
Data Mesh é uma arquitetura de dados distribuída que enfatiza a responsabilidade dos dados e promove a descentralização do gerenciamento de dados em uma organização. Em vez de ter um único monólito de dados centralizado, a arquitetura de Data Mesh permite que cada equipe ou domínio de negócios seja proprietária dos seus dados.
Essa abordagem é recomendada quando a organização tem muitos domínios de negócios distintos com requisitos de dados diferentes. Principalmente quando há uma necessidade de melhorar a colaboração entre as equipes e reduzir a dependência de uma equipe central de dados.
O conceito de Data Mesh foi proposto em 2018 por Zhamak Dehghani, na época líder técnica de arquitetura corporativa na ThoughtWorks.
Além disso, a arquitetura de Data Mesh também pode melhorar a qualidade dos dados em toda a organização. Isso ocorre porque cada equipe de negócios é responsável por seus próprios dados e pode garantir que eles estejam limpos, precisos e atualizados. Com a descentralização do gerenciamento de dados, também há menos probabilidade de que dados ruins sejam propagados por toda a organização.
A implementação do Data Mesh não é um processo simples e envolve mudanças significativas na cultura organizacional, na governança de dados e na infraestrutura de TI. É necessário um compromisso com a colaboração, transparência e responsabilidade em toda a organização. A equipe de Engenharia de Dados desempenha um papel fundamental na implementação bem-sucedida do Data Mesh. Engenheiros fornecem orientação técnica e suporte à infraestrutura de dados distribuída e aos pipelines de dados.
A adoção do Data Mesh pode ser um desafio, mas as recompensas podem ser significativas. Entre os benefícios estão uma maior eficiência operacional, melhor qualidade de dados e maior colaboração entre as equipes de negócios.
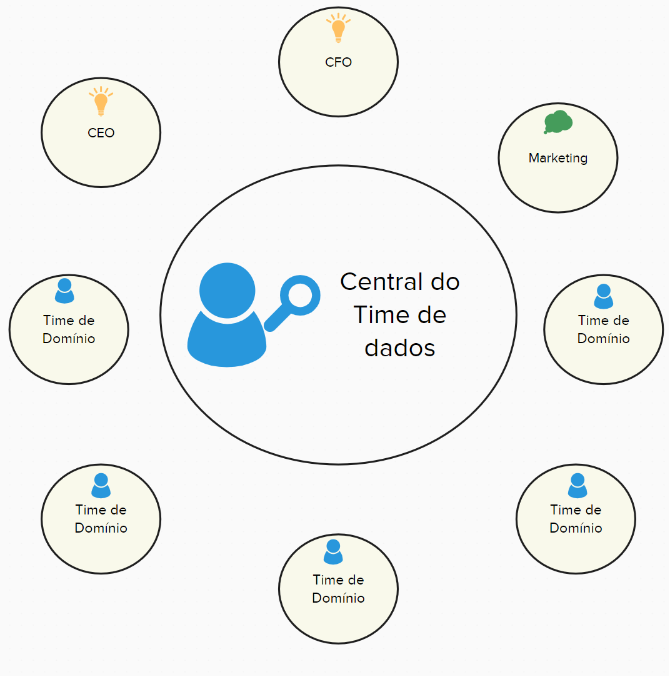
Data Mesh – Qual o papel do time de dados?
A equipe de Engenharia de Dados (DE, Data Engineering) desempenha um papel crucial na implementação da arquitetura de dados mesh. Eles são responsáveis por projetar, implementar e manter as infraestruturas de dados distribuídas que permitem a comunicação e a colaboração entre os diferentes domínios de dados. Para isso, a equipe de DE trabalha na construção de pipelines de dados que garantem a qualidade, segurança e conformidade das informações compartilhadas.
Além disso, a equipe de DE também é responsável por fornecer orientações técnicas para as equipes de negócios, auxiliando-as a padronizar os dados, projetar e implementar serviços de dados, além de garantir a qualidade dos dados e a conformidade com as políticas e regulamentações de dados. Em outras palavras, a equipe de DE é fundamental para garantir que o Data Mesh funcione adequadamente e que as equipes de negócios possam trabalhar de forma colaborativa e eficiente, usando dados confiáveis e seguros.

