Eu não tenho dúvidas que você anda vendo muita gente falando sobre Foundation Models, IA Generativa e sobre LLMs (Large Language Models), os famosos grandes modelos de linguagem. E tenho certeza de que você também faz uso dessa tecnologia – ainda que não saiba disso. Afinal de contas, de fato é uma tecnologia que está mudando a forma como fazemos negócios, e a forma como encaramos o mundo. Mas o que talvez você não veja muita gente explicando, são os conceitos básicos desta tecnologia. Ouvimos muitas vezes os termos Token e Embedding, não é?
Todo modelo generativo de linguagem possui um limite de Tokens que ele pode receber como entrada (o seu Prompt) e um limite de Tokens na saída que ele gera (a Inferência). E até mesmo o modelo de cobrança desses modelos é por Tokens. Mas você sabe o que são Tokens? E o que são Embeddings? E a diferença entre eles?
Vamos lá! Vamos descobrir!
Mas espera aí… se por acaso você ainda não tem certeza se sabe o que são esses “Foundation Models” e os “Large Language Models”, recomendo a leitura de dois outros posts antes. O primeiro é o Foundation Models: Modelos que Revolucionaram a IA, que vai te dar um contexto um pouco mais histórico e conceitual. Após essa leitura, recomendo o Introdução aos LLMs e à IA Generativa, que vai te mostrar de forma um pouco mais prática o que esse tipo de modelo de fato faz, o que ele não faz, e apresentar alguns outros conceitos importantes.
Token e Embedding: falando com a máquina 🤖
Nós sabemos que no fundo, no fundo, tudo o que o computador entende são números. Para sermos mais exatos, tudo o que o computador entende são 0s e 1s. Minha amiga, Ana Paula Appel, que me perdoe, mas não vamos falar de Computação Quântica por enquanto. A menos que a Ana tope nos ensinar um pouco sobre Quantum. (Deixem nos comentários o incentivo! Alô @Ana, vamos falar sobre Quantum! 😄). Mas enfim, vamos nos manter no mundo binário, onde o computador só entende 0 e 1.
Nós não precisamos nem descer num nível tão baixo. Podemos abstrair as operações binárias básicas. Vamos para um nível mais simples. Vamos falar a língua dos modelos de Machine Learning. E modelos de Machine Learning falam a língua da matemática: números!
Todo modelo é, por baixo dos panos, um modelo matemático. E nós só fazemos matemática com números. Isso se aplica aos modelos estatísticos clássicos. Se aplica aos modelos de Visão Computacional, que transformam pixels em números. E precisa se aplicar também a modelos de linguagem. Mas como transformamos texto em números? Bom, com Token e Embedding.
Token é uma via de mão dupla
Nós precisamos, de alguma forma, encontrar uma via de mão dupla para transformar texto em números e números em texto. Tokens são a resposta. Chamamos de “Tokenização” o processo de quebrar longas quantidades de texto em unidades menores. Unidades estas que podem ser mapeadas para se tornarem números.
Todo o processo da criação dos Tokens trabalha então com esse mapa. Chamamos esse mapa de vocabulário, ou de Lexicon (“léxico”). Para simplificar, vamos enxergar esse mapa como um dicionário. Dicionário esse onde cada token tem uma posição específica. Ou seja, cada token tem um índice.
Perceba também que como temos um índice, sabemos exatamente a posição em número de um token qualquer. Podemos assim transformar o token em seu índice numérico, ou “Tokenizar”. E podemos também, a partir do índice recuperar o token, ou “Destokenizar”. Nós encriptamos e decriptamos nossa mensagem.
Mas, afinal de contas, como fazemos isso na prática? Bem, vamos tomar como exemplo a frase abaixo.

Existem diversas estratégias diferentes de tokenização. Vamos explorar algumas.
Tokenização por caractere
Bom, precisamos transformar texto em números. E de uma forma que possamos recuperar depois. A saída mais óbvia é definirmos um valor numérico para cada letra – ou cada caractere – concordam? Bom, é uma ótima ideia!
Para simplificar aqui, vamos montar o nosso dicionário apenas com letras do nosso alfabeto. Vamos desconsiderar maiúsculas e minúsculas e acentuação. Nada de pontuação também, para fins didáticos.
