

No primeiro post da revisão sobre as Window Functions, abordei os conceitos básicos, como ela é criada pela linguagem SQL e seu processamento lógico pelo engine do banco de dados.
Aprofundando sobre o assunto e continuando o anterior, neste, quero tratar sobre como as funções analíticas se comportam e como podemos extrair melhores análises e modelos com estas ferramentas.
Window Aggregate Functions
Em alguns exemplos do artigo anterior, vimos que é possível utilizar as funções de agregação dentro de uma Window Function (WF).
A forma como o cálculo é organizado, isso é, como o banco vai processar, vai depender exclusivamente da nossa construção da consulta. Aliado às opções da WF, podemos criar queries interessantes.
Vejamos a query abaixo:

Percebam que criei duas colunas com as WF, sendo a primeira chamada TOTAL_SALES e a segunda TOTAL_CUST.
Na TOTAL_SALES, como não foi especificado nenhuma partição, o que o banco fez foi trazer o total das vendas de todos os produtos. Na segunda coluna, TOTAL_CUST, temos o total por cada cliente; pois há particionamento.
Na primeira coluna, seria algo similar a esse cálculo, porém, sem aplicar para todas as linhas. Apenas o valor linear.
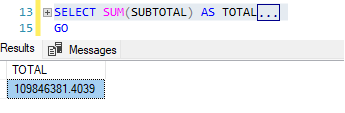
Para a TOTAL_CUST, o problema começa a aparecer. A medida que vamos adicionando colunas na query e, por consequência, no GROUP BY, o cálculo vai se desmantelando.
No primeiro exemplo, veja a construção:
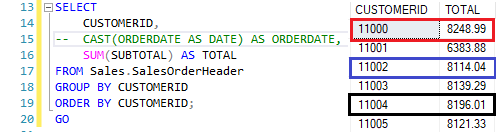
Adicionando a coluna ORDERDATE.

Além dos recursos analíticos que a Window Function resolve, o que vemos, é que ela também facilita a criação da query.
Outra estrutura presente é o Framing, que dita como a operação irá ocorrer.
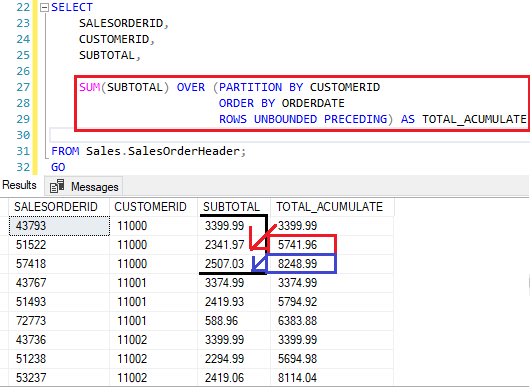
Aqui, acontecem as seguintes situações:
- O banco soma a linha anterior com a atual;
- Computa o resultado na linha atual;
- Soma com o valor da próxima linha.
Comparando com o resultado do primeiro exemplo, podemos perceber que é o mesmo.
Podemos comparar os elementos de Framing como um filtro interno no particionamento de uma query. Porém, diferente do filtro convencional, temos um modo de operação da função de agregação.
Outro ponto que devo chamar atenção é que, embora similares, o GROUP BY e o Partitioning da WF são coisas diferentes. Sendo que o segundo, cria pequenos blocos com valores iguais.
A medida que vamos adicionando colunas na query e, por consequência, no
GROUP BY, o cálculo vai se desmantelando… Além dos recursos analíticos que a Window Function resolve, o que vemos, é que ela também facilita a criação da query.
Uma grande vantagem em utilizar as WF com função de agregação é no cálculo de porcentagem. Se quiséssemos utilizar apenas as funções de agregação, teríamos que utilizar no mínimo, duas CTEs e o código ficaria um tanto embolado.
Porém, veja como as Window Functions facilitam o trabalho.
- Vermelho → eu tenho o cálculo do quanto aquela compra do cliente representa no faturamento total;
- Preto → o quanto a compra do cliente representa no faturamento daquele ano.
