
Tipos de sistemas de Machine Learning
Existem inúmeros tipos diferentes de sistemas de Machine Learning e podemos dividi-los em diferentes categorias de acordo com alguns critérios, como o algoritmo em uso (regressões, algoritmos baseados em árvores, redes neurais, etc), se eles podem ou não aprender incrementalmente em tempo real (aprendizado Online versus Batch), mas vamos nos ater aqui a uma das categorizações mais relevantes e usadas: a forma como o modelo aprende.
Para classificar quanto ao aprendizado, vamos classificar os modelos de acordo com a quantidade e o tipo de supervisão necessária durante o treinamento. Existem diversas categorias, mas vamos discutir as principais.
Machine Learning: Aprendizado Supervisionado
Provavelmente a maior parte do valor financeiro gerado por Machine Learning hoje é através de um tipo de modelo, chamado de Aprendizado Supervisionado (ou Supervised Learning). Este tipo de modelo normalmente se refere a algoritmos que aprendem a encontrar padrões que mapeiem uma entrada (input) X a uma saída (output) Y.

A característica chave do Aprendizado Supervisionado é que nós fornecemos ao algoritmo exemplos para aprender, fornecemos a experiência E, como definimos anteriormente. E nesses exemplos nós temos as respostas corretas para nosso diagrama da abordagem de ML. Por “respostas corretas” queremos dizer a saída real Y, verdadeira, para dado um conjunto de valores, ou características, na entrada X.
Ao ver diversos exemplos de características de entrada que resultam em diferentes saídas, o modelo irá começar a buscar e entender padrões nos dados. Uma vez que padrões tenham sido encontrados, o modelo formula o seu conjunto de regras (fórmula matemática complexa) para predizer qual a saída Y para um conjunto de dados, ou características, de entrada X ainda não visto pelo modelo.
Para um exemplo didático, vamos voltar no nosso primeiro exemplo, o detector de spam. A entrada X vai ser o e-mail em si, mais precisamente todos os dados do e-mail: remetente, título, corpo do e-mail, se tem anexo ou não, destinatários, etc. A saída Y vai ser se o e-mail é spam ou não é spam, ou seja, vamos classificar o e-mail nestas duas classes.
Antes de começar a treinar esse modelo de Machine Learning, nós precisamos formar uma base de treino, que contenha inúmeros exemplos de ambas as classes, spam e não spam. Com isso nós vamos alimentar o nosso modelo de ML com as entradas (dados dos e-mails) e com as saídas (o rótulo de cada e-mail, se é ou não spam). Deixamos o algoritmo fazer o seu trabalho, e ele vai gerar as suas regras para detecção.
Esta é uma tarefa do tipo Classificação, ou para ser mais exato uma Classificação Binária, pois queremos saber a qual das duas classes a entrada pertence.

O processo de Aprendizado Supervisionado é justamente o que acabamos de fazer. E após este modelo ter acumulado experiência E o suficiente através dos exemplos fornecidos, ele vai ter uma performance P na tarefa T de classificar spam, e quando um novo e-mail chegar, este modelo deve conseguir classificá-lo corretamente. Vale ressaltar que o quão bom esse modelo vai ser, vai depender principalmente da experiência que ele tiver, ou seja, da quantidade e qualidade dos exemplos fornecidos.
As tarefas de Classificação podem ser Binárias, como no exemplo de classificação de spam e da nossa máquina inteligente, que segrega produtos bons dos produtos falhos na linha de produção, e podem ser também Multi-classes, como por exemplo um modelo de reconhecimento facial que pode reconhecer inúmeras pessoas, onde cada indivíduo representa uma classe.
Nós explicamos melhor um algoritmo de Classificação no post Modelos de Classificação: Regressão Logística. Em breve traremos mais algoritmos e também implementações práticas, com código em Python.
Nós temos uma outra tarefa muito comum no Aprendizado Supervisionado que são as tarefas de Regressão, que buscam encontrar valores exatos. Ao invés de tentar classificar uma entrada X dentro de uma classe (verdadeiro ou falso, sim ou não, A ou B), nós queremos encontrar um valor contínuo para a saída Y desse conjunto de dados. Um exemplo clássico é tentar prever o valor de um imóvel.
Podemos usar diversas características (dados) do imóvel como entrada X e tentar prever qual o seu valor aceito pelo mercado atual, que é nossa variável alvo, a nossa saída Y. Para isso, precisaríamos novamente de uma base de treino, com exemplos contendo as diversas características dos imóveis e o valor de cada um.