Como ficaria nosso dicionário construído?

Desta forma, podemos transformar nossa frase sobre nossos queridos arquitetos em números. Basta substituir cada letra pelo seu respectivo índice. Vamos ver como ficaria?

Na nossa tokenização, a letra "O" vira o número 15. A letra "a" vira o número 1. Letra "r" vira o número 18, "q" vira 17, "u" vira 21… e assim por diante.
Nossa tokenização retornaria a seguinte sequência de tokens.

Note que nós assumimos que o espaço é o token 0, ok? Desta forma conseguimos transformar texto em números. Nosso modelo recebe números na sua entrada e gera números na sua saída. Os números gerados pelo nosso LLM vão fazer referência também ao seu respectivo token – ou letra, neste cenário.

Essa é uma estratégia que parece ser muito simples e funcional, concordam? Entretanto, esta pequena frase nos gerou um total de 68 tokens! Não parece muito. Mas imaginem usar esta estratégia considerando todos os caracteres especiais. E fazer letra por letra todo um livro. Ou toda a Wikipedia. Ou até mesmo quase toda a internet.
A quantidade de tokens a serem processados seria muito, muito grande. Isso torna o processo muito custoso em termos computacionais. E essa é uma desvantagem desta estratégia. Vamos tentar ser mais econômicos então.
Tokenização por palavra
Com o objetivo de reduzir a quantidade de tokens a serem processados pelo modelo, podemos criar um dicionário onde cada índice possui uma palavra, ao invés de uma letra. Vamos ver como ficaria.
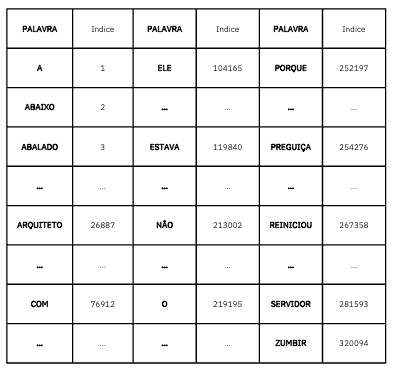
Nós temos na tabela acima um dicionário real. Um vocabulário em língua portuguesa disponível no GitHub, sob licença permissiva, num repositório do Python.pro.br. O dicionário tem um pouco mais de 320 mil palavras. E nós podemos atribuir o valor numérico do índice de cada uma delas a cada um dos nossos Tokens. Lembre-se que agora cada palavra é um Token.

Maravilha! Reduzimos para apenas 11 tokens o nosso texto. Simplificamos muito a entrada e saída do nosso modelo.
Por outro lado, aumentamos muito a complexidade do nosso dicionário. São mais de 320 mil itens, e não chegamos nem perto de cobrir toda a língua portuguesa. Agora imagina a complexidade de se treinar um modelo multi-idiomas. E também nas palavras que são “criadas” a todo tempo. O nosso modelo se depararia com muitos, muitos tokens desconhecidos. E normalmente estes tokens são representados por [UNK].
Desta forma, ficamos com um cobertor curto. Cobrimos a cabeça e descobrimos os pés. Simplificamos a quantidade de tokens a serem processados pelo modelo, mas criamos um monstro de dicionário pouco flexível.
E agora? Será que temos uma forma mais eficiente e mais inteligente de lidar com os tokens?
Tokens mais eficientes
Uma forma mais interessante de lidar com os tokens, é dividindo as palavras. Isolando o radical, prefixo e sufixo. E tratando cada parte como uma unidade diferente, um token diferente.
Vocês devem ter percebido, que muitas palavras do nosso idioma são formadas com o mesmo radical. Vamos pegar como exemplo a palavra "beber". O início da palavra, o "beb-" pode ser reutilizado em "bebendo", "bebi", "bebido", "bebeu", e assim por diante.
Da mesma forma, o "-er" de "beber", pode ser reutilizado em "comer", "escrever", "ler", etc. Vamos ver como ficaria?
