Nós já sabemos da importância de entendermos e conhecermos as Árvores de Decisão. Se você ainda não entende muito bem a teoria, recomendamos fortemente a leitura do post Árvores de Decisão: Algoritmos Baseados em Árvores. Um outro post importante para o entendimento completo desta prática é o Medidas de Performance: Modelos de Classificação.
Se você já conhece a teoria, vamos à prática!
Você pode executar e editar todo o código apresentado aqui num Notebook no Google Colab, se preferir.
Objetivos
Para minimizar as perdas de um banco fictício, precisamos desenvolver um processo de tomada de decisão sobre para quem o banco deve aprovar empréstimos e para quem não. Os perfis demográfico e socioeconômico do cliente são considerados pelos fictícios gerentes de empréstimos antes da tomada de decisão sobre o pedido de empréstimo.
Com base na base de dados de clientes que pegaram empréstimos no banco fictício, temos classificados os clientes inadimplentes e os clientes e quitaram as suas dívidas.
Nosso objetivo é construir um Modelo de Machine Learning que irá prever se um cliente que aplica para um empréstimo pode ser ou não um cliente inadimplente.
Descrição dos Dados
Nossa base de dados é um dataset público, disponibilizado pelo Center for Machine Learning and Intelligent Systems da Universidade da Califórnia, UCI.
Link do dataset: https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data)
Nota: Trata-se de um dataset de um banco da Alemanha, doado para uso público em 1994. Toda a base de dados original está em Inglês. Foi feita uma tradução livre e pequenas manipulações de dados para fins didáticos.
A base de dados é composta pelas seguintes colunas.
- saldo_corrente: saldo na conta corrente (categórica).
- duracao_emp_meses: duração do empréstimo, em meses (numérica).
- historico_credito: histórico de crédito (categórica).
- motivo: motivo para pedido de empréstimo (categórica).
- quantia: valor do empréstimo pedido (numérica).
- saldo_poupanca: saldo na conta poupança (categórica).
- tempo_empregado: tempo no emprego atual (categórica).
- porcentagem_renda: porcentagem da renda comprometida pela parcela do empréstimo (numérica).
- anos_residencia: tempo de moradia na residência atual, em anos (numérica).
- idade: idade do cliente, em anos (numérica).
- outro_credito: se o cliente possui empréstimos em outros estabelecimentos (categórica).
- residencia: se mora em residência própria ou alugada (categórica).
- qtd_emprestimos_existentes: quantidade de empréstimos existentes neste banco (numérica).
- emprego: categoria de emprego (categórica).
- dependentes: quantidade de dependentes (numérica).
- telefone: se o cliente possui telefone, informação relevante na época (categórica).
- inadimplente: classificação se o cliente foi inadimplente ou não, nossa variável alvo.
Importando as Bibliotecas
# Manipulação de dados
import numpy as np
import pandas as pd
# Visualização de dados
import matplotlib.pyplot as plt
import seaborn as sns
# Divisão dos dados
from sklearn.model_selection import train_test_split
# Algoritmos de Machine Learning
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
# Métricas de performance
from sklearn import metrics
from sklearn.metrics import (f1_score,
accuracy_score,
recall_score,
precision_score,
confusion_matrix,
plot_confusion_matrix,
roc_auc_score)
# Ajustes de Hiperparametros
from sklearn.model_selection import GridSearchCV
# Optional para Annotations das funções
from typing import Optional
# Ignorar alertas
import warnings
warnings.filterwarnings('ignore')
Nós iremos construir nosso modelo de Árvores de Decisão usando a biblioteca scikit-learn.
Carregando e Explorando os Dados
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# Local do dataset online
url_dataset = 'https://raw.githubusercontent.com/lopes-andre/datasets/main/credito.csv'
# Carrega os dados em um DataFrame
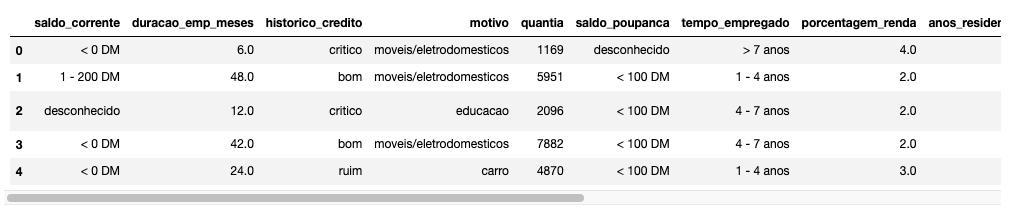
data = pd.read_csv(url_dataset)
data.head()
# Verifica o shape dos dados
print(f'Shape dos dados: {data.shape}\n')
print(f'Esta base de dados tem {data.shape[0]} linhas e {data.shape[1]} colunas.')
Temos como saída:
Shape dos dados: (1000, 17)
Esta base de dados tem 1000 linhas e 17 colunas.
E com apenas uma linha de código conseguimos extrair todo o resumo estatístico dos dados.
# Resumo Estatístico dos dados
data.describe()
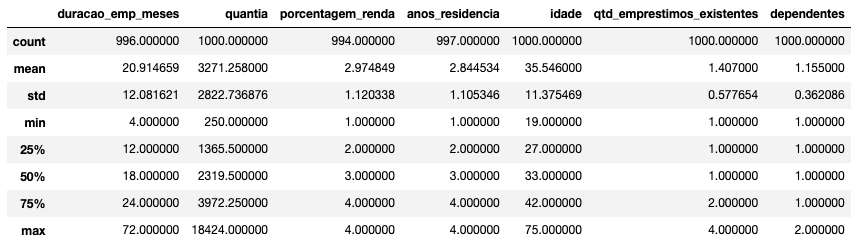
Observações
- Nós podemos com apenas uma linha de código ver todo o resumo estatístico dos dados.
- Este método nos retorna as seguintes informações:
- Contagem de entradas de cada coluna.
- Média.
- Desvio Padrão.
- Valores mínimo e máximo de cada coluna.
- Primeiro quartil, Mediana e terceiro quartil.
- Todas as entradas numéricas são retornadas.
Para analisar os dados das colunas Categóricas, podemos usar um outro trecho de código. A célula abaixo irá isolar as colunas do tipo object e analisar as entradas de cada uma destas colunas.
# Lista de variáveis categóricas
colunas_cat = data.select_dtypes(include=['object']).columns.tolist()
# Loop para imprimir a contagem de valores únicos em cada coluna categórica
for coluna in colunas_cat:
print(f'### Coluna <{coluna}> ###')
print(data[coluna].value_counts())
print('-' * 40)
E a saída é:
### Coluna <saldo_corrente> ###
desconhecido 394
< 0 DM 274
1 - 200 DM 269
> 200 DM 63
Name: saldo_corrente, dtype: int64
----------------------------------------
### Coluna <historico_credito> ###
bom 530
critico 293
ruim 88
muito bom 49
perfeito 40
Name: historico_credito, dtype: int64
----------------------------------------
### Coluna <motivo> ###
moveis/eletrodomesticos 473
carro 337
negocios 97
educacao 59
renovacao 22
carr0 12
Name: motivo, dtype: int64
----------------------------------------
### Coluna <saldo_poupanca> ###
< 100 DM 603
desconhecido 183
100 - 500 DM 103
500 - 1000 DM 63
> 1000 DM 48
Name: saldo_poupanca, dtype: int64
----------------------------------------
### Coluna <tempo_empregado> ###
1 - 4 anos 339
> 7 anos 253
4 - 7 anos 174
< 1 ano 172
desempregado 62
Name: tempo_empregado, dtype: int64
----------------------------------------
### Coluna <outro_credito> ###
nenhum 814
banco 139
loja 47
Name: outro_credito, dtype: int64
----------------------------------------
### Coluna <residencia> ###
propria 713
alugada 179
outros 108
Name: residencia, dtype: int64
----------------------------------------
### Coluna <emprego> ###
qualificado 630
nao-qualificado 200
gerencial 148
desempregado 22
Name: emprego, dtype: int64
----------------------------------------
### Coluna <telefone> ###
nao 596
sim 404
Name: telefone, dtype: int64
----------------------------------------
### Coluna <inadimplente> ###
nao 700
sim 300
Name: inadimplente, dtype: int64
----------------------------------------
Com mais apenas uma linha podemos verificar os tipos de dados de cada coluna.
# Verifica os tipos das colunas e quantidade de entradas
data.info()

