um modelo preditivo baseado em dados anteriores.
Data Warehouse vs Data Lake
Na imagem abaixo, adaptada do site da Salesforce, fazemos a comparação dos Data Warehouses vs Data Lakes. A imagem por si só já explica muita coisa, mas vamos juntos entender melhor.
Com a evolução das soluções de armazenamento vemos que o Data Lake surgiu para atender tudo aquilo que era limitado na solução DW. Assim, saímos da capacidade computacional escalável de Gigabytes para Terabytes, ou até mesmo Petabytes. Passamos a trabalhar com os mais variados tipos de dados (estruturados, semiestruturados e não estruturados).

Desvantagens e pontos de atenção
Como grande parte das tecnologias sempre temos um ponto, ou mais, de atenção que devemos ter cuidado ao utilizá-las. Quando temos um ambiente de armazenamento Data Lake, surgem dois alertas.
- Devemos tomar cuidado ao utilizar dados nos conectando direto com ferramentas analíticas. Estamos trabalhando com um volume de dados muito grande e, se não nos atentarmos para isso, podemos acabar onerando um processamento de dados que talvez não fosse necessário.
- Precisamos também ter cuidado com dados confidenciais. Como estamos trazendo nossos dados direto para o Data Lake e armazenando na sua forma bruta, nossos dados podem estar expostos e sem mascaramento. Isso pode facilitar ações ilícitas com dados que podem muitas vezes ser confidenciais.
Data Lakehouse
Bem, sei que o este post está um pouco longo. Mas, se chegou até aqui, deve estar bem satisfeito como o que conseguimos entender sobre as soluções de armazenamento.
Falamos primeiramente dos Data Warehouses. Passamos pelo Data Lakes. E, por último, mas não menos importante, os atualmente famosos Data Lakehouses.

Na imagem acima podemos ver que com o passar do tempo, migrar o modelo de armazenamento acabou se tornando em muitos casos uma necessidade. Tudo irá depender, é claro, do seu modelo de negócio e de que análises quer desenvolver dentro da sua empresa.
Em um primeiro momento vemos que o Data Warehouse atendia muito bem. Mas, chegou em um ponto que surgiu a necessidade de realizar análises mais aprofundadas. Modelos preditivos e análises em tempo real foram grandes motivadores para a evolução para o Data Lake. Em seguida, temos uma nova onda com mais velocidade ainda, cobrando mais qualidade de dados e consistência.
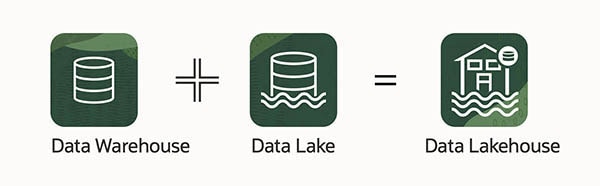
Novamente surgiu uma nova solução de armazenamento para sanar uma nova necessidade do mercado. Chamamos esta nova solução de Data Lakehouse. Uma união entre o “Lake” e o “Warehouse“. Conseguimos assim extrair o melhor dos dois mundos.
Com isso, percebemos novamente o que viemos falando em posts anteriores: a tecnologia sempre se vê em mudança. Ou seja, temos movimentos cíclicos que nos empurram a atualizar os modelos de negócio.
Uma solução para resolver novos problemas
Então entendemos o que o conceito de Lakehouse surge para unir esses dois mundos. Propondo uma solução analítica de dados que consiga resolver problemas de negócios desde os mais simples até os extremamente complexos. Conseguimos agora atender aos casos de uso de IA (Inteligência Artificial) e ML (Machine Learning).
Com o uso do Data Lakehouse, podemos analisar dados tanto em batch (dados em lote) quanto em streaming (dados em tempo real). Podemos ter, ou não, um schema predefinido. E podemos cobrir o uso de dados estruturados, semiestruturados e não estruturados. Bem como suportar também tecnologias de BI, garantindo a segurança dos dados e a facilidade de uso para usuários não técnicos.
Por isto vemos tanta inovação com o uso do Data Lakehouse. De acordo com o blog estrangeiro Deep Talk, com a quantidade de dados não estruturados que temos no mundo, surgem novos desafios de como tratá-los. No artigo 80% of the world’s data is unstructured, vemos que 80% dos dados hoje no mundo vem de arquivos não estruturados, que podem ser das mais diversas extensões.
Temos o desafio de como lidar com esses novos problemas.
Opções de Lakehouse disponíveis no mercado
Como qualquer movimento de mudança também vemos grandes empresas se posicionando e lançando plataformas evoluindo os seus conceitos anteriores.
Quando falamos de Data Lakehouse, num primeiro momento, já lembramos da emblemática Databricks – empresa que trouxe este conceito e vem conquistando de forma exponencial as corporações e empresas que querem ir para Cloud (Computação em Nuvem).
Porém, temos algumas outras opções mercado, como Azure Synapse Analytics da Microsoft, SnowFlake, AWS da Amazon, GCP da Google.
Plataformas baseadas em nuvem que oferecem armazenamento quase ilimitado e amplo poder de processamento. Isso permite que os usuários extraiam e carreguem todos e quaisquer dados de que possam precisar tanto em lote ou com trabalhos em tempo real.
As plataformas de nuvem transformam os dados para qualquer caso de uso. BI, análise ou modelagem preditiva, e quase qualquer outra finalidade. Explorando um universo de possibilidade com menor custo e até mesmo menor manutenção.
Conclusão
Bem, acredito que com o post de hoje conseguimos entender melhor os diferentes conceitos de armazenamento de dados e como eles tiveram que ir se modificando com a evolução do formato, tamanho e velocidade dos dados.
Com certeza a corrida de inovações está bem longe de acabar e veremos mais avanços ainda. Cabe a nós entendermos o modelo que melhor se adequa ao nosso modelo de negócio e implementá-lo com eficiência e sempre buscando o melhor custo-benefício.
Esta é a continuação de uma série de postagens falando sobre Engenharia de Dados, caso queiram rever algum episódio anterior, vou deixar os links abaixo para você acompanhar e rever algum tema que talvez não tenha ficado tão claro aqui. Inclusive, caso queira entendendo melhor os processos de ETL ou ELT visite o segundo post.
Post 1: Engenharia de Dados: uma abordagem menos técnica
Post 2: Pipelines e o Processo de Engenharia de Dados
Esperamos que tenham gostado bastante deste artigo e com toda certeza queremos que volte para ler mais sobre esta série de postagens, que achamos que está ficando muito legal.
Espero ter despertado a sua curiosidade e conto com seu comentário para saber a sua opinião e que dúvidas ou sugestões que teria sobre os temas que vimos aqui. E se estiver gostando da nossa comunidade, conheça um pouco mais sobre nós e nossos objetivos de fortalecer a comunidade brasileira de dados no post BRAINS – Brazilian AI Networks.


