

Relendo sobre as Window Functions, ou “funções de janelamento”, e sua importância para a Engenharia de Dados, comecei a revisar o conteúdo e, além de perceber uma certa “desordem”, vi que estava mal explicado.
Aprendendo sobre o assunto e relendo conteúdo e livros a respeito, decidi recriar a sequência de artigos sobre esse tópico e trazer para o BRAINS de forma mais madura.
Desse modo, espero que curtam e que possa ajudá-los a dominar essa excelente ferramenta que a linguagem SQL oferece.
Enjoy!
Introdução
Window Function é uma função que, para cada linha, ela irá computar um valor escalar baseado no cálculo utilizado na função, utilizando um subconjunto de linhas como apoio.
Ao utilizar uma Window Function, o banco de dados abre uma “janela” para tal linha, realiza a operação com as linhas subsequentes dentro daquele determinado conjunto e finaliza a operação.
O que temos são subconjuntos dentro do conjunto maior que é a tabela do resultado.
A cláusula que abre a Window Function é a função OVER.
Utilizando Window Functions não perdemos nenhum detalhe dos dados trabalhados. Como ela gera uma nova coluna com resultados escalares, não há perda de informação na query.
Mesmo utilizando ORDER BY na sua estrutura, esse ordenamento não influencia na visualização do resultado. Ele é aplicado apenas para cálculo do resultado.
A função OVER utilizada na Window Function possui três atributos: window-partitioning, window-order e window-frame.
Window-partition → limita a ação da query ao subconjunto da coluna informada, cujos valores sejam iguais no particionamento.
Window-order → ordena a operação no conjunto de dados sem interferir na apresentação final da query.
Window-frame → é o que cria o subconjunto através de filtros de exibição do particionamento.
No processamento lógico, a Window Function só “acontece” na fase do SELECT, assim como ORDER BY. Nesse caso, em muitas situações, o uso de CTE será bem-vindo.
As funções que fazem parte do conjunto das Window Functions são: RANK, LAG, LEAD, CUME_DIST, PERCENTILE_CONT, PERCENTILE_DISC etc.
Como funcionam as Window Functions?
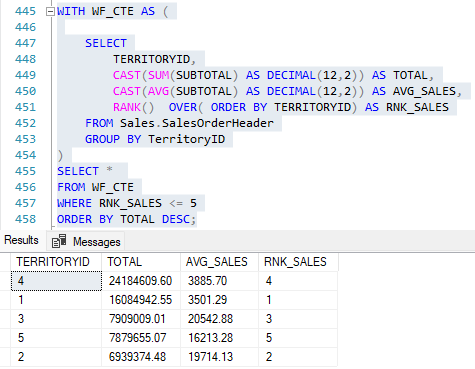
Suponhamos que uma consulta simples é realizada no banco AdventureWorks para retornar o ranking com as vendas do último ano corrente de acordo com cada região. Temos o seguinte resultado:
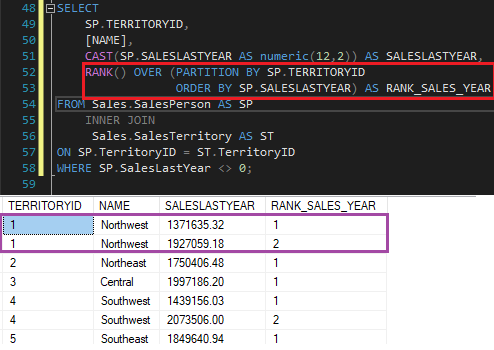
Repare que o resultado está sendo exibido e comparado entre os IDs dos territórios e sempre que muda o território, a contagem reinicia.
Mesmo utilizando ORDER BY na sua estrutura, esse ordenamento não influencia na visualização do resultado.
Isso ocorre devido a cláusula PARTITION BY que cria uma divisão de acordo com a coluna passada para que a função RANK atue (OVER) nesta coluna.
Por que utilizar Window Functions?