Novamente o algoritmo de Machine Learning irá buscar padrões nos dados e nos retornar um conjunto de regras, ou sua fórmula matemática, para calcular o padrão encontrado. Para simplificar a visualização, vamos levar em consideração simplesmente a área do imóvel (em m²) influenciando no seu valor.

Um dos algoritmos possíveis para este problema seria o de Regressão Linear, que tenta encontrar uma reta que represente a relação entre a área do imóvel e o seu valor de mercado. O algoritmo então analisa todos os exemplos (pontos azuis) e retorna para a gente o seu conjunto de regras, ou a fórmula linear da reta mais eficiente para este caso.

Uma vez tendo suas regras definidas – sua fórmula especificada – fica fácil para o modelo predizer o valor de um novo imóvel, fora da sua base de treino. Basta aplicar a fórmula e ver que determinada área no eixo X leva até determinado valor no eixo Y.

Não se preocupe por enquanto se você não entendeu como exatamente os algoritmos funcionam. Porém, caso queira entender melhor os algoritmos de Regressão, pode ler nosso post Modelos de Regressão: Regressão Linear. E para começar a desenvolver regressões lineares você mesmo, pode ver o Prática: Regressão Linear, com código em Python.
Por hora, basta compreender que no Aprendizado Supervisionado nós temos exemplos rotulados, ou seja, para cada entrada X nós já temos descrito qual a saída Y real, nós já temos as respostas para alguns exemplos da pergunta que queremos responder.
É importante também entender que em tarefas de Classificação nós rotulamos determinada entrada entre duas ou mais categorias (bom ou ruim, verdadeiro ou falso, sim ou não, etc) e em tarefas de Regressão queremos um valor exato e contínuo (valor de um imóvel, faturamento do próximo mês, melhor preço de parcela para um empréstimo, etc).
Machine Learning: Aprendizado Não-Supervisionado
Para o Aprendizado Não-Supervisionado (ou Unsupervised Learning) nós já podemos imaginar que nossos dados não são rotulados, ou seja, nós não temos uma saída Y conhecida para nossas entradas X. O sistema tenta aprender sem ter um professor.
Por exemplo, vamos supor que nós tenhamos muitos dados sobre os visitantes aqui do BRAINS.dev (não, nós não temos haha) e nós queiramos entender um pouco mais sobre eles e agrupá-los em diferentes grupos. Nós podemos rodar um algoritmo chamado de Clustering, que faz esse agrupamento e segrega os nossos visitantes similares. E faz isso sem a nossa ajuda, sem precisar de exemplos claros.
Note que este tipo de algoritmo ainda assim busca padrões nos dados, mas desta vez ao invés de tentar predizer um valor específico ou falar que o visitante se encaixa na categoria A, B ou C, ele vai simplesmente agrupar visitantes similares baseado nos padrões encontrados (que nem sempre irão fazer sentido à primeira vista para nós humanos).
Vamos supor que 40% dos nossos visitantes são estudantes de tecnologia, que estão na faculdade e querem trabalhar com Inteligência Artificial e Machine Learning, e esses visitantes são mais jovens, acessam o site final da tarde depois das aulas e buscam um conteúdo mais acadêmico. Enquanto isso, 25% dos visitantes são adultos, já profissionais, que estão buscando migrar de área, estes costumam acessar o site à noite e aos finais de semana, e buscam conteúdos mais práticos, mão na massa. E temos outros perfis de visitantes com características diferentes.
Nós poderíamos até visualizar os nossos visitantes em gráficos de duas ou três dimensões (seres humanos não conseguem visualizar além de 3D, mas há algoritmos que lidam com centenas de dimensões), de acordo com suas características.