Repare que temos dados nulos/faltantes, pois nem todas as colunas possuem 1000 entradas não-nulas.
Vamos executar um código para verificar exatamente quantos dados faltantes cada coluna tem.
# Verificando dados nulos
print('Colunas com dados nulos:')
display(data.isnull().sum()[data.isnull().sum() > 0])

Observações sobre o Resumo dos Dados
- Os valores monetários estão em Deutsche Mark (DM), moeda da Alemanha na época, anterior ao Euro.
- As colunas
duracao_emp_meses,porcentagem_rendaeanos_residenciatêm valores nulos/faltantes. Valores nulos podem causar resultados inesperados em modelos preditivos, portanto iremos tratar esses valores com Engenharia de Atributos. - A média de idade é aproximadamente 35 anos e a mediana é 33 anos.
- A média de valor dos empréstimos está em torno de 3271 DM (Deutsche Mark), mas há um grande range de 250 DM a 18434 DM. Poderíamos analisar melhor estes dados na Análise Exploratória de Dados.
- A média de parcelas dos empréstimos está em torno de 21 meses e a mediana em 18 meses.
- Temos poucos clientes desempregados na base de dados.
- Há uma classe na coluna
motivoque parece ter sofrido erro de digitação. Iremos tratar isso com a Engenharia de Atributos. - A nossa variável alvo,
inadimplente, está desbalanceada. Apenas 30% das observações estão na Classe 1 (inadimplente) e 70% na Classe 0 (não inadimplente).
A Análise Exploratória dos Dados para este Dataset pode ficar bem extensa, portanto deixaremos para abordar ela completa em outro post, ok?
Vamos direto para a Engenharia de Atributos (ou Feature Engineering).
Engenharia de Atributos
Durante a fase de Engenharia de Atributos iremos preparar o dataset para a modelagem preditiva. Poderíamos ter realizado algumas dessas transformações antes da Análise Exploratória de Dados, mas para fins didáticos centralizamos aqui nesta sessão todos os passos.
Corrigindo Erros nos Atributos
Como mencionado acima, há um erro de digitação em uma das categorias do atributo motivo . Vamos analisar este ponto e corrigir conforme necessário.
# Exibe as categorias da variável motivo
data['motivo'].value_counts()

