
Ao longo do post Árvores de Decisão: Algoritmos Baseados em Árvores falamos sobre estas árvores serem a base para outros algoritmos muito mais eficientes (e complexos). Se você não leu o post sobre Árvores de Decisão, recomendamos fortemente a leitura. Aqui iremos abordar um destes algoritmos, as Random Forests (traduzido livremente como “Florestas Aleatórias“).
As Random Forests, ou Florestas Aleatórias, como o próprio nome já diz, são formadas por uma série de árvores (de decisão) construídas de forma aleatória. São uma forma de modelo Ensemble.
O que são Modelos Ensemble?
Modelos Ensemble podem ser traduzidos de forma livre como “Modelos de Conjunto”. Esta tradução faz sentido pois as técnicas de Ensemble são justamente combinar múltiplos modelos individuais para tentar melhorar a performance preditiva sobre um determinado problema.
Podemos fazer uma analogia desta técnica a um princípio conhecido como A Sabedoria das Multidões, que estabelece que estimativas e respostas mais precisas podem ser obtidas combinando os julgamentos de diferentes avaliadores. Partindo desse pressuposto, estimamos que uma decisão tomada por um comitê de experts é mais assertiva do que a decisão tomada por um único expert individualmente.
“Muitos são mais inteligentes que alguns e a inteligência coletiva pode transformar os negócios, a economia, a sociedade e as nações.”
James Surowiecki: The Wisdom of Crowds (2004)
Estatisticamente falando, podemos fazer uma outra analogia. Vamos supor que temos diversos modelos fracos, com uma taxa de acerto um pouco melhor do que “cara ou coroa” (50/50). Suponhamos que nossos modelos acertam apenas 51% das vezes.

Vamos comparar esses modelos a uma moeda levemente viciada, que tem 51% de chances de cair “cara” e 49% de chances de cair “coroa”. Se jogarmos a moeda 1000 vezes, tenderemos a ter em torno de 510 “caras” e 490 “coroas”. Então “cara” é a classe majoritária.
Se fizermos os cálculos, veremos que a probabilidade de se obter “cara” como classe majoritária após mil jogadas da moeda vai ser próxima de 75%. E o quanto mais jogarmos a moeda, maior será a probabilidade – com 10 mil jogadas, a probabilidade sobe para próximo de 97%. Esse fenômeno é explicado pela Lei dos Grandes Números (LGN).
Classificação por Votação
Estes conceitos podem ser aplicados ao Machine Learning por meio de um sistema de votos.
Com modelos fracos, com taxas de acerto de apenas 51%, se pegarmos todas as predições e encontrarmos a classe majoritária (mais votada), conseguimos chegar aos 75% de acurácia!
Entretanto, para que o estudo de probabilidade e estatística se aplique corretamente, é necessário que todos os modelos sejam perfeitamente independentes uns dos outros, cometendo erros não correlacionados.
Se todos os modelos fracos forem treinados sobre os mesmos dados, muito provavelmente cometerão os mesmos tipos de erros. Isso irá levar a muitos votos na classe incorreta. A acurácia do modelo irá diminuir.
É neste ponto que a “Aleatórias” das “Florestas” se tornam extremamente importantes. Vamos ver o porquê e o como.
Random Forests, as Florestas Aleatórias
As Random Forests são um algoritmo de Ensemble que combina diferentes Árvores de Decisão. Podem ser usadas tanto para problemas de Classificação quanto de Regressão.
Como falamos no post Árvores de Decisão: Algoritmos Baseados em Árvores, as Árvores de Decisão normalmente trabalham dividindo os dados de acordo com o atributo que gera um maior ganho de informação. Ao final das árvores temos Nós Folhas (ou Nós Terminais) que nos retornam uma categoria (para problemas de Classificação) ou um número contínuo (para problemas de Regressão).
Um dos grandes problemas das Árvores de Decisão é que elas são muito sensíveis, e pequenas mudanças nos dados podem gerar grandes mudanças no modelo. Vamos ver um exemplo.