Percebem o quanto essa estratégia é mais eficiente? Nós podemos reutilizar os nossos tokens. Reutilizar para formas novas palavras em português – por exemplo "bebaraço". E talvez reutilizar até em outros idiomas, como "-quit-" presente em "arquiteto" e que é de fato uma palavra em inglês.
E a nossa frase, como ficaria com essa estratégia de tokenização?

Caso queiram explorar mais o processo de Tokenização, podem usar o Tokenizador da OpenAI. Esta é a estratégia mais utilizada no momento para a formação dos tokens. Equilibra uma simplicidade maior do nosso dicionário de tokens, do nosso vocabulário, e também gera menos tokens ao final da conversão.
Portanto, um Token é essa unidade de texto, muitas vezes uma fração de palavra. É uma definição estática. Determinado token sempre vai ter o mesmo índice. Dessa forma conseguimos converter o texto em número e número novamente em texto. Este é o primeiro passo.
Mas nossa proposta é falar de Token e Embedding. Mas cadê o Embedding nessa história?
Embedding tem a sua posição e lugar
Enquanto o Token é uma representação mais estática de unidades de texto, o Embedding é um pouco mais dinâmico. Embedding é a representação vetorial do texto em um espaço multidimensional. Parece confuso e super avançado, né? Vamos tentar simplificar.