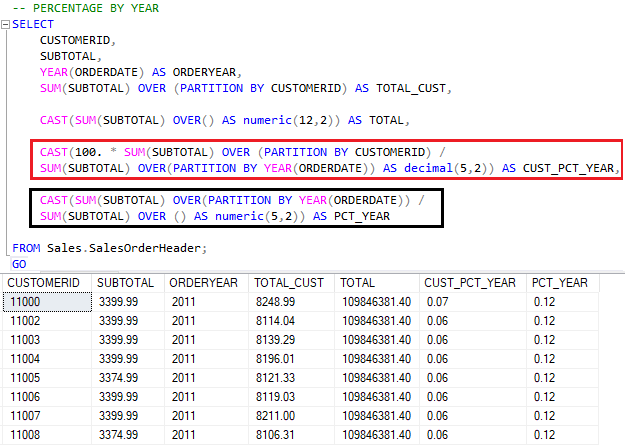
Como meu particionamento para a segunda coluna foi por ano, o SQL Server computa o total no range e divide pelo total geral, chegando ao resultado.
Um outro exemplo calculando a porcentagem por território. Veja como temos um código mais limpo e simples.
Repare que no exemplo da esquerda, há quatro subqueries sendo executadas no código. Em bancos muito grandes, isso pode trazer lentidão.
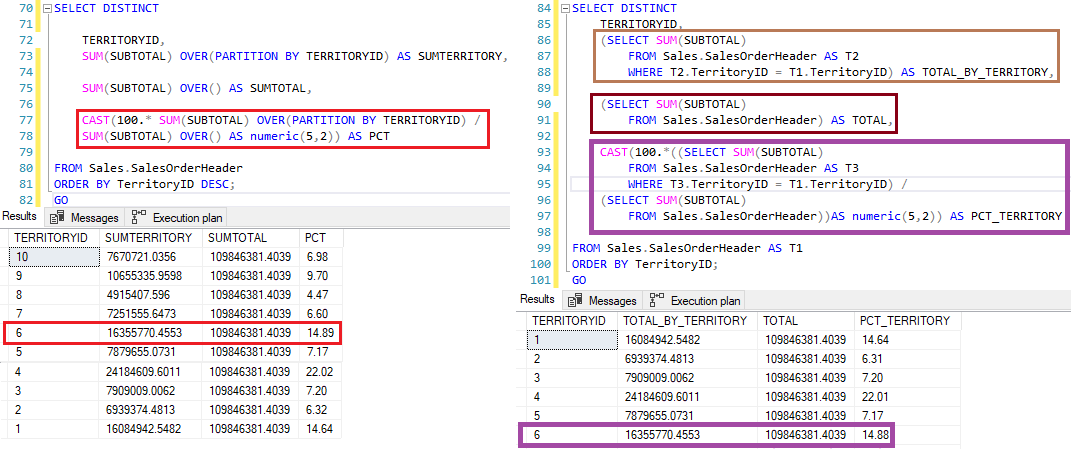
Note que a quantidade de subqueries na segunda consulta. Essa é a melhor maneira de explicitar a vantagem de utilizar Window Functions em queries analíticas.
Um fato interessante é que se filtrarmos com o WHERE, a query passa a considerar esse valor como a totalidade. Veja.

Como a WF logicamente ‘acontece’ entre o SELECT e o ORDER BY, o WHERE limita os dados em que ela irá trabalhar. Uma vez que a query entrega apenas um único território, ele é a totalidade da ação da WF.
Aumentando a quantidade de território.

Como podemos notar, a soma da porcentagem dos territórios retornados devem dar 100%.
Ordem e Framing em Window Functions
Sempre que queremos ditar como será a ação da query sobre o particionamento criado, precisamos ordenar e especificar o subconjunto que a função irá trabalhar, como se fosse o OFFSET – FETCH.
O framing dentro da WF tem duas funções:
- Limitar a quantidade de linhas;
- Orientar a ação da função de agregação.
Quando explicitamos o frame na query, ele atribui uma orientação para o cálculo que iremos performar.
Como a WF logicamente ‘acontece’ entre o
SELECTe o ORDER BY, oWHERElimita os dados em que ela irá trabalhar. Uma vez que a query entrega apenas um único território, ele é a totalidade da ação da WF.
Na coluna RUNSELL, temos o que alguns chamam de running total, das vendas de acordo com determinado vendedor. Isso só é possível graças ao framing atribuído na query.