Sensibilidade das Árvores de Decisão
Para demonstrar o quanto as Árvores de Decisão são sensíveis a pequenas mudanças nos dados, vamos revisitar nosso problema de detecção de Spam. Como visto no post Árvores de Decisão: Algoritmos Baseados em Árvores, temos a seguinte base de treino.
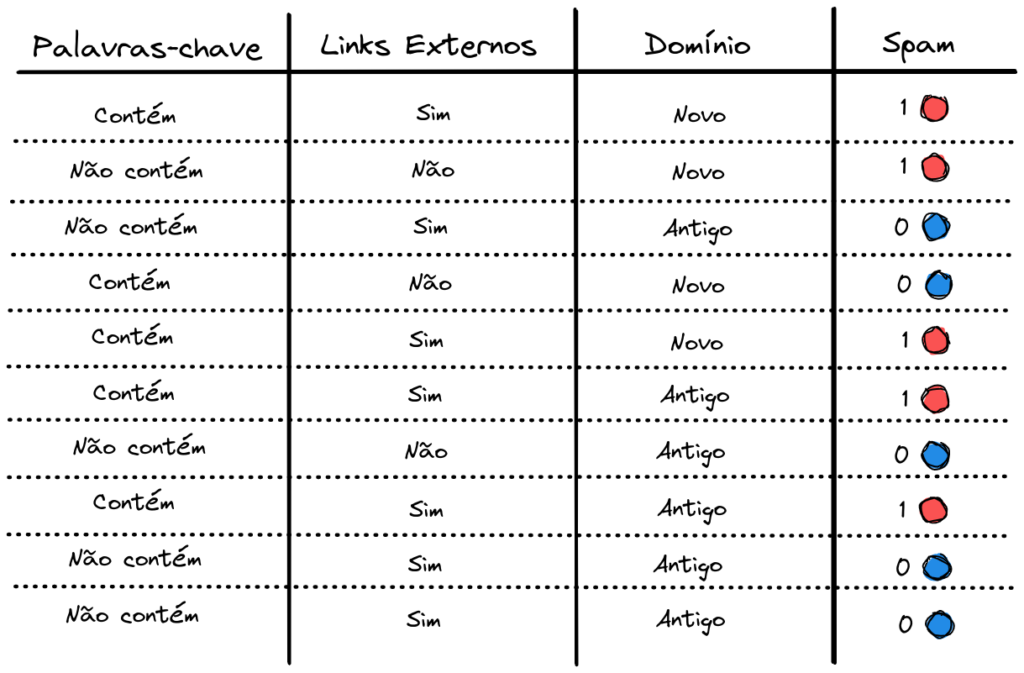
Nesta base de treino temos dados sobre 3 características dos e-mails: Palavras-chave (se o e-mail contém palavras-chave típicas de um spam); Links Externos (se tem links externos com tentativa de phishing); Domínio (se é um domínio novo, recém cadastrado, ou antigo).
Como variável alvo, rotulada, a ser prevista pelo modelo, temos a coluna Spam. O valor 1 indica que o e-mail é um spam e 0 indica que não é. Temos 5 exemplos de cada uma destas duas classes.
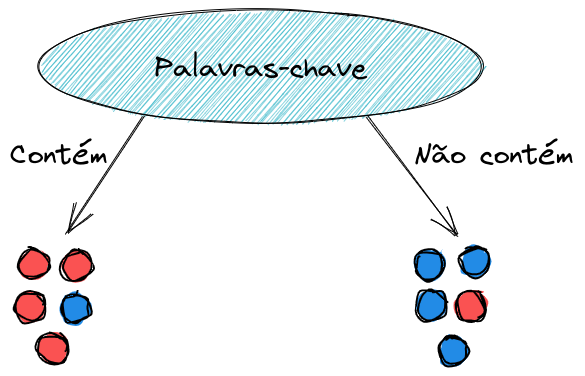
Dentro deste exemplo, observamos anteriormente que a melhor divisão a ser feita nos dados é sobre o atributo Palavras-chave. Da seguinte forma.