Nós podemos imaginar os Embeddings como pontos, com coordenadas. Enquanto o Token "quit" vai ter sempre o ID 47391, no Tokenizador acima (desde que o Tokenizador não mude), o Embedding pode mudar sua posição, dependendo do contexto.
Vamos imaginar um espaço vetorial de duas dimensões. Um plano, com um eixo horizontal e um vertical. Duas coordenadas.
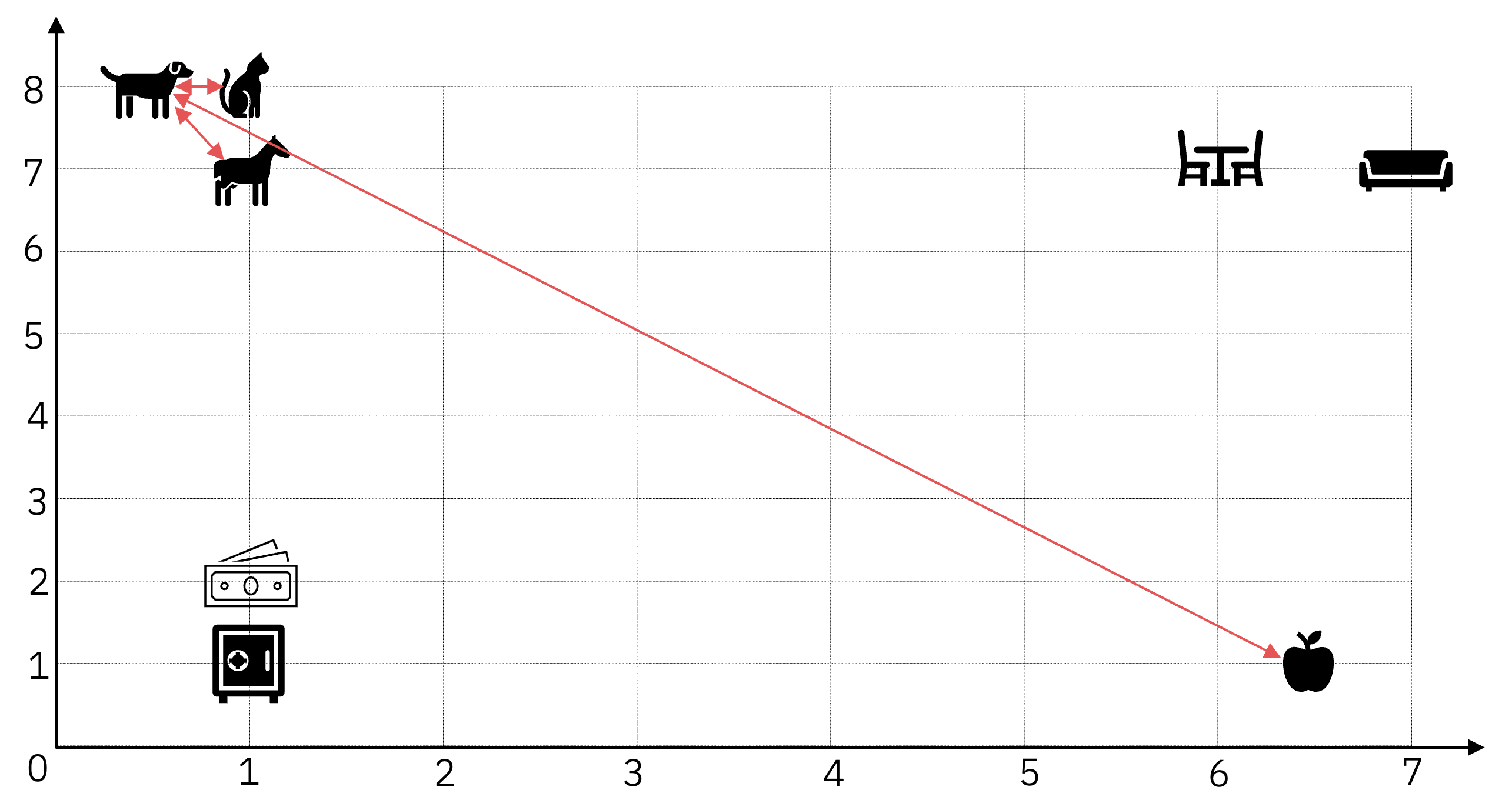
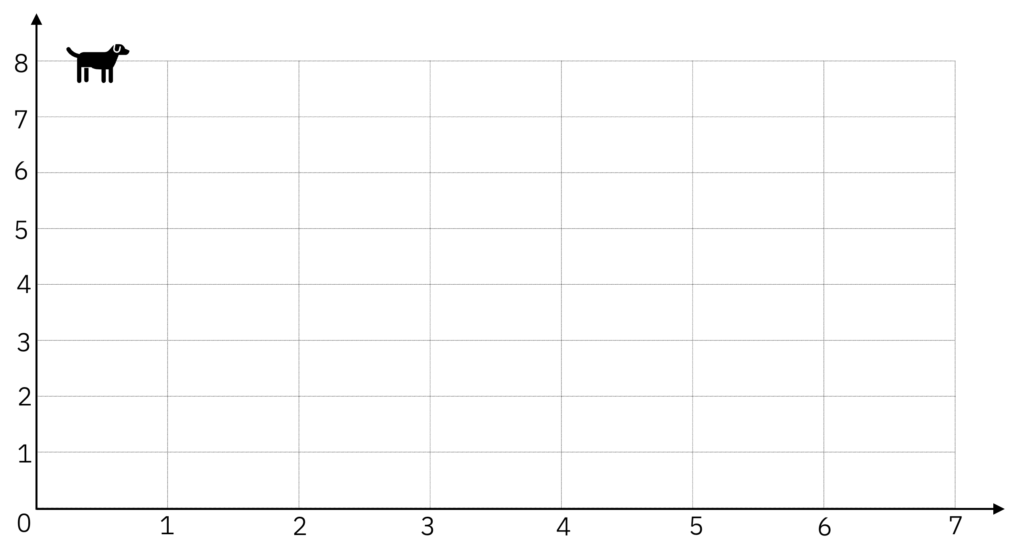
Ao receber uma palavra como entrada, o modelo (ou a camada) de Embeddings irá pegar essa palavra e posicioná-la em um ponto no seu espaço amostral. Vamos supor que a palavra de entrada é "cachorro" – e note aqui que a entrada pode ser um único Token, uma palavra, ou um texto mais longo – e o modelo posiciona essa palavra nas coordenadas (0.5, 8).
"cachorro" como Embedding tem sua posição em coordenadas.Uma próxima palavra, como a palavra "gato", o modelo de Embeddings vai posicionar essa palavra próxima à palavra "cachorro", dado que são palavras similares. O modelo poderia posicionar "gato" na posição (1, 8), por exemplo.
Caso uma próxima palavra seja "cavalo", o modelo poderia entender que ainda estamos falando de animais, e também posicioná-la perto do cachorro e do gato. Como por exemplo nas coordenadas (1, 7).