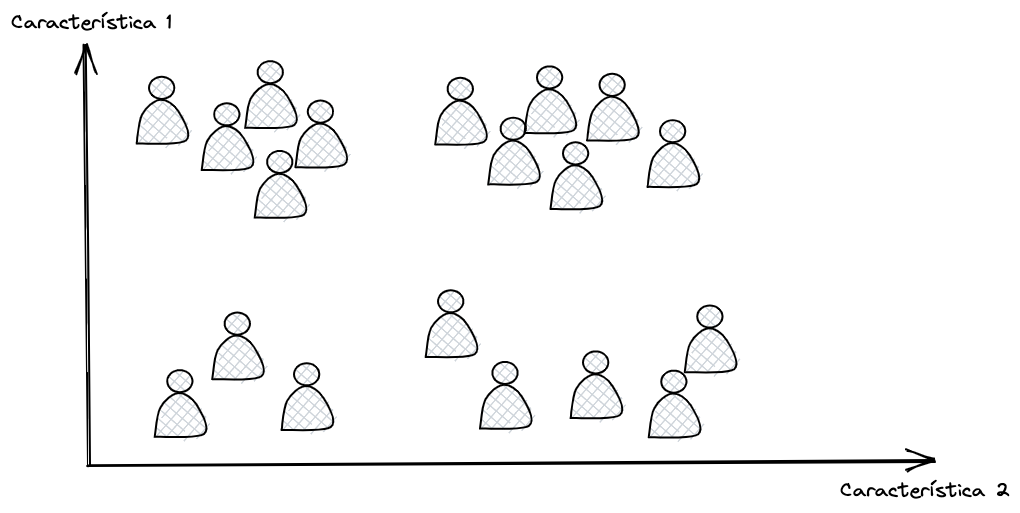
O algoritmo de Clustering irá identificar os diferentes grupos (ou clusters) presentes nos dados dos nossos visitantes.
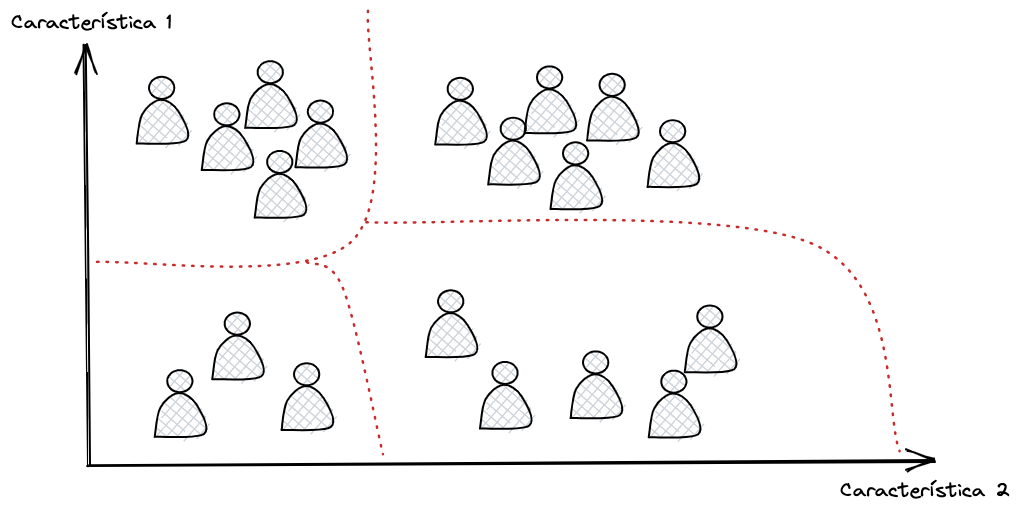
Se usarmos Clusters Hierárquicos, podemos dividir ainda cada grupo em seu subgrupo. Isso pode nos ajudar a segmentar nossos visitantes e direcionar posts para cada perfil de leitores.
Agora imagine o poder disso se aplicado a clientes de uma grande empresa de varejo, aplicado ao marketing, vendas de produtos e serviços. Esse tipo de algoritmo pode fornecer informações valiosíssimas sobre clientes e qualquer outro tipo de dados que possam ser agrupados para uma análise mais precisa e segmentada.
Um outro exemplo de algoritmos de Aprendizagem Não-Supervisionada são os de Visualização de Dados. Como acabamos de falar, o ser humano não consegue visualizar nada acima de três dimensões, e na maioria esmagadora dos casos iremos nos deparar com dados com muito mais dimensões (características) que isso. Algoritmos de Visualização podem nos ajudar a trazer dados de mais dimensões para apenas duas ou três e permitir que sejam visualizados graficamente.
Estes algoritmos tentam preservar o máximo da estrutura original dos dados, como pondo os pontos em grupos separados no espaço amostral para permitir uma melhor visualização. Assim, nós podemos enxergar e entender melhor como os dados estão organizados e encontrar padrões ocultos.
Uma outra tarefa similar é a de Redução de Dimensionalidade, a qual tenta simplificar os dados sem perder muita informação. A ideia é tentar juntar diversas características correlacionadas em uma só. Por exemplo, a quilometragem de um carro pode estar fortemente correlacionada com o seu ano de fabricação, então sem supervisão, o algoritmo de Redução de Dimensionalidade vai calcular essa relação e unir as duas características em uma só que represente o “desgaste” do carro.