Vamos corrigir as entradas com "carr0" e substituir essas entradas por "carro", como deveria ser.
# Corrige o erro de digitação
corrige_carro = {'carr0': 'carro'}
data.replace(corrige_carro, inplace=True)
# Verifica as categorias novamente
data['motivo'].value_counts()

Note que a entrada "carr0", que era aparentemente um erro de digitação, já não existe mais.
O problema foi corrigido. Nós substituímos as entradas "carr0" por "carro".
Transformando Variáveis Categóricas em Numéricas para Modelagem
A maioria dos algoritmos de Machine Learning não lidam bem com variáveis categóricas em forma de texto. Para isto, precisamos converter as variáveis categóricas em numéricas, para facilitar os cálculos matemáticos dos algoritmos.
As variáveis ordinais, que apresentam uma ordem lógica, podem ser convertidas usando a mesma função acima, porém com uma lógica diferente: atribuindo valores numéricos sequenciais.
# Convertendo variáveis Categóricas Ordinais
conversao_variaveis = {
'saldo_corrente': {
'desconhecido': -1,
'< 0 DM': 1,
'1 - 200 DM': 2,
'> 200 DM': 3,
},
'historico_credito': {
'critico': 1,
'ruim': 2,
'bom': 3,
'muito bom': 4,
'perfeito': 5
},
'saldo_poupanca': {
'desconhecido': -1,
'< 100 DM': 1,
'100 - 500 DM': 2,
'500 - 1000 DM': 3,
'> 1000 DM': 4,
},
'tempo_empregado': {
'desempregado': 1,
'< 1 ano': 2,
'1 - 4 anos': 3,
'4 - 7 anos': 4,
'> 7 anos': 5,
},
'telefone': {
'nao': 1,
'sim': 2,
}
}
data.replace(conversao_variaveis, inplace=True)
data.sample(5)

OneHotEncoding para Variáveis Não Ordinais
Para variáveis categóricas podemos aplicar a técnica de OneHotEncoding. Nesta técnica, cada categoria se transforma em uma coluna de valores binários (0 ou 1). Por exemplo, o atributo motivo que possui 5 categorias, vai se transformar em 4 colunas distintas.
Exemplo
O atributo motivo possui 5 categorias:
- moveis/eletrodomesticos
- carro
- negocios
- educacao
- renovacao
Ao aplicar a técnica de OneHotEncoding, o DataFrame ficaria da seguinte forma.
| motivo | motivo_carro | motivo_negocios | motivo_educacao | motivo_renovacao |
|---|---|---|---|---|
| carro | 1 | 0 | 0 | 0 |
| negocios | 0 | 1 | 0 | 0 |
| educacao | 0 | 0 | 1 | 0 |
| renovacao | 0 | 0 | 0 | 1 |
| moveis/eletrodomesticos | 0 | 0 | 0 | 0 |
Para evitar a Multicolinearidade, nós configuramos a função para dropar a primeira coluna, pois ela não é necessária. Caso a observação não se encaixe em nenhuma das 4 categorias acima, ela obviamente vai se encaixar na quinta, que no nosso caso é a moveis/eletrodomesticos . 0 em todas as colunas significa que está nesta categoria.
Como essa técnica de OneHotEncoding deve ser aplicada apenas sobre as colunas categóricas, vamos isolar esse tipo de colunas.
# Gera a lista de variáveis categóricas
cols_cat = data.select_dtypes(include='object').columns.tolist()
# Removendo 'inadimplente' pois é nossa variável Alvo
cols_cat.remove('inadimplente')
cols_cat
E ao verificarmos quais colunas estão na lista, temos:
['motivo', 'outro_credito', 'residencia', 'emprego']
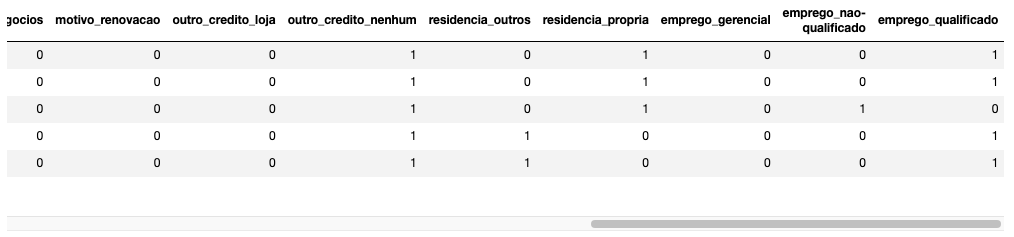
E, finalmente, implementamos o OneHotEncoding.
# Implementa o OneHotEncoding
data = pd.get_dummies(data, columns=cols_cat, drop_first=True)
data.head()
Convertendo a Variável Alvo
A nossa variável alvo, inadimplente é a única variável que ainda precisa ser convertida. Para classificação binária (duas classes) vamos dividir as classes em Classe 0 (não) e Classe 1 (sim).
Ficando desta forma as entradas 0 para não inadimplentes e 1 para clientes inadimplentes.
# Convertendo a variável alvo
conversao_alvo = {
'inadimplente': {'nao': 0, 'sim': 1}
}
data.replace(conversao_alvo, inplace=True)
data['inadimplente']

Lidando com Valores Faltantes
Existem diversas formas de tratar valores faltantes. Nós podemos remover as entradas, substituir os valores faltantes com a Média ou Mediana das colunas, ou muitas outras abordagens.
Ao invés de dropar/remover essas linhas com valores faltantes, iremos substituir os valores faltantes com a sua Média.
# Imputando os valores nulos com a média
data = data.fillna(data.mean())
E, novamente, verificamos se ainda há dados faltantes.
# Verifica valores nulos novamente
data.isnull().sum()