No caso de aparecer uma palavra diferente, como "sofá", que não é um animal e não tem muito a ver com as palavras anteriores, esse modelo posicionaria essa palavra em uma coordenada mais distante, como na posição (7, 7). Mais próximo de mesa e cadeira talvez.
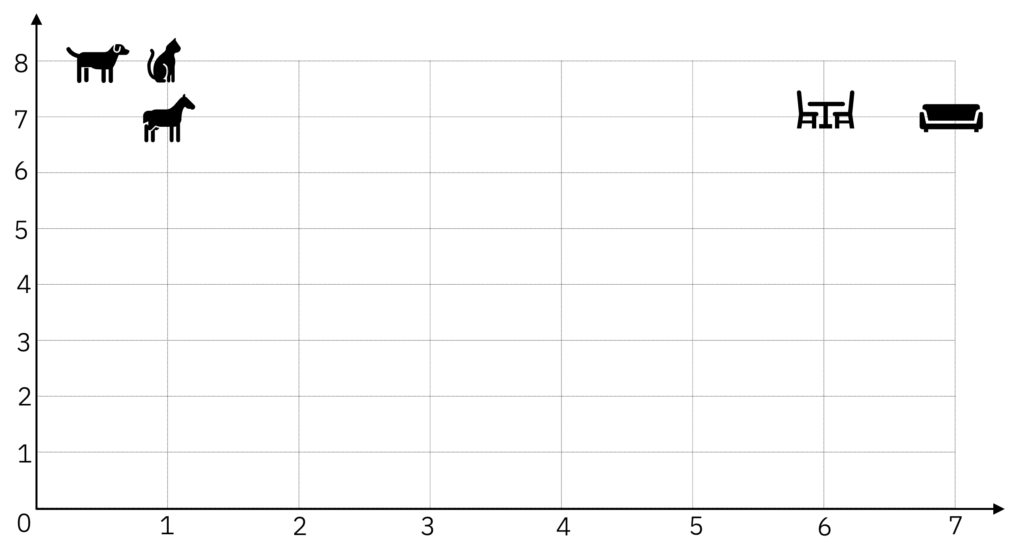
Palavras em vetores
Nosso modelo poderia continuar recebendo palavras e as posicionando no seu espaço vetorial. Note que os Embeddings são justamente as coordenadas. Ou seja, as palavras se tornam vetores, com uma posição definida: direção e intensidade, partindo da origem.
Uma forma um pouco mais fiel de se visualizar, seria de fato a representação como vetores, partindo da origem.
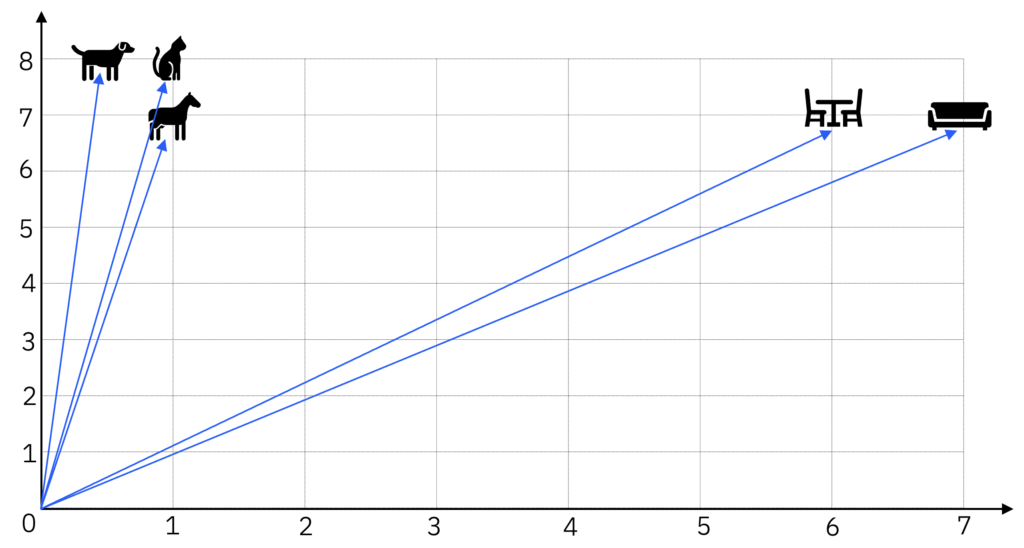
Para facilitar a visualização, iremos omitir as setas representando os vetores, ok?