Temos também algoritmos de Detecção de Anomalias, que são extremamente importantes. São usados por exemplo para identificar fraudes no sistema financeiro, transações de cartão de crédito fora do comum. Se você passa o seu cartão de crédito hoje às 8:17h na padaria próximo da sua casa e às 9:02h o seu cartão é passado em uma compra na Índia, um algoritmo de Detecção de Anomalias irá perceber que há algo de muito errado com isso e bloquear esta segunda compra.
Detecção de Anomalias também é bastante usado em monitoramentos de sistemas da informação e servidores. Praticamente todo sistema online possui um padrão de acessos e uma sazonalidade ao longo do dia, mês e ano. Então se o seu sistema do nada tem um número imenso de acessos – e você não é um e-commerce na Black Friday – então possivelmente seu sistema está sofrendo um ataque.
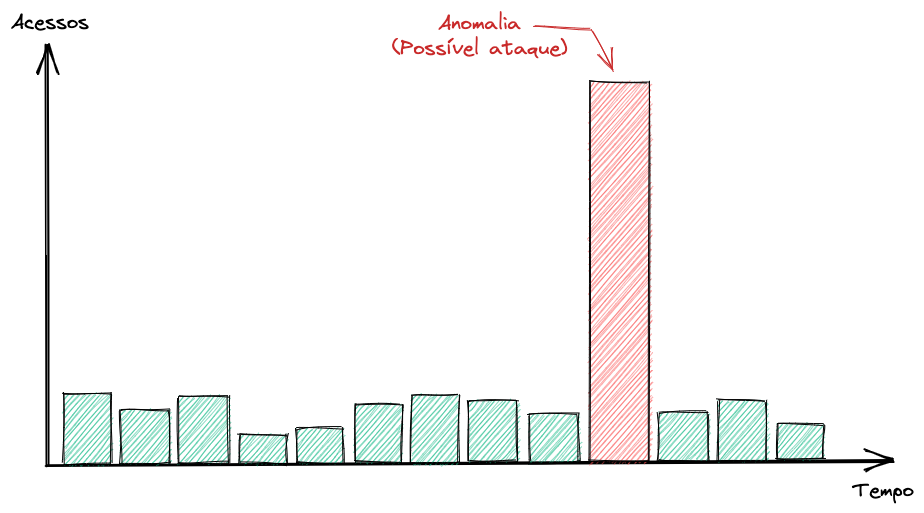
No caso acima, o algoritmo detectaria uma anomalia, um possível ataque DDoS (Negação de Serviço Distribuído).
Conclusão
Como dito, este tema é super extenso e pode ficar bastante complexo. Esperamos ter trazido uma introdução um pouco mais suave para que vocês comecem a sentir o gostinho desse tema profundamente fascinante que é o Aprendizado de Máquina.
Novamente, não se preocupe se você não entendeu exatamente o que uma Regressão Linear faz, como uma Classificação funciona por baixo dos panos ou não faz ideia de como implementar um modelo de Detecção de Anomalias. A ideia foi apenas degustar e se acostumar com alguns dos termos. Em breve teremos outros posts aqui no BRAINS explicando cada um desses algoritmos em detalhes.
É importante ressaltar que há outros tipos de sistema de Machine Learning quanto ao aprendizado, como o Aprendizado Semi-Supervisionado (Semi-Supervised Learning) e o Aprendizado por Reforço (Reinforcement Learning). Esses são hoje um pouco menos comuns e também vão ser tema de um post futuro.
Caso tenha ficado com dúvidas e queira conversar sobre, deixa um comentário para a gente. Vamos adorar bater um papo sobre ML! Se você domina alguns desses algoritmos e quer colaborar com a nossa comunidade escrevendo para o BRAINS, entre em contato conosco também. E se você ainda não domina, mas está estudando (provavelmente consumindo conteúdo em Inglês), você também pode colaborar com nossa comunidade traduzindo conteúdo ou gerando o seu próprio em Português enquanto estuda.
De toda forma, não deixe de conhecer mais sobre o BRAINS – Brazilian AI Networks, a comunidade de estudantes que tem como objetivo trazer conteúdo de qualidade sobre AI, Dados e ML para Brasileiros, em Português. 🇧🇷
Nos vemos nos próximos posts!


7 comentários