Veja a query abaixo:

Mesmo utilizando CTE, a legibilidade da query fica comprometida. Como temos algumas agregações e expressões, colocar em uma única declaração deixaria o código ainda maior.
Se fosse adicionar ainda mais cálculo na consulta, ficaria ainda pior:
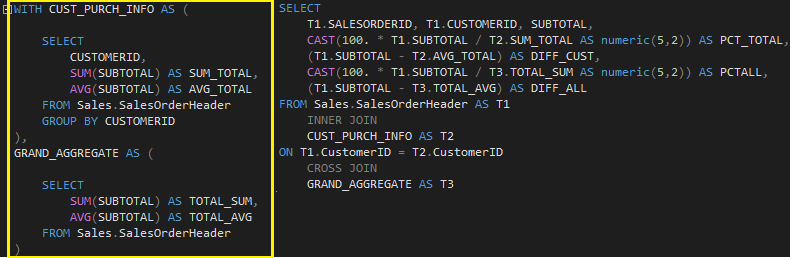
Quanto mais cálculos forem adicionados, pior será para a leitura e consequentemente, manutenção do código.
E é por isso que o uso e domínio de WF são tão importantes. Veja os dois exemplos reconstruídos.
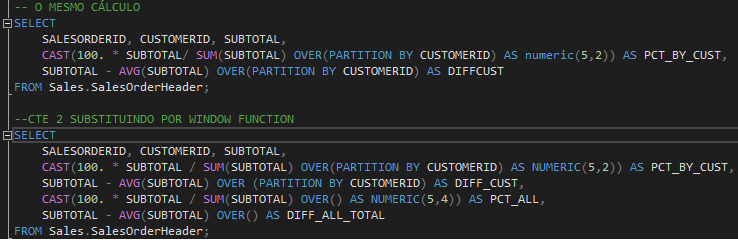
Podemos destacar que em nenhum caso houve uso de GROUP BY nas consultas.
O código além de mais legível, agora é mais fácil de manusear. Window Function é um dos melhores recursos dentro da linguagem SQL para domínio e construção de análises de dados.
Imagine uma sequência de valores aleatórios sem ordenamento e queremos descobrir as suas sequências e seu ponto de finalização.
Elementos das Window Functions
Vimos que os elementos principais de uma WF são: particionamento, ordenamento e tamanho (frame).
Nem todas as funções aceitam os três elementos em seu uso.
Começando pelo PARTITIONING, ele cria um subconjunto dentro do conjunto de resultados da query.
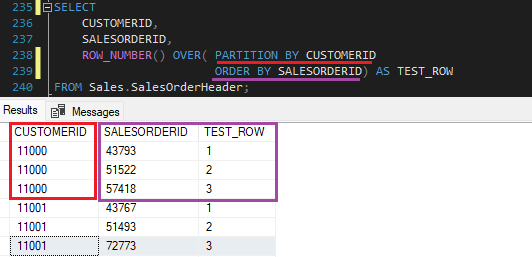
A coluna CUSTOMERID é a coluna utilizada para partição, como fatias de dados. Já a coluna SALESORDERID serve para ordenar o resultado para a função ROW_NUMBER.
A função OVER indica para a ROW_NUMBER onde ela deve trabalhar. Ela então numera cada linha dentro da partição de acordo com a coluna e “direção” do ordenamento no ORDER BY.
Dependendo da construção da query, a última função que possui o particionamento é quem ditará como o resultado será exibido.
Veja este primeiro exemplo de vendas por território.
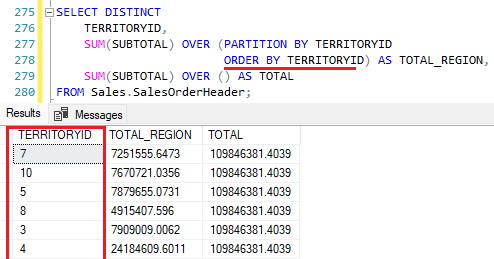
Embora tenha ordenado a WINDOW FUNCTION com o ORDER BY, o resultado exibido está completamente desordenado.