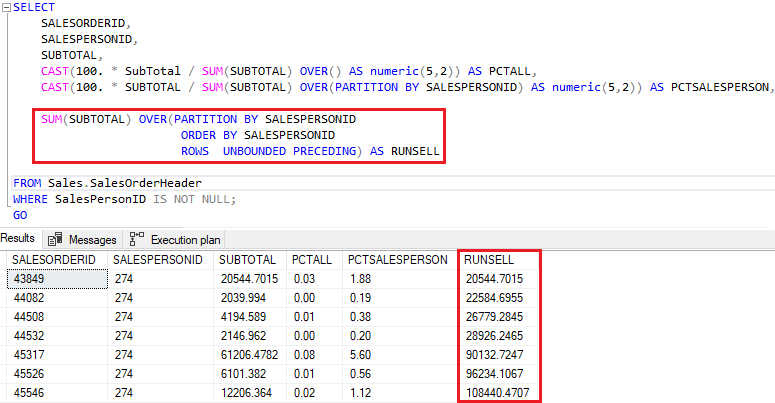
Antes de continuar, preciso chamar atenção para uma situação.
Sempre que houver mais de um framing na query com WF e estes possuírem ORDER BY divergentes, o último diratá o ordenamento do resultado.
Alterando o ORDER BY dentro do framing, divergindo entre as duas colunas, veja o resultado.
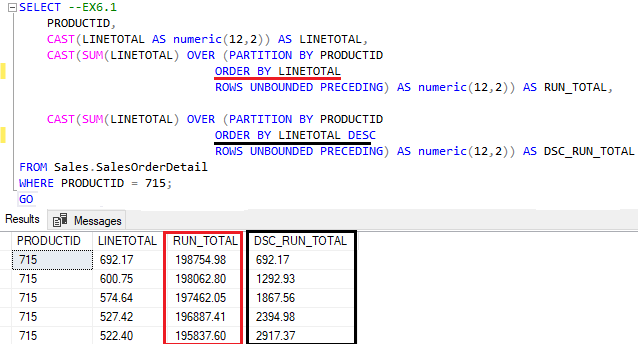
O que passou a ditar a exibição do resultado foi a segunda coluna. Além disso, percebam que a declaração do frame é igual.
Os frames dentro de uma WF são criados através de duas cláusulas no comando.
- UNBOUNDED PRECEDING
- UNBOUNDED FOLLOWING
O que as duas expressões fazem é especificar, a partir da linha atual, como o cálculo ocorrerá.
Na primeira coluna, RUNTOTAL, já conhecemos o frame e como ele opera. Sempre somando a linha atual com a próxima e acumulando. Daí o resultado acumulado.
Porém, quando tratamos do UNBOUNDED FOLLOWING a estrutura muda. Para criarmos esse framing, precisamos dizer ao SQL Server quantas linhas ele deve processar na operação.
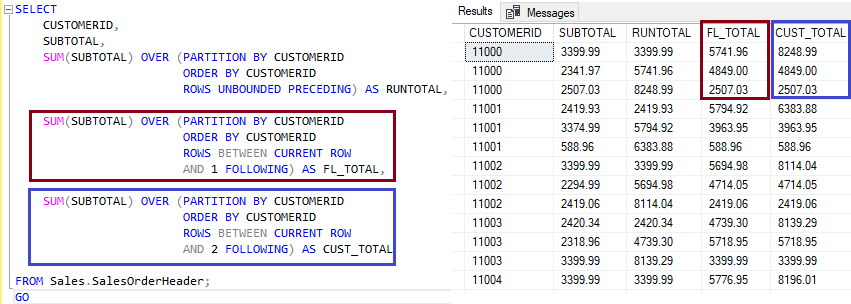
Na coluna FL_TOTAL ela processa a linha 1 somando com a linha 2, obtendo o resultado de $5741,96 para a linha 1. O mesmo acontece para a linha 2 e 3, sendo que a última linha do frame não irá somar pois a janela do cliente 11000 fechou.
Já para a coluna CUST_TOTAL há a soma da linha 1 com as linhas 2 e 3, obtendo o resultado $8248.99, e o mesmo vale para a linha 2 e 3. Sendo que a linha 2 irá somar apenas com a linha 3, já que não existe outra para esse frame.
Essa operação só foi possível pois para cada uma delas eu indiquei como o SQL Server deveria processar a operação dentro do frame com as linhas. Note que na FL_TOTAL ele somou com 1 e na CUST_TOTAL com 2.