Não temos mais dados nulos/faltantes.
Neste ponto, finalizamos a preparação dos dados.
Divisão dos Dados
Iremos agora separar as características de cada paciente, as variáveis independentes, da nossa variável alvo, ou variável dependente.
Lembre-se que chamamos de X o conjunto de características (features) e chamamos de y a nossa resposta de interesse, nossa variável alvo a ser descoberta (target).
# Variáveis independentes (características)
X = data.drop(['inadimplente'], axis=1)
# Variável dependente (alvo)
y = data['inadimplente']
Precisamos agora dividir a nossa base de dados entre Treino e Teste. Já discutimos a importância desta divisão, onde separamos uma parte dos dados (70% neste caso) para realizarmos o treino do modelo e uma outra parte (30%) para testarmos e vermos se o modelo de fato aprendeu, ou se apenas “decorou” respostas e se “ajustou demais” ao problema (Overfitting).
Como temos um certo desbalanceio na nossa variável alvo, é interessante mantermos as mesmas proporções de classes positivas e negativas tanto na base de treino quanto na de teste. A divisão é aleatória, e não devemos perder esta proporção.
Para isso, iremos fazer uso do argumento stratify=y da função train_test_split() disponível na biblioteca Scikit-learn. Este argumento irá manter as devidas proporções das classes de y para treino e teste.
# Divisão dos dados em Treino e Teste
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.30,
random_state=1,
stratify=y) # mantém as proporções das classes
Lembram que as classes estavam desbalanceadas? Isso é de se esperar, pois muito provavelmente apenas uma parcela pequena de clientes de um banco devem ser inadimplentes.
Nesse nosso caso, temos 70% de clientes não inadimplentes (Classe 0) e 30% de clientes inadimplentes (Classe 1). Ao usarmos o argumento stratify=y na função train_test_split(), nós dizemos para a biblioteca manter essa proporção quando fizer a divisão entre bases de treino e base de teste.
Vamos verificar estas proporções.
# Verifica as proporções de classes nos dados
print('### Proporção de Classes em Treino ###')
print(f'Porcentagem de entradas Classe 0: {y_train.value_counts(normalize=True).values[0] * 100}%')
print(f'Porcentagem de entradas Classe 1: {y_train.value_counts(normalize=True).values[1] * 100}%')
print()
print('### Proporção de Classes em Teste ###')
print(f'Porcentagem de entradas Classe 0: {y_test.value_counts(normalize=True).values[0] * 100}%')
print(f'Porcentagem de entradas Classe 1: {y_test.value_counts(normalize=True).values[1] * 100}%')

Funções para Performance dos Modelos
Iremos agora declarar algumas funções úteis para monitorarmos a performance dos nossos modelos.
Se você precisa entender melhor como avaliamos modelos de classificação, recomendo fortemente a leitura do post Medidas de Performance: Modelos de Classificação.
def performance_modelo_classificacao(
model: object,
flag: Optional[bool] = True):
'''
Função para computar as diferentes métricas de performance para modelos de classificação.
model: modelo para prever os valores de X
flag: se imprimimos ou não os resultados
'''
# Lista para armazenar os resultados de Treino e Validação
score_list = []
# Predição em Treino e Validação
pred_train = model.predict(X_train)
pred_val = model.predict(X_test)
# Acurácia do modelo
train_acc = model.score(X_train, y_train)
val_acc = model.score(X_test, y_test)
# Recall do modelo
train_recall = recall_score(y_train, pred_train)
val_recall = recall_score(y_test, pred_val)
# Precisão do modelo
train_prec = precision_score(y_train, pred_train)
val_prec = precision_score(y_test, pred_val)
# F1-Score do modelo
train_f1 = f1_score(y_train, pred_train)
val_f1 = f1_score(y_test, pred_val)
# Popula a lista
score_list.extend((train_acc, val_acc, train_recall, val_recall, train_prec, val_prec, train_f1, val_f1))
# Imprime a lista se flag=True (default)
if flag:
print(f'Acurácia na base de Treino: {train_acc}')
print(f'Acurácia na base de Teste: {val_acc}')
print(f'\nRecall na base de Treino: {train_recall}')
print(f'Recall na base de Teste: {val_recall}')
print(f'\nPrecisão na base de Treino: {train_prec}')
print(f'Precisão na base de Teste: {val_prec}')
print(f'\nF1-Score na base de Treino: {train_f1}')
print(f'F1-Score na base de Teste: {val_f1}')
# Retorna a lista de valores em Treino e Validação
return score_list
def matriz_confusao(
model: object,
X: pd.DataFrame,
y_actual: pd.Series,
labels: Optional[tuple] = (1, 0)):
'''
Plota a Matriz de Confusão com porcentagens.
model: modelo para prever os valores de X
X: atributos usados para a classficação
y_actual: classificação real, variável alvo
'''
# Predição em Validação
y_predict = model.predict(X)
# Pega os dados da Matriz de Confusão
cm = confusion_matrix(y_actual, y_predict, labels=[0, 1])
df_cm = pd.DataFrame(cm, index=['Real - Não (0)', 'Real - Sim (1)'],
columns=['Previsto - Não (0)', 'Previsto - Sim (1)'])
# List of labels for the Confusion Matrix
group_counts = [f'{value:.0f}' for value in cm.flatten()]
group_percentages = [f'{value:.2f}%' for value in (cm.flatten()/np.sum(cm))*100]
labels = [f'{v1}\n{v2}' for v1, v2 in zip(group_counts, group_percentages)]
labels = np.asarray(labels).reshape(2, 2)
# Plot the Confusion Matrix
plt.figure(figsize=(10, 7))
sns.heatmap(df_cm, annot=labels, fmt='')
plt.xlabel('Classe Prevista', fontweight='bold')
plt.ylabel('Classe Verdadeira', fontweight='bold')
plt.show()
Treino dos Modelos de Árvores de Decisão
O treino do nosso primeiro modelo vai ser extremamente simples. Depois iremos adicionar um pouco de complexidade.
Nós iremos usar a classe sklearn.tree.DecisionTreeClassifier para construir de forma automatizada a nossa melhor Árvore de Decisão.
Para isso iremos instanciar um objeto DecisionTreeClassifier() e fazermos com que ele se ajuste aos nossos dados de treino, que é o nosso processo de treino, com o método .fit().
Criando e Treinando o Modelo de Árvores de Decisão
# Instanciando o Modelo
arvore_d = DecisionTreeClassifier(random_state=1)
# Treinando o modelo
arvore_d.fit(X_train, y_train)