Agora, quero chamar atenção para a próxima consulta, que é uma extensão da última.

Podemos perceber que mesmo que as duas sejam ordenadas, o que vai “influenciar” no resultado é a última query.
E o mesmo vale para o particionamento (PARTITION BY), como podemos observar na query abaixo:
A query está retornando a quantidade de produtos na ordem de pedido. Ainda que nas outras colunas tenhamos particionado por ProductID, o que valeu mesmo foi SalesOrderID.
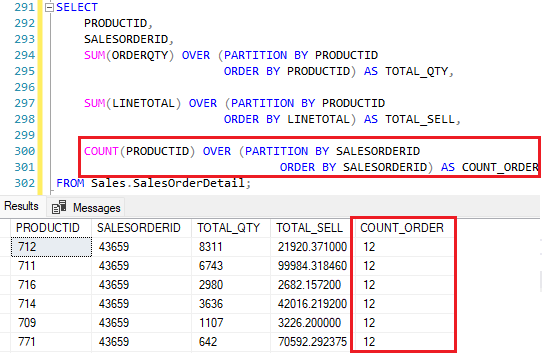
No exemplo abaixo, como o particionamento foi feito para a segunda coluna, RN. A primeira função ROW_NUMBER retorna o número daquela linha como um todo, isso é, no conjunto “global” do resultado.

Veja que o pedido 57418 em uma coluna possui a posição 13760 e na outra 3. Indicando que em uma há o particionamento e na outra não.
Um uso interessante para funções de rank: Clientes que possuem uma determinada quantidade de compras.
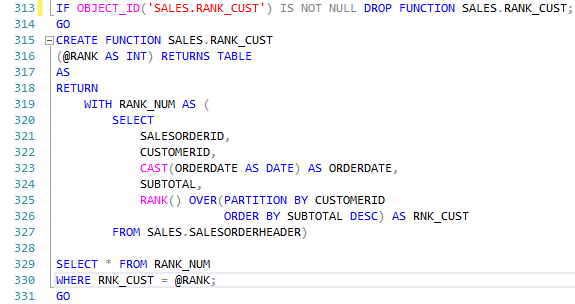
Agora, selecionando apenas os clientes que possuem 10 compras.
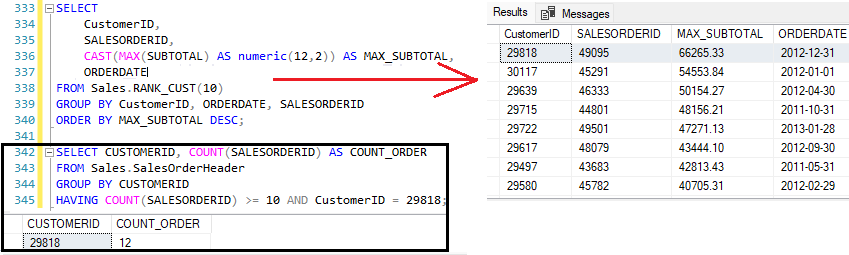
Além dos clientes, retorna a quantia gasta na compra de maior valor daquele cliente.
O ordenamento da Window Function especifica a ordem de cálculo dentro do subconjunto particionado. Sempre que um novo particionamento inicia, o ordenamento assim também inicia.
Quando utilizamos funções de agregação, o ordenamento age de uma forma diferente, comparado com o uso na função de RANK.
Nota: Sempre que houver NULLs no resultado, ele virá nas primeiras linhas. SQL Server ordena dessa forma implicitamente.
Já o FRAMING é uma espécie de filtro dentro da Window Function que restringe as linhas particionadas.
Dependendo do tipo de framing, ele ditará como um determinado cálculo irá ocorrer.