Vamos ver algumas outras palavras se convertendo em vetores, cada um com a sua coordenada.
Repare que palavras similares, tendem a se agrupar. São pontos com coordenadas próximas. Ou vetores similares, para sermos mais exatos.
E quando esse modelo recebe uma palavra nova, como "abacaxi", ele sabe exatamente onde colocar. Muito provavelmente na região onde estão outras frutas.
"abacaxi" sendo transformada em EmbeddingPorém o que você acha que aconteceria se surgisse a palavra "banco" para o nosso modelo? Onde você acha que o modelo posicionaria este Embedding? Responda antes de continuar com a leitura.
"banco" ficaria neste espaço vetorial?Qual sua opinião?
A importância do contexto
Se a sua resposta foi “depende”, parabéns! Você acertou. E vai depender justamente do contexto. E para entender todo o contexto, é onde o Mecanismo de Atenção faz toda a diferença. Por conta da nossa arquitetura, podemos entender todo o contexto em que a palavra se encontra.
Vamos supor que tenhamos duas frases que se transformarão em Embeddings.
- “Estava no banco ___________________.”
- “Escolha um banco __________.”
O significado da palavra “banco” vai variar de acordo com as palavras que a cercam. Vamos explorar o contexto.
Agora sim conseguimos distinguir o que "banco" significa em cada um dos cenários. No primeiro é o banco de instituição bancária e o segundo é o banco de sentar-se. Dado que o modelo agora conhece o contexto, ele consegue posicionar corretamente cada um desses Embeddings.
Agora o modelo consegue posicionar os Embeddings com maior precisão.
Distâncias e Similaridades
Comentamos que os modelos – ou as camadas – de Embeddings tendem a posicionar seus Tokens, ou palavras, ou textos, similares próximos uns dos outros. E dado que cada Embedding tem a sua posição exata, nós conseguimos medir distâncias entre eles.
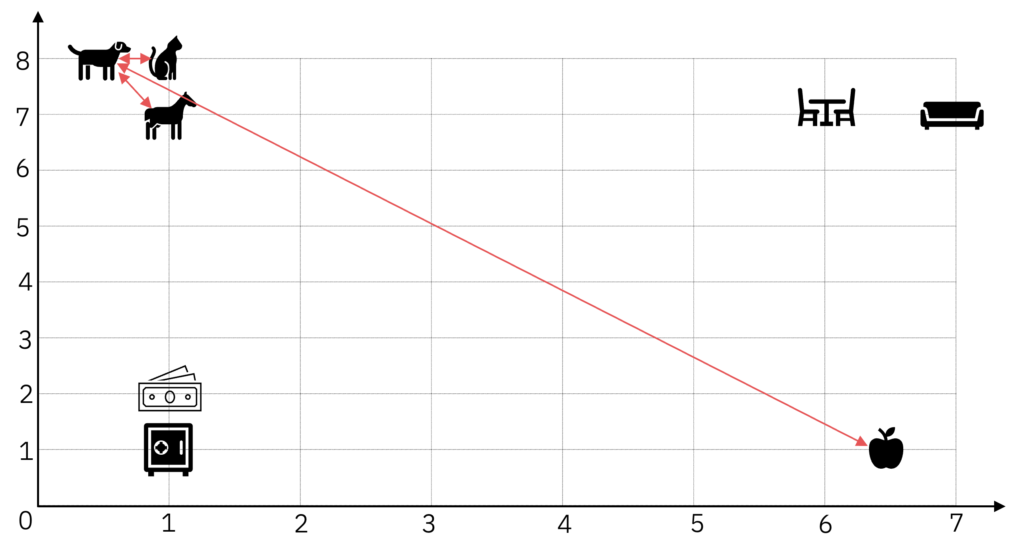
Se medirmos, na prática, vamos ver que a distância entre "cachorro" e "gato", e "cachorro" e "cavalo" é muito menor do que entre, por exemplo, "cachorro" e "maçã".