Caso não seja indicado nenhum número, a soma ocorre normalmente. Como mostra a imagem abaixo.

Uma das grandes vantagens na manipulação de frames é a facilidade em visualizar o anterior e próximo pedido de um determinado cliente em relação a linha atual.
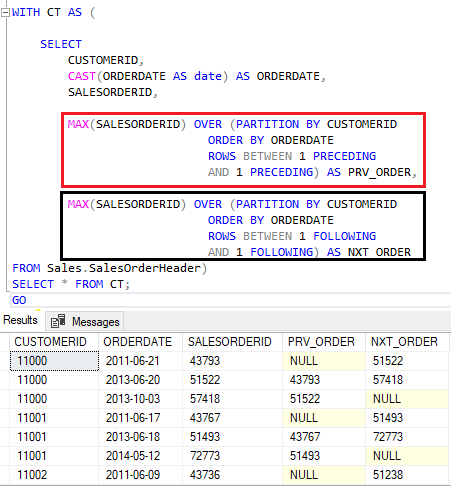
Em manipulações de frame com partições muito grandes e, como no caso abaixo, com diversas linhas para um mesmo dia, pode ser interessante adicionar um tie-break no código para tornar o resultado o mais determinístico possível.
É uma boa prática criar queries que atendam esse requisito.
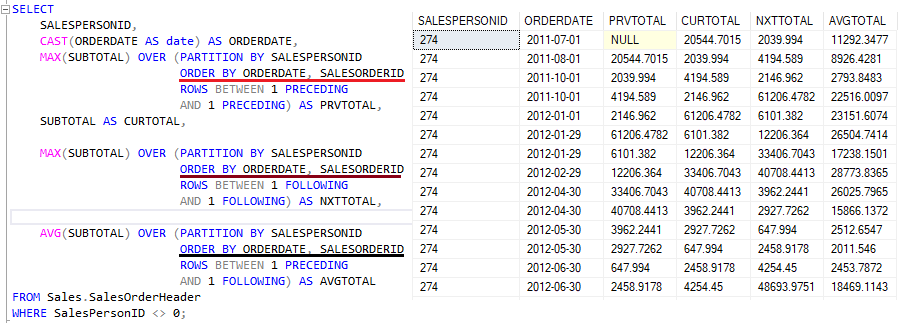
Outro exemplo de bom uso do framing com CTE é exibir a quantidade de pedidos nos últimos 3 dias ou qualquer outra quantidade de dias.
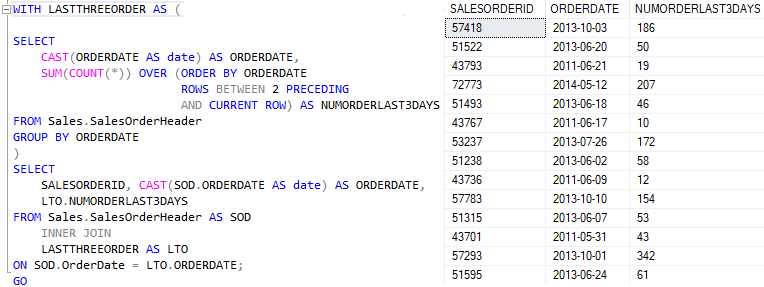
As Window Functions facilitam a contagem de pedidos por dia, desde que seja criado com o frame correto.
É importante destacar que mesmo a quantidade sendo repetida, perceba que os pedidos são distintos. Não há repetição de valores.
Uma das limitações quando se trata de implementação de Window Functions no SQL Server é na contagem distinta. Como a linguagem T-SQL não possui DISTINCT AGGREGATE, precisamos de uma solução.
Em manipulações de Frame com partições muito grandes e, como no caso abaixo, com diversas linhas para um mesmo dia, pode ser interessante adicionar um tie-break no código para tornar o resultado o mais determinístico possível.
Por exemplo, imagine que queremos calcular a quantidade de vendas distintas que um vendedor fez e os clientes que compraram. Para isso, esbarramos novamente nas CTE’s.