Métricas do modelo de Árvores de Decisão
arvore_d_scores = performance_modelo_classificacao(arvore_d)
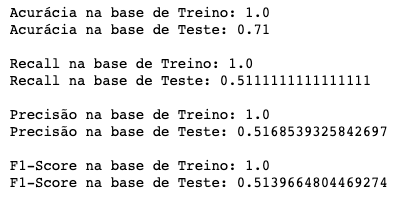
Perceberam um forte Overfitting? A Árvore de Decisão cresceu sem controle e acertou 100% de todas as observações de treino, mas falhou na base de teste. Aparentemente o modelo está decorando as respostas da base de treino e sua performance real está similar a jogar cara ou coroa.
Vamos tentar visualizar isso na Matriz de Confusão.
Matriz de Confusão para a Árvore de Decisão
# Matriz de Confusão de treino
matriz_confusao(arvore_d, X_train, y_train)

# Matriz de Confusão de teste
matriz_confusao(arvore_d, X_test, y_test)

Perceberam que na primeira matriz tivemos 0 erros e na segunda muitos erros?
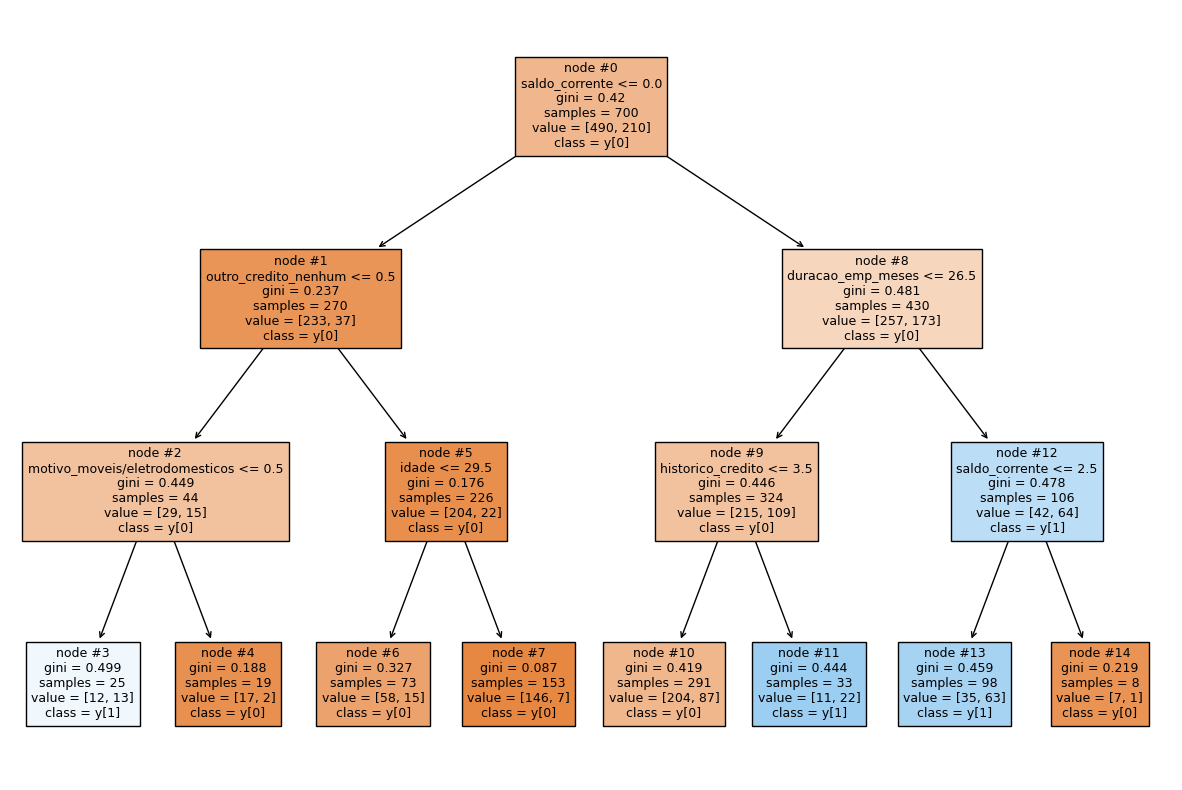
Vamos agora visualizar quais decisões essa árvore está tomando, e em que ordem.
Visualizando a Árvore de Decisão
feature_names = list(X_train.columns)
plt.figure(figsize=(20, 30))
tree.plot_tree(arvore_d, feature_names=feature_names, filled=True,
fontsize=9, node_ids=True, class_names=True);