Embeddings semelhantes vão estar próximos, com uma distância curta entre si, e Embeddings distintos (ou opostos) estão distâncias, com uma grande distância entre si.
Para exemplificar, usamos a Distância Euclidiana (L2-Norm), em linha reta. Há outras formas de se medir distância, mas falaremos sobre isso em breve.
O princípio da similaridade de Embeddings é extremamente importante. E é também a base de aplicações extremamente populares dos Large Language Models (LLMs), como por exemplo a técnica de Retrieval Augmented Generation (RAG), que também abordaremos em breve aqui, na teoria e na prática.
Embeddings realistas
Para fins didáticos e de visualização, nós representamos os Embeddings em apenas duas dimensões. Seres humanos conseguem visualizar em até 3D, ou três dimensões. Ficaria mais difícil de representar visualmente tudo aqui em 3D, mas seria basicamente adicionarmos um terceiro eixo, uma terceira coordenada, ou uma terceira dimensão.
Duas ou três dimensões são muito pouco para representarmos os Embeddings reais de forma eficiente. Na prática, trabalhamos com Embeddings que têm em torno de 512 a 4096 dimensões.
As coordenadas reais dos Embeddings, seriam algo mais ou menos assim.

Mas não se assuste. Todos os conceitos explicados e exemplificados em duas dimensões se aplicam independente de quantas dimensões forem. De qualquer forma, cada Embedding tem suas coordenadas exatas, que representam a direção e intensidade do vetor. Embeddings similares tenderão a se agrupar, ficando mais próximos uns dos outros. E da mesma forma, podemos medir a distância entre Embeddings.
Em mais de três dimensões, estamos nos referindo a um Hiperplano. Mas podemos também ter Embeddings em Hiperesferas, por exemplo.
Conclusão
Os conceitos de Token e Embedding são conceitos básicos para se trabalhar com modelos generativos do tipo LLM. Porém não são triviais em um primeiro contato, e acredito que muitas pessoas até usem essas palavras no dia a dia sem de fato entender o que cada uma delas significa.
Tentei simplificar aqui bastante os conceitos, mas espero não ter simplificado demais. Caso tenha algum feedback, principalmente sobre estar simplificado demais ou talvez por ainda estar um pouco complexo, entra em contato com a gente pelos comentários.
Espero que tenham gostado do conteúdo e em breve traremos ainda mais. O plano é ir aprofundando no tema aos poucos e trazer material prático também.
Se você quiser também colaborar trazendo conteúdo sobre ML, IA e Dados para o Brasil, em Português, conheça nossa comunidade. E para entender melhor nosso propósito e saber como colaborar, leia nosso post de introdução do BRAINS – Brazilian AI Networks.
E não se esqueçam que…


7 comentários
Olá! Gostei muito do artigo e entendi (ou acho que entendi) porque o modelo usa o embedding. Mas no seu exemplo, não alcancei como o modelo saberia posicionar o gato próximo ao cachorro. Isso fez parte do seu treino?
Olá! Entendi, ou acho que entendi, porque usamos embeddings. Mas não consegui alcançar no exemplo, como o modelo saberia que o gato deveria estar próximo do cachorro. Isso fez parte de seu treinamento?
Excelente explicação. Muito direta, simples e didática!
Gostaria de deixar uma revisão, acho que no paragrafo “ Se medirmos, na prática, vamos ver que a distância entre “cachorro” e “gato”, e “cachorro” e “cavalo” é muito maior entre, por exemplo, “cachorro” e “maçã”.” o correto seria menor e não maior.
Excelente conteúdo!
Explicou o assunto de uma forma extremamente simples e didática. Parabéns!
Gostaria de deixar apenas uma revisão no texto. No paragrafo “Se medirmos, na prática, vamos ver que a distância entre “cachorro” e “gato”, e “cachorro” e “cavalo” é muito maior entre, por exemplo, “cachorro” e “maçã”.”, o correto seria uma distancia muito menor, e não maior.
Boa xará! Muito obrigado pela observação e pelo comentário! Valeu mesmo, corrigido aqui!
Muito Obrigado. Me ajudou muito a entender o tema.