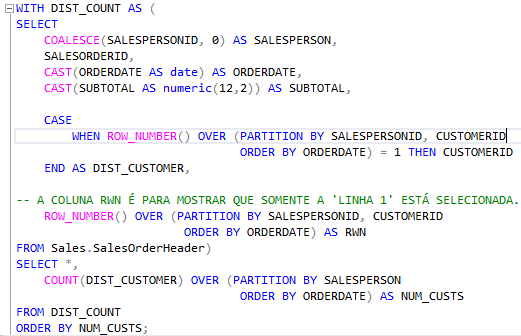
E o resultado da query abaixo:
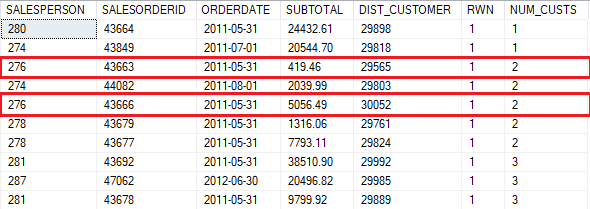
Perceba que o vendedor de ID 276 realizou duas vendas distintas, como mostra a coluna NUM_CUSTS. Destacando no resultado, temos duas vendas cada uma para um cliente.
Se filtrar a query pela data 31/05/2011, verá que não existe uma terceira venda para outro cliente.
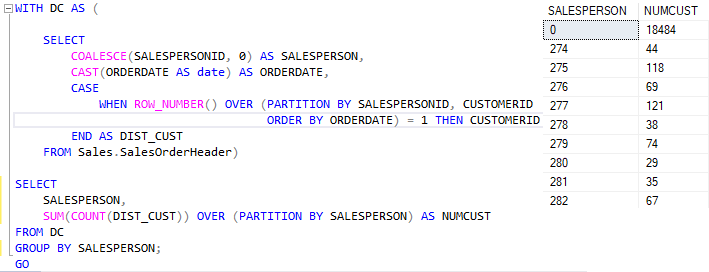
E somando os pedidos de todos os vendedores:
Funções de RANK
São funções que possuem a característica de criar um valor numérico para as linhas retornadas da consulta e que, dependendo da query, podem ser manipuladas.
Algumas delas já vimos em exemplos anteriores, mas vamos relembrar:
- RANK
- DENSE_RANK
- NTILE
- ROW_NUMBER
Como já vimos exemplos com a ROW_NUMBER, vamos para a função NTILE.
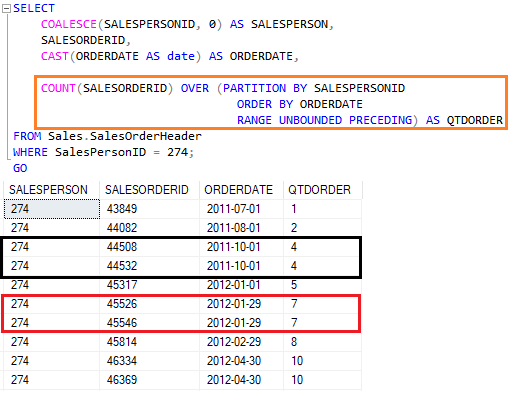
A função cria ‘divisões’ dentro do conjunto de resultados baseado na quantidade de linhas que a consulta retornará.
É a única função desse grupo que aceita um input como parâmetro. Esse input servirá de divisor para as linhas do resultado.
Sempre que houver mais de um framing na query com WF e estes possuírem
ORDER BYdivergentes, o último da query irá ditar o ordenamento do resultado.
Então, se uma query retorna 31000 linhas e a quantidade de divisões por 10, teremos grupos de 3100 linhas em cada.

Já as funções de RANK funcionam como uma ROW_NUMBER, mas empatam caso esteja em uma situação igual. Porém, isso não se aplica a DENSE_RANK.
Quando utilizada, ela cria um ranking com base nos valores distintos.
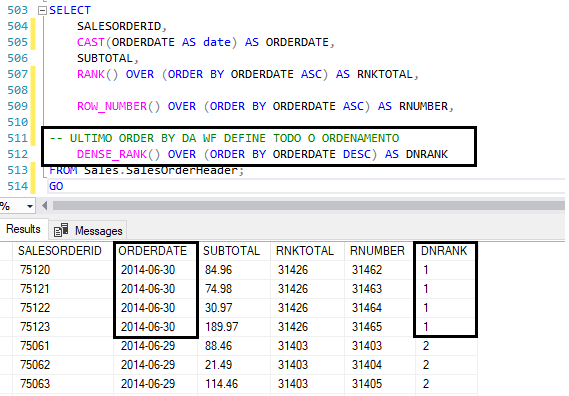
Como o ordenamento está por data, o ranking dos dados somente mudarão quando a data mudar. Como ocorreu na coluna DNRANK.