É uma árvore extremamente complexa e profunda! Um modelo complexo demais tende ao Overfitting. Para evitar que nossas Árvores de Decisão crescam sem controle, nós vamos fazer uso de uma técnica de Poda. Vamos fazer a Pré-Poda, para sermos mais exatos.
Árvores de Decisão com Pré-Poda
Vamos, primeiramente, controlar a profundidade desta Árvore de Decisão a deixando mais simples. Para isso, vamos usar o parâmetro max_depth quando instanciarmos o objeto do modelo.
Criando e Treinando Árvores de Decisão Podadas
# Instanciando o Modelo
arvore_d1 = DecisionTreeClassifier(random_state=1, max_depth=3)
# Treinando o modelo
arvore_d1.fit(X_train, y_train)

Métricas do modelo de Árvores de Decisão Podada
arvore_d1_scores = performance_modelo_classificacao(arvore_d1)
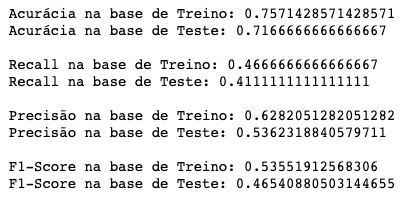
Agora parece que nós temos um Underfitting, concordam? Talvez o modelo esteja simples demais para aprender algo suficiente da base de treino.
Vamos analisar novamente a Matriz de Confusão.
# Matriz de Confusão de treino
matriz_confusao(arvore_d1, X_train, y_train)
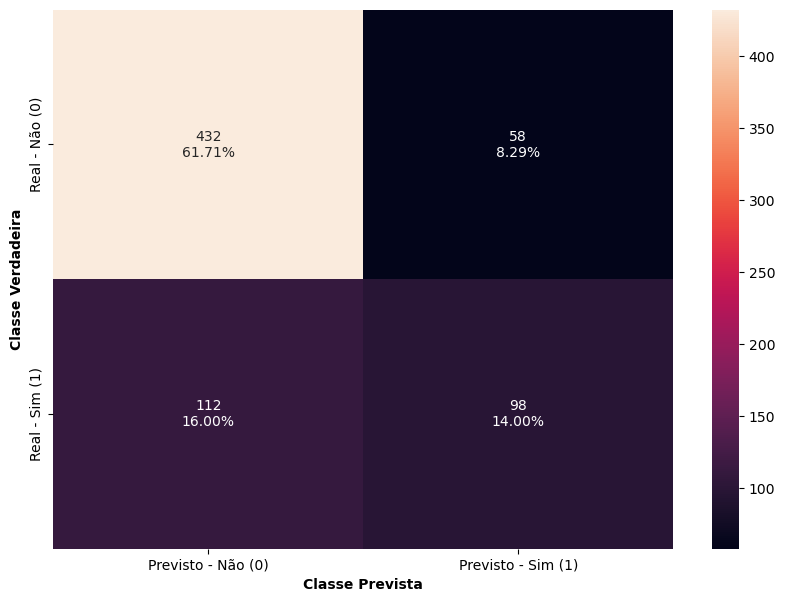
Visualizando o modelo de Árvores de Decisão Podada
feature_names = list(X_train.columns)
plt.figure(figsize=(15, 10))
tree.plot_tree(arvore_d1, feature_names=feature_names, filled=True,
fontsize=9, node_ids=True, class_names=True);
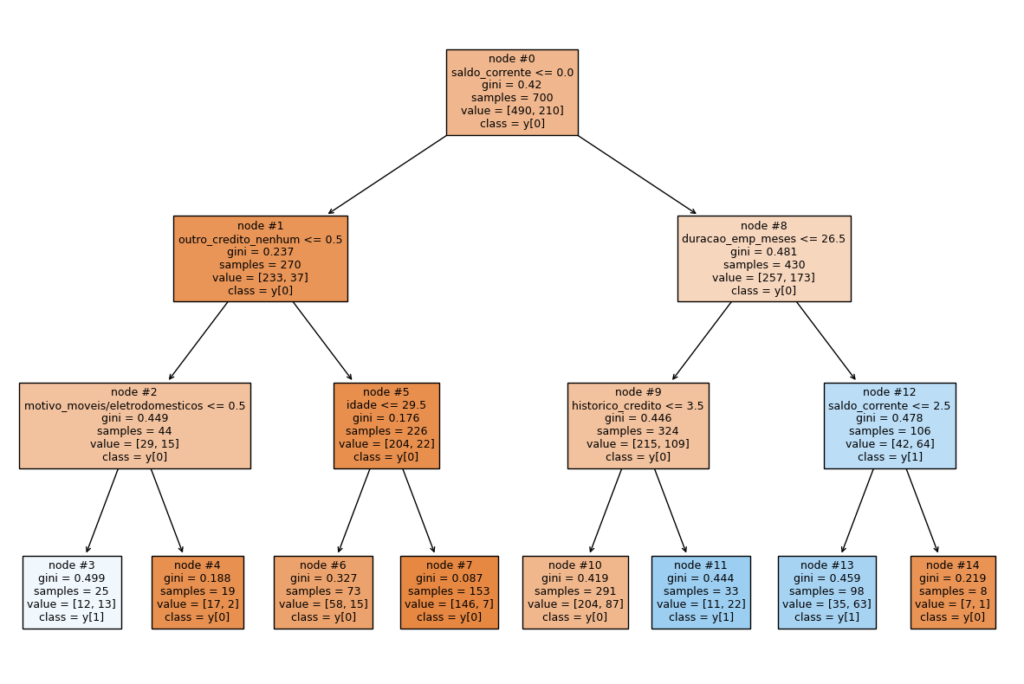
De fato a nossa Árvore de Decisão está bem simples. Aparentemente simples demais para nossos dados, causando assim um Underfitting.
Ajustar a profundidade máxima da árvore para três níveis não foi uma boa estratégia. Vocês devem se lembrar que temos outros parâmetros que podemos trabalhar para controlar o crescimento da árvore, certo? Se você não lembra, leia o post Árvores de Decisão: Algoritmos Baseados em Árvores.
Mas como encontrar os valores ideais de parâmetros?
Ajuste de Hiperparâmetros
O Ajuste de Hiperparâmatros (do Inglês, Hyperparameter Tuning) é o processo de realizar alterações nos parâmetros de um modelo com o intuíto de melhorar a sua performance.
Para isso podemos usar a classe GridSearchCV(), que fará uma série de tentativas combinando diferentes parâmetros definidos dentro de uma grade e implementando a Validação Cruzada (Cross Validation) para chegar até a melhor combinação.
Criando e Treinando Árvores de Decisão Tunadas
# Escolhe o Algoritmo
algo = DecisionTreeClassifier(random_state=1)
# Grade de parâmetros para combinar
parameters = {'max_depth': np.arange(1, 10),
'min_samples_leaf': [1, 2, 5, 7, 10, 15, 20],
'max_leaf_nodes': [2, 3, 5, 10],
'min_impurity_decrease': [0.001, 0.01, 0.1]
}
# Métrica usada para comparar as combinações de parâmetros
acc_scorer = metrics.make_scorer(metrics.recall_score)
# Roda a Grid Search
grid_obj = GridSearchCV(algo, parameters, scoring=acc_scorer, cv=5)
grid_obj = grid_obj.fit(X_train, y_train)
# Cria o modelo com a melhor combinação
arvore_d2 = grid_obj.best_estimator_
# Treina o modelo
arvore_d2.fit(X_train, y_train)