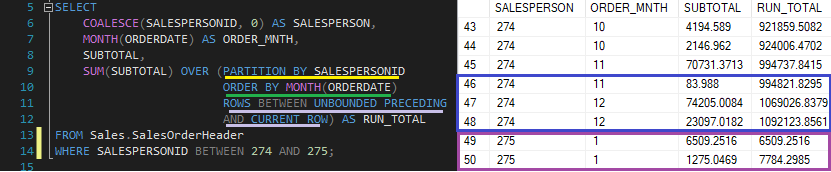
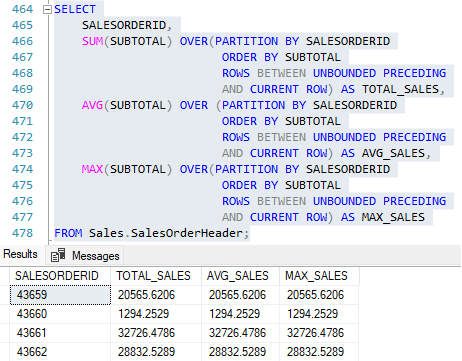
Então, quando abrimos a janela para a soma dos subtotais de cada cliente, o que a query faz com o frame gerado é somar a linha atual com a próxima e obter o resultado.
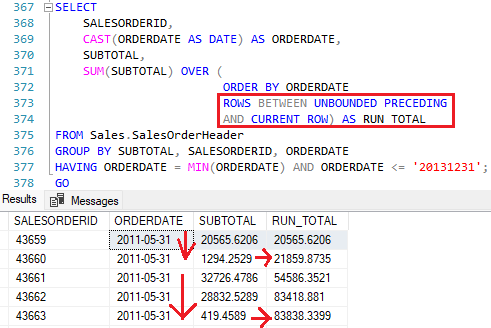
A query pegou o subtotal da coluna SalesOrderID 43659 e 43660 e somou, dando o resultado de: 21859.88.
Assim, temos o resultado para o total acumulado durante um determinado período de tempo.
Isso ocorre porque o frame especificado foi o ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
Outro ponto para se chamar atenção do frame dentro do particionamento é na forma como ocorre o cálculo. Analisando a coluna COUNT_ORDER, podemos notar que ela já entrega o resultado totalmente processado, mostrando o total das vendas processadas por cada vendedor.
Outra restrição importante para o funcionamento da WF é que ela vem antes da remoção de valores duplicados dentro da fase lógica. Então, se na sua query houver a cláusula DISTINCT, não irá funcionar
Passado para a coluna SALES_TOTAL, temos um processamento diferente. Aqui, cada linha é somada e obtêm-se o resultado da soma. O total acumulado.
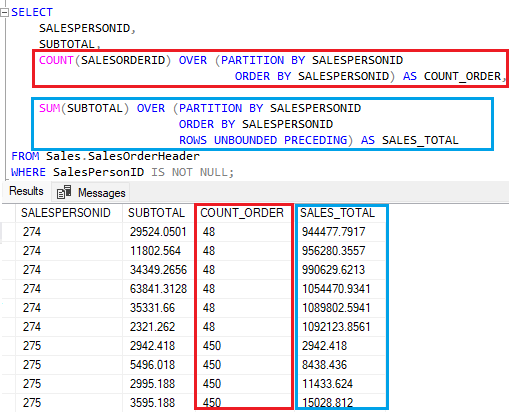
Existem outras maneiras de explorar o frame dentro da Window Function. Podemos inclusive especificar quantas linhas na operação.
Como esse artigo é introdutório e conceitual, aprofundarei nessas questões no artigo de continuação.
Restrição e o Processamento Lógico
Embora muito versátil, o recurso de Window Function funciona em situações específicas dentro do processamento lógico da query, isso é, somente no SELECT e ORDER BY.