Entretanto, se alterarmos apenas um exemplo da base de dados, o cenário pode mudar totalmente. Vamos pegar o sexto exemplo da nossa base de dados. Alterar de um e-mail que contém palavras-chave, links externos e um domínio antigo para um e-mail que não contém palavras-chave, tem links externos e um domínio novo.
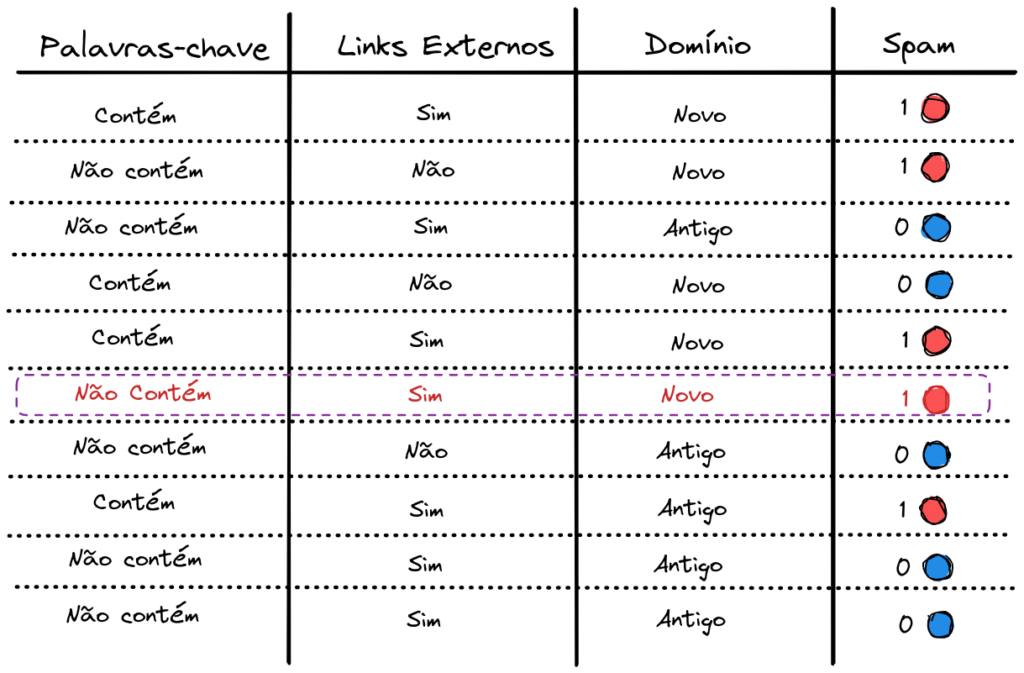
Com esta pequena alteração em um único exemplo, o atributo de maior ganho de informação passa a ser do Domínio. Faça você mesmo a verificação. Como resultado, os subconjuntos de dados que vão para esquerda e para a direita se tornam totalmente diferentes. Com isso, será construída uma Árvore de Decisão totalmente diferente da original.
Random Forests trazendo estabilidade
As Random Forests irão construir diversas árvores aleatórias – iremos ver mais à frente como – e isso irá trazer maior estabilidade para o modelo. Vamos ver um exemplo.
Recebemos um novo dado, com nosso modelo em produção. Este novo exemplo tem as seguintes características: contém Palavras-chave; não tem Links externos; Domínio novo. Sabemos que ele é Spam (classe 1). Vamos passar esse exemplo por uma Floresta Aleatória e ver o resultado.