Métricas da Árvore de Decisão Tunada
arvore_d2_scores = performance_modelo_classificacao(arvore_d2)
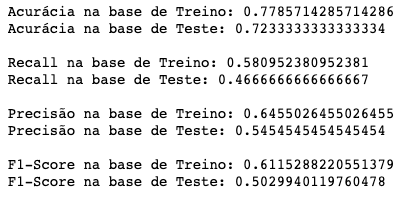
Você deve ter notado que todas essas tentativas de diferentes combinações de parâmetros demora um pouco para executar. Mas vejam só! Nossa profundidade ideal é de 7 níveis, com 10 nós folhas. O algoritmo escolheu essa melhor combinação dentro do espaço amostral que oferecemos pra ele.
Genial, né? E nosso modelo teve uma certa melhora. Vamos ver a Matriz de Confusão?
Matriz de Confusão para a Árvore de Decisão Tunada
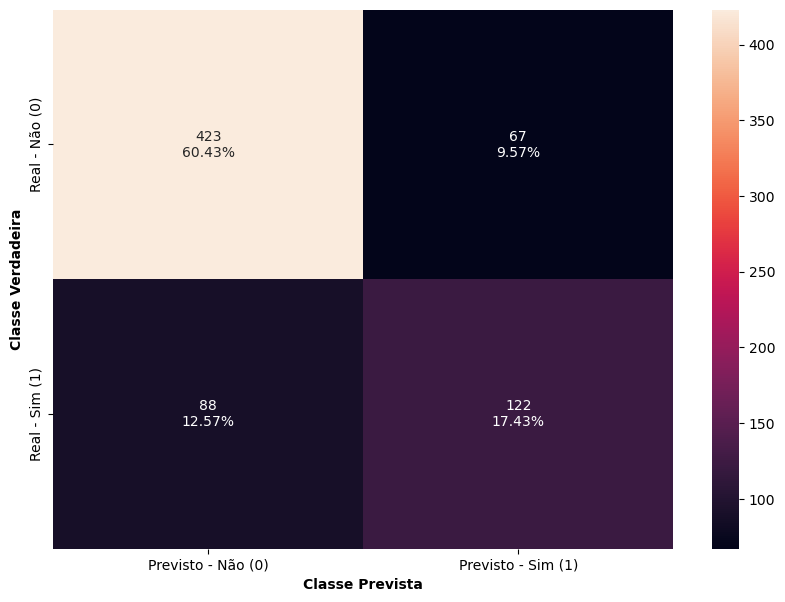
# Matriz de Confusão de treino
matriz_confusao(arvore_d2, X_train, y_train)
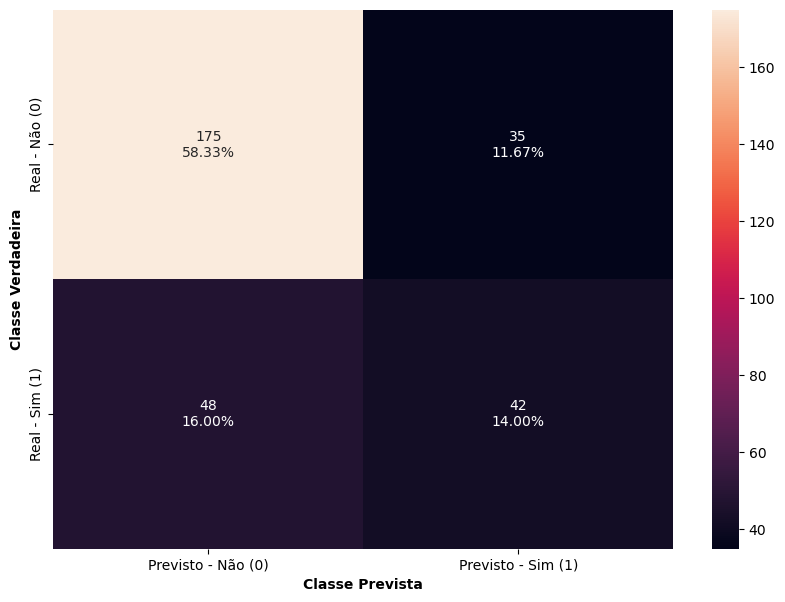
# Matriz de Confusão de teste
matriz_confusao(arvore_d2, X_test, y_test)
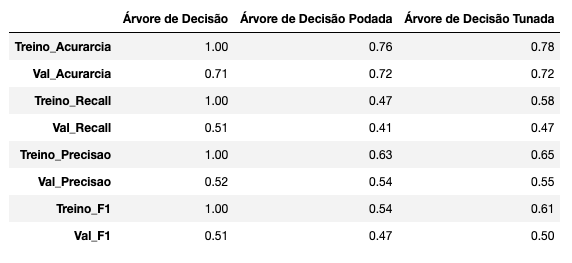
Comparando os Modelos de Árvores de Decisão
Agora vamos listar todos os modelos para compararmos as métricas de performance.
# Lista com todos os modelos
modelos = ['Árvore de Decisão',
'Árvore de Decisão Podada',
'Árvore de Decisão Tunada']
# Nomes das colunas
colunas = ['Treino_Acurarcia', 'Val_Acurarcia', 'Treino_Recall', 'Val_Recall',
'Treino_Precisao', 'Val_Precisao', 'Treino_F1', 'Val_F1']
# DataFrame com todos os modelos e seus respectivos scores
modelos_scores = pd.DataFrame([arvore_d_scores, arvore_d1_scores, arvore_d2_scores],
columns=colunas, index=modelos).apply(lambda x: round(x, 2))
modelos_scores.T
Conclusões
- Todos os nossos modelos estão ou apresentando Overfitting ou apresentando Underfitting até o momento.
- Não conseguimos encontrar ainda um algoritmo que apresente uma performance aceitável para o nosso objetivo com este projeto.
- Provavelmente precisaremos usar um algoritmo mais avançado para este problema. Possivelmente as Random Forests sejam uma boa escolha!
Caso tenha ficado com alguma dúvida, entre em contato conosco.
Colabore com a nossa comunidade trazendo conteúdo de qualidade em Português, seja conteúdo próprio ou traduzido. Iremos ficar muito felizes de receber material de vocês.
Para conhecer mais sobre nós e saber como colaborar, visite o post abaixo.
É sempre um prazer estar com vocês por aqui!