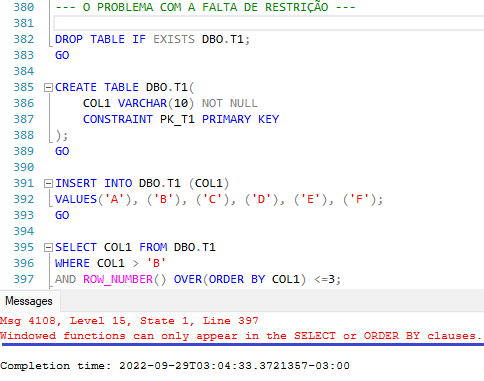
Essa restrição imposta serve para evitar ambiguidade ou alteração no resultado final decorrente do processamento da query elaborada.
Como o conceito all-at-once do SQL considera a query por um todo, a ambiguidade é reforçada.
Outra restrição importante para o funcionamento da WF é que ela vem antes da remoção de valores duplicados dentro da fase lógica. Então, se na sua query houver a cláusula DISTINCT, não irá funcionar.
O ordenamento da Window Function especifica a ordem de cálculo dentro do subconjunto particionado. Sempre que um novo particionamento inicia, o ordenamento assim também inicia.
Isso fica muito claro quando utilizamos ROW_NUMBER. Como ela cria um valor único para cada registro, a cláusula DISTINCT entende que não há valores iguais.

Para remover duplicatas ao trabalhar com WF, precisamos de uma query intermediária, ou seja, CTE.
Podemos dizer que a Window Function irá utilizar o resultado final de toda operação da query antes do SELECT. Veja o próximo exemplo:
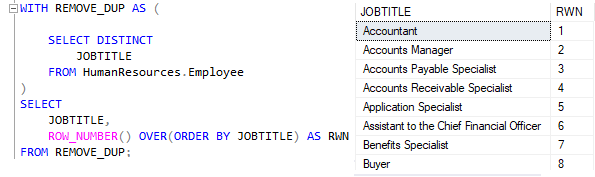
Outra forma de resolver o mesmo problema fora das Table Expression.
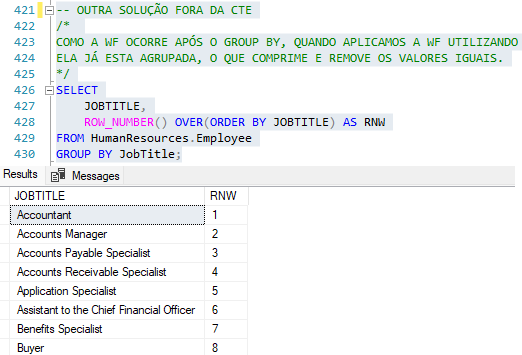
Sabendo que a WF atua entre o SELECT e o ORDER BY, é correto afirmar que não poderíamos filtrar ou selecionar algumas de suas computações em uma query normal. A forma mais comumente usada para isso é com o apoio das CTEs.
E por fim, um dos grandes problemas desta implementação no SQL Server é a indisponibilidade de reuso de código, sendo necessário, em alguns casos, criar extensas queries.
Conclusão
Window Functions são um importante recurso para dominar e trabalhar com SQL.
As funções desse grupo são capazes de entregar bastante resultado e ótimas análises sem causar grandes impactos no banco e com queries relativamente simplificadas.
Algumas funções como RANK e ROW_NUMBER exigem o uso de ordenamento, mas lembre-se que esse ordenamento não influencia no resultado final exibido.
O framing é uma excelente ferramenta para dominar e manipular. Podendo “customizar” o cálculo de acordo com a necessidade de negócio.
Por fim, mas não menos importante, não se esqueça que o processamento lógico ocorre após o SELECT. Dependendo do cenário, Table Expressions serão bem-vindas.
Se chegou até aqui e gostou do pequeno tutorial, deixe um comentário e compartilhe. Nos ajude a construir a comunidade de AI mais unida do Brasil! Conheça um pouco mais sobre o BRAINS – Brazilian AI Networks.
#NoBrains #NoGains 🧠
CONTORNANDO LIMITAÇÕES


1 comentário