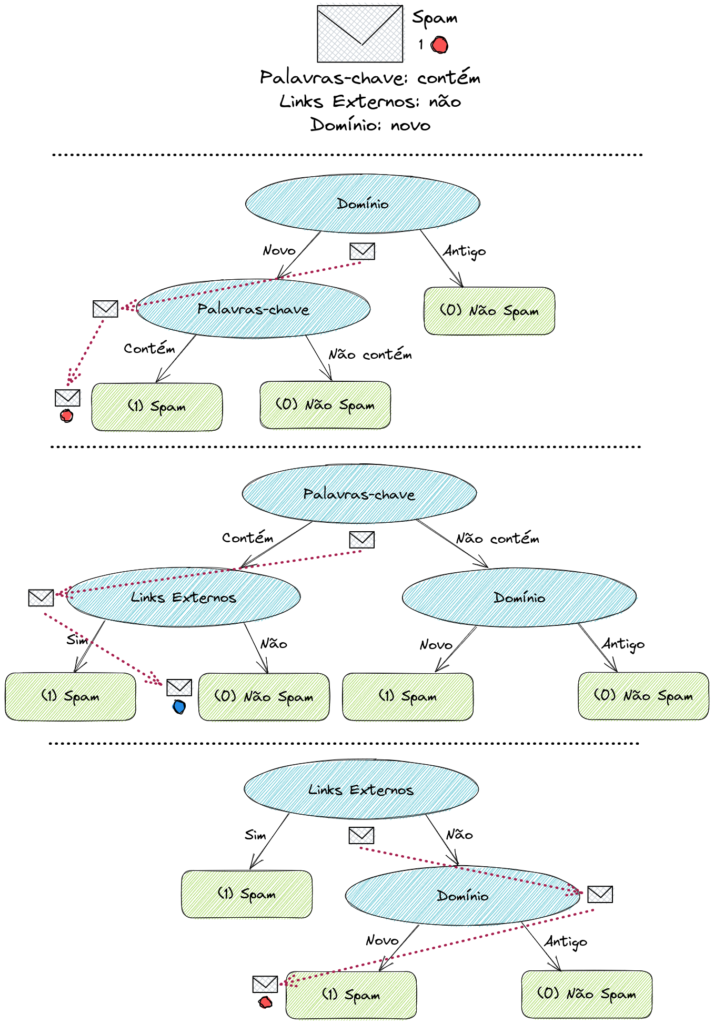
Após o exemplo passar pela Random Forest, as três Árvores de Decisão geradas aleatoriamente, temos três classificações finais. Por votação, pegamos a classe que aparece com mais frequência: este novo e-mail será classificado corretamente como Spam (classe 1)!
Apesar de termos modelos fracos, o conjunto deles nos fornece um modelo mais forte. Isso feito em larga escala irá seguir o mesmo teorema da Lei dos Grandes Números.
Um grande motivo para termos diversas árvores agrupadas em uma floresta é que isso torna o modelo menos sensível a o que uma única árvore está decidindo, porque haverão diversos outros votos a favor da classe correta (como é esperado em um modelo bem construído).
Mas como conseguimos construir diferentes – e plausíveis – Árvores de Decisão aleatoriamente para podermos avaliar os dados de forma diferente e fazer a votação no final?
Amostragem com Reposição
Mais tecnicamente, devemos chamar esta técnica de Amostragem Aleatória Simples com Reposição, ou do Inglês: Sampling with Replacement.
A forma mais fácil de entender a técnica é através de um exemplo. Você tem uma bolsa (bag) com bolinhas enumeradas de 1 a 10 e faz um sorteio de uma de cada vez. Após cada retirada você repõe a bolinha sorteada na bolsa. Repondo a amostra você não afeta a probabilidade de retirar qualquer elemento da população. No nosso exemplo, não afeta a probabilidade de retirar uma bolinha da urna, as chances serão iguais para sempre.
Esta técnica irá nos ajudar a manter os modelos (Árvores de Decisão) diferentes uns dos outros, e independentes. Lembra que para funcionar precisamos de modelos independentes?
A cada modelo (também chamado de Estimator) o algoritmo irá selecionar aleatoriamente um número \(m\) exemplos da base de dados. Sobre este subconjunto de dados irá construir uma Árvore de Decisão. Este processo irá se repetir por um número \(E\) de vezes, que é o número de Estimators (modelos, ou árvores) da nossa Random Forest.
Desta forma teremos \(E\) diferentes Árvores de Decisão construídas sobre diferentes subconjuntos de dados com \(m\) exemplos cada.
O processo geral seria da seguinte forma.

Vale a pena ressaltar que algumas amostras (exemplos) podem aparecer mais de uma vez em um dos \(E\) modelos. Ao mesmo tempo, algumas amostras podem não aparecer em nenhum dos modelos construídos.