Uma aplicação bem interessante é selecionar um bucket específico dentro do resultado de uma query com DENSE_RANK. Para isso, utilizamos TVF e CTE.

Funções Estatísticas
As funções estatísticas do SQL Server são do grupo de análise de dados dentro das Window Functions. Elas trabalham com percentuais, atuando de acordo com o conjunto de dados aplicado.
Existem dois subgrupos de função estatísticas no SQL Server:
- RANK DISTRIBUTION → com as funções
PERCENT_RANKECUME_DIST - INVERSE DISTRIBUTION → com as funções
PERCENTILE_RANKEPERCENTILE_DISC.
Como as funções PERCENT_RANK e CUME_DIST são, em sua base, rank, elas exigem o uso de ORDER BY.
Quando utilizado as funções de RANK DISTRIBUTION, entenda que elas vão criar um ratio que irá de 0 até 1 – podendo ter decimal. Com esse ratio, os dados serão distribuídos de acordo com seu encaixe.
A função PERCENT_RANK irá retornar a posição relativa que cada valor está, dentro do range entre 0 e 1.
Já a função CUME_DIST calcula uma distribuição acumulada que varia entre 0 e 1, distribuindo os dados de acordo com a sua proximidade do valor mais alto (1).
Vamos entender melhor com a query abaixo:
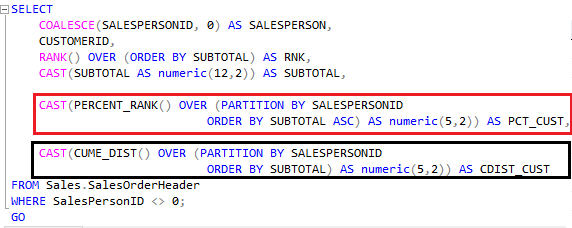
Caso não passe nenhum valor numérico para as funções, ela não distinguirá os dados que pertencem a tal grupo.
Agora vamos entender o resultado da query:
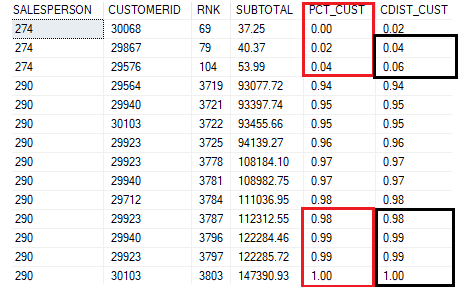
Na coluna PCT_CUST cada compra feita tem uma posição no percentil estatístico criado pela função. Então, a compra de valor $37.25, por ser de baixo valor, está no percentil inferior dos dados.
Porém, olhando para o final do resultado, as compras dos clientes de ID 29940, 29923 e 30103 estão no percentil mais alto, o que se justifica, se olharmos o valor de suas compras.
Para a coluna CDIST_CUST, embora se pareça com a PCT_CUST, o que ela nos traz para análise são os grupos acumulados dos clientes que estão em suas respectivas distâncias do valor máximo.
Por exemplo, os clientes 29867 e 29576 ocupam posições diferentes em cada função estatística. Como a segunda coluna entrega uma ‘distribuição’, é como se estes clientes estivessem no grupo que se encontra no 0.02 até o 0.04.
Para uma melhor visualização, até por ser mais precisa, utilize três casas decimais. Veja.
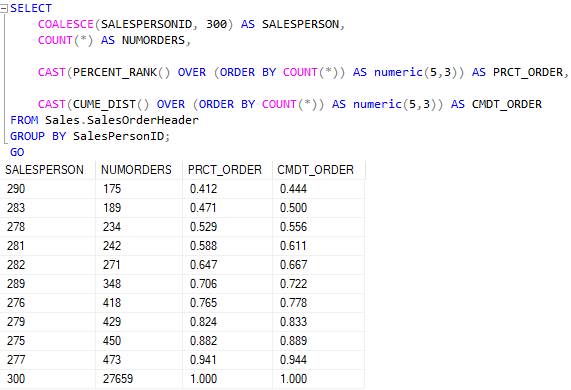
Podemos perceber que os resultados são diferentes e entregam maior capacidade de análise.