4 comentários
Cara…. muito conteúdo bom nesse canal… Já inclui na minha lista de favoritos… Além de apresentar um passo a passo esclarecedor com uma didática fantástica… Me ajudou muito para um trabalho de TCC que estou fazendo para uma Especialização em Ciência de Dados… Muito obrigado!
Poxa Márcio, muito obrigado! Ficamos extremamente felizes de saber que conseguimos colaborar de alguma forma. Qualquer coisa, só entrar em contato com a gente. E compartilha um pouco mais sobre o seu TCC com a gente! 🙂
Excelente conteúdo. Na teoria nós poderíamos implementar uma árvore que manipule dados categóricos sem precisar de encoders, mas o sklearn nos obriga a aplicar um encoder. Você acha que valeria a pena implementar um algoritmo baseado em árvore que não precise que as variáveis categóricas sejam codificadas ou o custo computacional é muito grande?
Ótima pergunta, Matheus! A Scikit-Learn nos obriga de fato a ter todas as variáveis como numéricas. Eu acredito que o custo computacional seja de fato um dos fatores mais importantes para isso, mas existem algumas outras coisas que podem ser levadas em consideração.
Um ponto importante, na minha opinião, no encoding das variáveis categóricas em numéricas é a noção de ordem. Algumas variáveis categóricas são ordinais, possuem uma ordem implícita (ex: faixa etária, como criança, jovem, adulto, idoso) e outras não deveriam ter ordem alguma, as variáveis não ordinais (ex: estado, cidade, estado civil, etc). O modelo não conseguiria capturar essa noção de ordem sem um encoding bem feito. Para as ordinais podemos transformar em números (1, 2, 3, 4, etc) e as não ordinais fazemos o One Hot Encoding.
Acredito também que manter tudo como numérico ajude o algoritmo a calcular a Impureza de Gini e o ganho em cada split. E facilite também na hora de nos retornar a importância das variáveis, pra nos dar um pouco de explicabilidade.