Podemos provar matematicamente que é garantido que aproximadamente 63% das amostras serão usadas. Mas este cálculo ficará para outro dia.
Aumentando a Aleatoriedade
Para aumentar a aleatoriedade – e assim a independência – dos modelos, podemos além de fazer uma amostragem dos exemplos (linhas), podemos também fazer uma amostragem dos atributos (colunas).
No nosso exemplo de Spam temos apenas 3 colunas. Em problemas do mundo real, muitas vezes teremos dezenas, dúzias, ou até mesmo centenas. Definimos a quantidade de atributos (colunas) como a variável \(n\), o total de atributos da base de treino.
O algoritmo de Random Forest poderá fazer uma amostragem selecionando apenas um subconjunto \(k\) de atributos (onde \(k < n\)) e permitir que a Árvore de Decisão seja construída apenas sobre esse subconjunto de atributos.
Um valor interessante para o subconjunto de atributos \(k\) é a raiz quadrada do total de atributos \(n\) da base de treino ( \(k = \sqrt{n}\) ), quando \(n\) é um número alto de atributos.
Processo de treino das Random Forests
Podemos resumir os passos do algoritmo de Random Forests da seguinte forma.
- Um subconjunto de dados é retirado da base de treino através da Amostragem com Reposição.
- Uma quantidade \(k\) de atributos é selecionada aleatoriamente de um total de \(n\) atributos da base de treino.
- O subconjunto de dados é usado para construir uma Árvore de Decisão única, usando apenas os \(k\) atributos para suas decisões.
- Cada árvore cresce ao máximo – ou até um tamanho pré-definido.
- O processo se repete até termos construído o número \(E\) de Estimators (modelos de Árvores de Decisão).
Após termos todos os modelos/estimators treinados, novos dados a serem previstos passarão por todas as Árvores de Decisão e cada uma classificará de acordo com seu treino individual e independente.
Ao final iremos ver por votação qual a classe mais prevista, e a classe mais votada será retornada como predição final.
Random Forests para Regressão
O processo é exatamente o mesmo. Porém ao final, ao invés de checarmos a classe mais votada (Moda) o modelo irá ver qual a Média das predições de cada Árvore de Decisão.
Vale ressaltar que o processo de treino de Árvores de Decisão para Regressão (chamas de Árvores de Regressão) é muito similar ao treino das árvores para Classificação. Em breve falaremos aqui no BRAINS em mais detalhes sobre como elas funcionam.
Conclusão
As Random Forests (Florestas Aleatórias) são muito mais robustas, estáveis e confiáveis do que Árvores de Decisão únicas. O processo de amostragem com reposição força o algoritmo a se adaptar a diversas mudanças singelas nos dados usados para treinar cada uma das árvores. Isso resolve uma das maiores fraquezas das nossas árvores.
Algumas vantagens são que o algoritmo é flexível para ambos problemas, de Classificação e Regressão. Também trabalha bem com variáveis categóricas e contínuas. Não tende ao Overfitting e é altamente estável, pois na sua própria construção o algoritmo já generaliza bem os dados. O modelo costuma lidar muito bem com uma alta dimensionalidade dos atributos, pois apenas uma fração dos atributos é selecionada para cada árvore. Entre outras vantagens.
Algumas desvantagens são que o algoritmo requer bastante poder computacional, pois muitos recursos são necessários para se treinar diversas Árvores de Decisão e combinar as suas saídas. Além disso, nós perdemos a interpretabilidade do modelo simples de Árvore de Decisão. Com centenas ou milhares de árvores, fica muito complexo de um humano rastrear todas as decisões tomadas.
Nos próximos posts veremos como construir em Python Árvores de Decisão e Random Forests.
Se você ficou com alguma dúvida, já sabe, deixe comentários.
Todos são bem-vindos a colaborar com a nossa comunidade. Esperamos ter ao nosso lado estudantes dos mais iniciantes aos mais avançados. Para saber mais sobre como colaborar, visite o nosso post BRAINS – Brazilian AI Networks.


1 comentário