O interessante dessas funções estatísticas é a criação de queries que permitem classificar os clientes de acordo com seu ‘perfil de compra’.
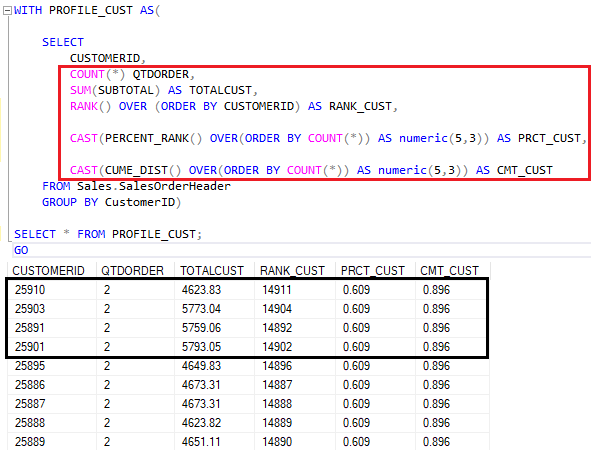
Agora que vimos os exemplos e entendemos como as funções de distribuição por rank funcionam, avançamos para as funções de distribuição inversa.
As funções desse grupo aceitam um valor como input e desse valor, dentro do conjunto de dados, retornam aqueles que estão mais próximos.

Para entendermos o resultado, vamos destrinchar o que a query está fazendo.
Começamos que estas duas funções atuam de forma diferente por utilizarem a cláusula WITHIN GROUP. Isso quer dizer que ‘dentro do grupo RATE (salário)’, ela está calculando o percentil do valor particionado pelo departamento da empresa.
Então, o valor de cálculo da função é a coluna salário, a repartição é a coluna departamento e o valor do percentil 0.8.
Olhando unicamente o resultado da query relembrando o que cada função faz:
A função PERCENTILE_DISC irá calcular, dentro do grupo que ela está sendo aplicado, qual o valor que condiz com a ‘linha de corte’ – valor passado como input para a função.
Já a função PERCENTILE_CONT irá calcular um valor discreto com base no percentile desejado e os valores que estão no conjunto de dados.
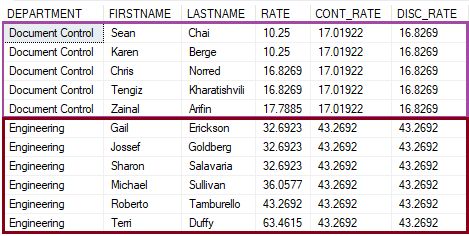
Desse modo podemos perceber que para o percentil 0.8 da função PERCENTILE_CONT (coluna CONT_RATE) o salário que corresponde a esse parâmetro, dentro do departamento ‘Document Control’, seria de $17.019.
Esse é um valor ‘escondido’, não percebido, dentro da faixa salarial analisada neste grupo. Como o valor do percentil foi de 0.8, este se encontra entre 16.82 e 17.85, uma vez que ele não pode ultrapasar o teto – valor máximo.
Indo para a coluna DISC_RATE, o resultado é um pouco diferente. Para ela, o que temos é o 16.82, que significa o salário que se encontra no percentil 0.8 do grupo analisado.
Lembrando que os valores são de acordo com cada departamento, especificado no PARTITION BY.
OFF-SET Functions
Por fim, mas não menos importante, estão as funções de manipulação de conjunto, as OFF-SET.
Essas funções criam um subconjunto com base no resultado primário da tabela.
Neste grupo de funções conseguimos retornar o primeiro e último valor do conjunto, bem como seu antecessor e sucessor.
Neste grupo temos: LAG, LEAD, FIRST_VALUE e LAST_VALUE.

Conclusão
Neste novo post sobre Window Functions resolvi revisar todas as funções que estão implementadas no SQL Server, que é o banco dos meus estudos.
Mostrei com exemplos práticos os usos que podemos fazer delas e como facilitam a criação de queries, deixando-as mais simples e legíveis.
As funções de janelamento funcionam muito bem com CTEs e TVFs, faça bastante uso para entregar ótimos resultados e análises.
Domine bem as funções estatísticas.
Até o próximo.
Se chegou até aqui e gostou do pequeno tutorial, deixe seu comentário e compartilhe. Ajude esta comunidade a alcançar mais pessoas!
Baixe o script SQL aqui.