Data Mesh – As 4 Fases do Data Mesh
O objetivo do Data Mesh é permitir que as equipes distribuídas trabalhem e compartilhem informações de maneira descentralizada e ágil.
O Data Mesh é um padrão técnico que também exige uma mudança organizacional. Os benefícios de uma abordagem de Data Mesh são obtidos pela implementação de equipes multidisciplinares que publicam e consomem produtos de dados.
Os seguintes conceitos são fundamentais para entender a arquitetura Data Mesh:
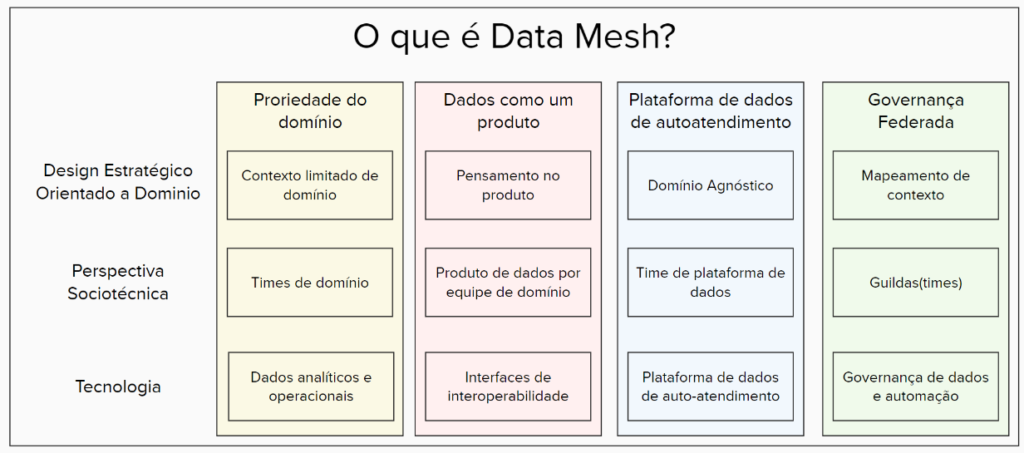
Primeira fase: Propriedade do Domínio
O princípio de propriedade do domínio exige que as equipes de domínio assumam a responsabilidade por seus dados. Seguindo a arquitetura distribuída orientada a domínios, a propriedade dos dados operacionais e analíticos é movida para as equipes de domínio, longe da equipe central de dados.
Há três aspectos em relação aos domínios de dados:
- Os limites escolhidos servem para a propriedade de longo prazo. Eles existem por um longo período e identificaram os proprietários.
- Os domínios devem corresponder à realidade, não apenas aos conceitos teóricos.
- Seus domínios precisam ter integridade atômica. Se as áreas não tiverem nenhuma relação entre si, não as combine em um domínio juntas.
Segunda fase: Dados como Produto
O princípio de dados como produto projeta uma filosofia de pensamento de produto sobre dados analíticos. Isso significa que há consumidores de dados além do domínio. A equipe de domínio é responsável por atender às necessidades de outros domínios fornecendo dados de alta qualidade, tratando dados de domínio como qualquer outra API pública.
Um produto de dados bem-sucedido precisa ser:
- Utilizável: seu produto precisa ter usuários fora do domínio de dados imediato.
- Valioso: seu produto precisa manter o valor ao longo do tempo. Se ele não tiver um valor de longo prazo, ele não terá sucesso.
- Viável: seu produto precisa ser viável. Se você não conseguir realmente criá-lo, o produto não será um sucesso. Seu produto precisa ser viável tanto do ponto de vista técnico quanto de disponibilidade de dados.
Os produtos de dados podem ser entregues como uma API, um relatório, uma tabela ou um conjunto de dados em um data lake.
Terceira fase: Autoatendimento
A ideia por trás do autoatendimento é adotar o pensamento de plataforma para a infraestrutura de dados. Uma equipe dedicada à plataforma de dados fornece funcionalidades, ferramentas e sistemas independentes de domínio para criar, executar e manter produtos de dados interoperáveis em todos os domínios.
Quarta fase: Governança Federada
O princípio de governança federada alcança a interoperabilidade de todos os produtos de dados por meio da padronização, promovida pelo grupo de governança em todo o Data Mesh. O objetivo principal da governança federada é criar um ecossistema de dados com conformidade com as regras organizacionais e regulamentações da indústria.
Data Mesh – Como é implementada?
A implementação do Data Mesh envolve a criação de domínios de dados distribuídos, cada um com sua própria equipe de propriedade e governança de dados.
A comunicação entre domínios é feita por meio de APIs padronizadas e contratos de serviço. A tecnologia é usada como um meio para permitir a colaboração entre domínios, em vez de ser o foco principal.
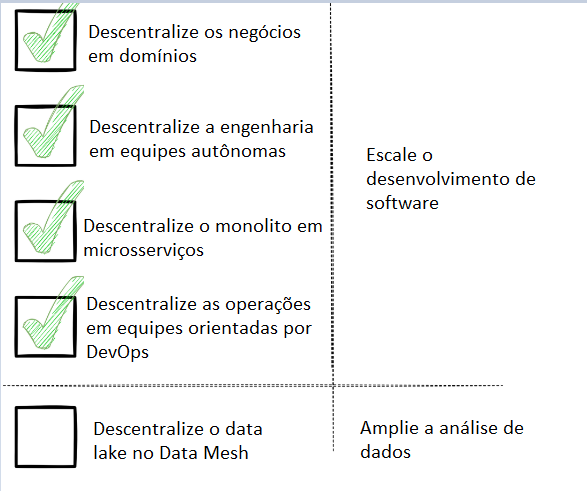
Além disso, a implementação do data mesh também envolve a criação de uma cultura de colaboração e responsabilidade compartilhada entre as equipes de domínio.
Cada equipe é responsável por garantir a qualidade, integridade e segurança dos dados em seu domínio. Mas também deve colaborar com outras equipes de domínio para garantir a conformidade de dados e compartilhamento de dados entre domínios.
Isso requer uma mudança cultural significativa em relação à abordagem tradicional centralizada de gerenciamento de dados. O resultado final, porém, é uma estrutura mais ágil e escalável para gerenciamento de dados. Isso pode apoiar a inovação e a tomada de decisões informadas em toda a empresa.
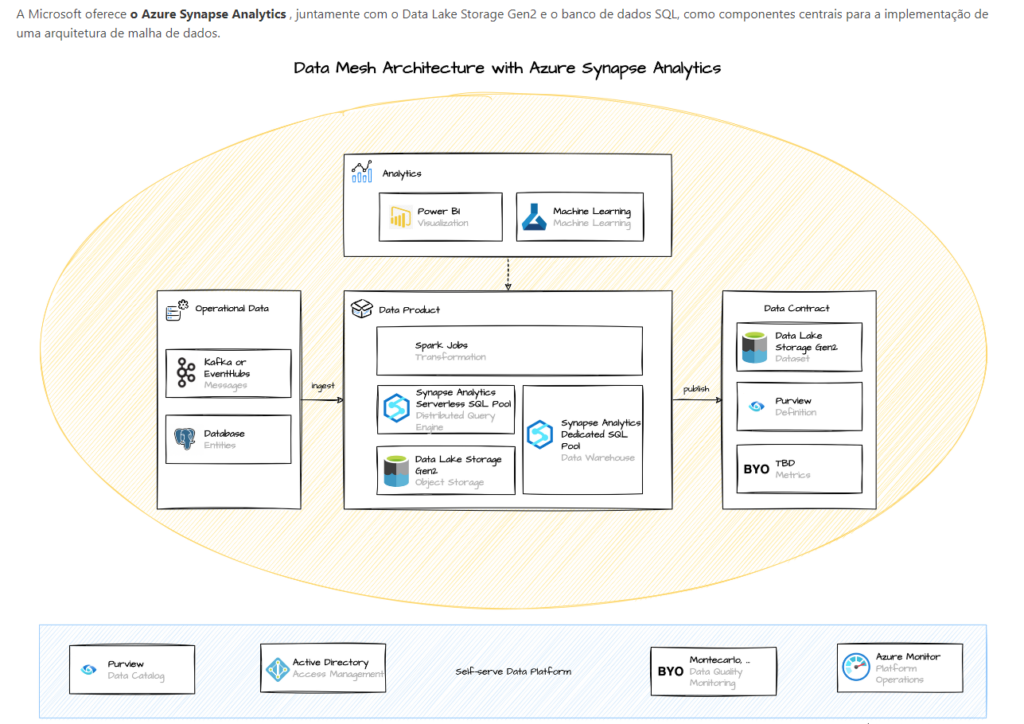
Data Mesh – Um exemplo Microsoft
A Microsoft, como outros provedores de Cloud, oferece um conjunto de serviços e recursos que, se unidos, nos possibilitam construir um Data Mesh. Ou ao menos, bem semelhantes ao que estamos conversando.
Sabendo que Data Mesh é um conceito relativamente novo, devemos pensar como uma evolução. Evolução essa que também terá a sua mudança e adaptação conforme a estrutura organizacional da empresa.
Data Mesh – Suposta implementação de código
Para explicar uma suposta implementação de código usando o conceito de Data Mesh, é importante entender a abordagem do Data Mesh. A abordagem se concentra na descentralização e na autonomia dos domínios de dados. Portanto, o código deve ser escrito para permitir que cada domínio de dados opere de forma independente. Tudo isso enquanto se comunica com outros domínios por meio de contratos de serviço.
Vamos ver um exemplo de criar um sistema de gerenciamento de pedidos em uma empresa. A abordagem de Data Mesh envolveria a criação de um domínio de dados separado para o gerenciamento de estoque. Outro para o gerenciamento de pedidos. Outro para o gerenciamento de pagamentos. E assim por diante.
O código em cada domínio de dados seria escrito para atender às necessidades específicas do domínio. Tendo também também que garantir a comunicação eficaz com outros domínios. Isso pode ser feito por meio da criação de APIs padronizadas e contratos de serviço claros, que definem como os dados devem ser compartilhados entre os domínios.
Essa abordagem de design de código permite que cada equipe de domínio tenha autonomia e responsabilidade por seus próprios dados. As equipes trabalham em conjunto para atender às necessidades de negócios mais amplas.
A implementação de código usando a abordagem Data Mesh ajuda a garantir que os dados sejam gerenciados de forma mais eficaz. Permitindo assim que a empresa tome decisões informadas com base em insights confiáveis de seus dados.

Conclusão
Em resumo, Data Mesh é uma arquitetura de dados distribuída que enfatiza a responsabilidade dos dados e promove a descentralização do gerenciamento de dados em uma organização. Essa abordagem é recomendada para organizações com muitos domínios de negócios distintos e requisitos de dados diferentes, e pode melhorar a colaboração entre as equipes e reduzir a dependência de uma equipe central de dados.
A implementação do Data Mesh exige uma mudança significativa na cultura organizacional. Mudança que deve abranger a governança de dados e a infraestrutura de TI. A equipe de Engenharia de Dados (DE) desempenha um papel crucial na sua implementação bem-sucedida.
As quatro fases do Data Mesh incluem os princípios de propriedade do domínio, dados como produto, autonomia, e governança federada.
Até a próxima…
Esperamos que tenham gostado bastante deste artigo. Com toda certeza queremos que volte para ler mais sobre este tema. Esperamos que esteja ficando muito legal.
Caso tenha ficado alguma dúvida ou queiram rever algum tema anterior, abaixo deixo nossas últimas postagens:
Engenharia de Dados: uma abordagem menos técnica
Pipelines e o Processo de Engenharia de Dados
Data Warehouse x Data Lake x Data Lakehouse
Espero ter despertado a sua curiosidade e conto com seu comentário para saber a sua opinião. Deixe também dúvidas ou sugestões que teria sobre os temas que vimos aqui.
E se estiver gostando da nossa comunidade, conheça um pouco mais sobre nós e nossos objetivos de fortalecer a comunidade brasileira de dados no post BRAINS – Brazilian AI Networks.
#NoBrains #NoGains 

